
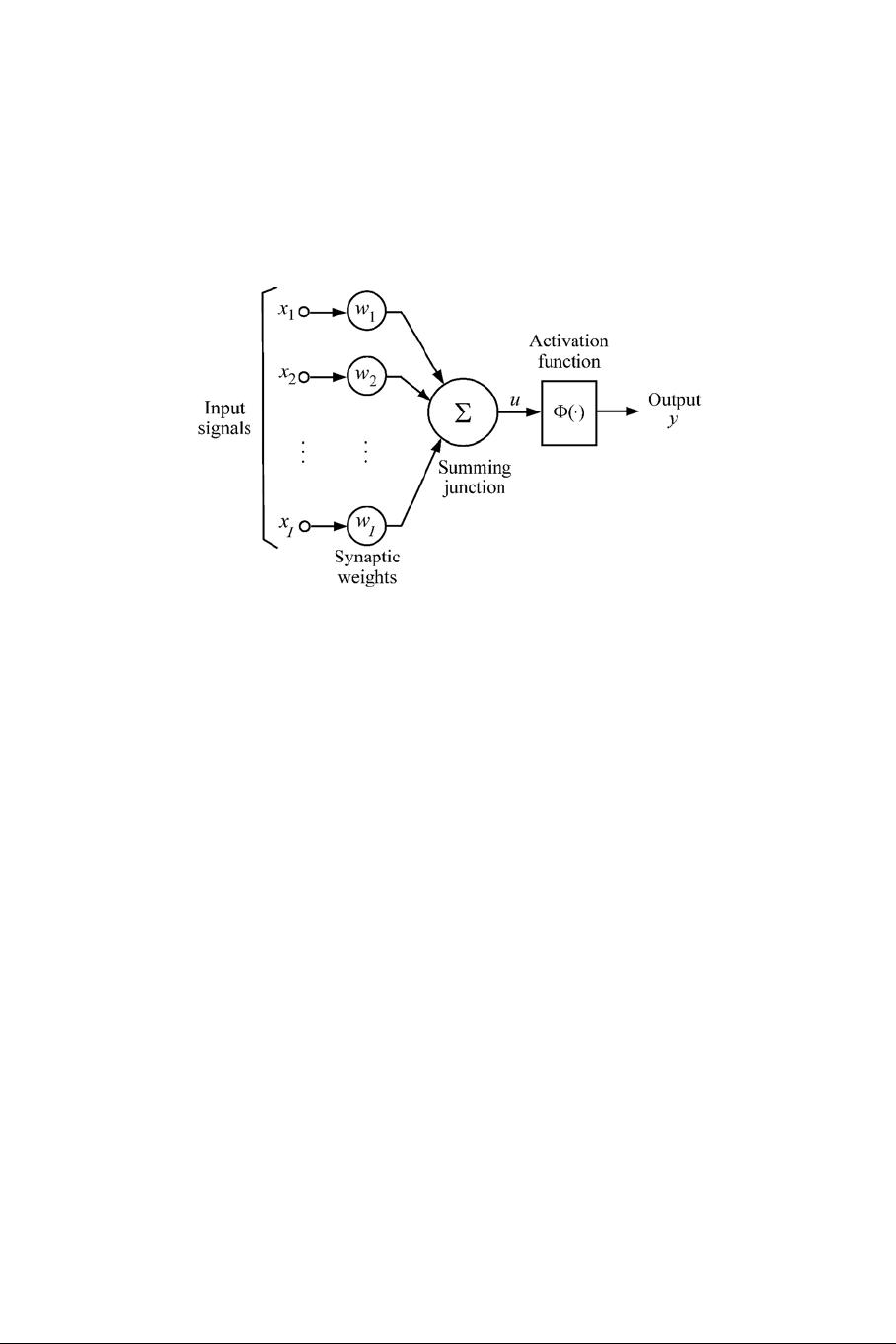
4 FPGA Neurocomputers
represented by a set of weights, here denoted by w =(w
1
,w
2
,...w
I
)
T
; and
(3) an activation function Φ that relates the total synaptic input to the output
(activation) of the neuron. The main components of an artificial neuron is
illustrated in Figure 1.
Figure 1: The basic components of an artificial neuron
The total synaptic input, u, to the neuron is given by the inner product of the
input and weight vectors:
u =
I
i=1
w
i
x
i
(1.1)
where we assume that the threshold of the activation is incorporated in the
weight vector. The output activation, y,isgivenby
y =Φ(u) (1.2)
where Φ denotes the activation function of the neuron. Consequently, the com-
putation of the inner-products is one of the most important arithmetic opera-
tions to be carried out for a hardware implementation of a neural network. This
means not just the individual multiplications and additions, but also the alterna-
tion of successive multiplications and additions — in other words, a sequence
of multiply-add (also commonly known as multiply-accumulate or MAC) op-
erations. We shall see that current FPGA devices are particularly well-suited
to such computations.
The total synaptic input is transformed to the output via the non-linear acti-
vation function. Commonly employed activation functions for neurons are



剩余364页未读,继续阅读
















