
Overall
usefulness
Coherence Factual
accuracy
0
10
20
30
40
50
60
70
GPT-Browser preferred (%)
760M best-of-4 13B best-of-16 175B best-of-64
Overall
usefulness
Coherence Factual
accuracy
0
10
20
30
40
50
60
70
WebGPT preferred (%)
(a) WebGPT vs. human demonstrations.
Overall
usefulness
Coherence Factual
accuracy
0
10
20
30
40
50
60
70
WebGPT preferred (%)
(b) WebGPT vs. ELI5 reference answers.
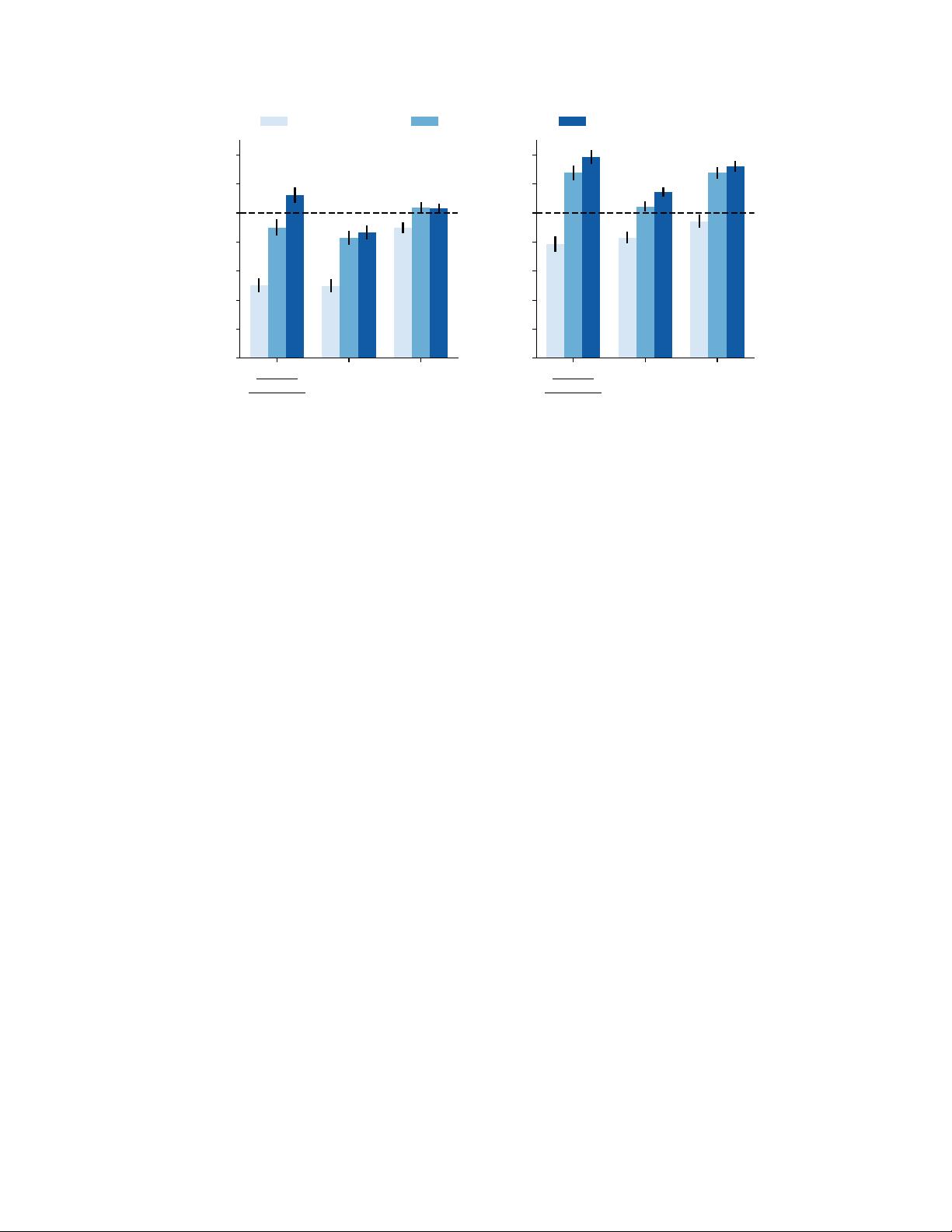
Figure 2: Human evaluations on ELI5 comparing against (a) demonstrations collected using our web
browser, (b) the highest-voted answer for each question. The amount of rejection sampling (the
n
in
best-of-
n
) was chosen to be compute-efficient (see Figure 8). Error bars represent
±1
standard error.
Although the evaluations against the ELI5 reference answers are useful for comparing to prior work,
we believe that the evaluations against human demonstrations are more meaningful, for several
reasons:
• Fact-checking.
It is difficult to assess the factual accuracy of answers without references:
even with the help of a search engine, expertise is often required. However, WebGPT and
human demonstrators provide answers with references.
• Objectivity.
The use of minimal instructions makes it harder to know what criteria are
being used to choose one answer over another. Our more detailed instructions enable more
interpretable and consistent comparisons.
• Blinding.
Even with citations and references stripped, WebGPT composes answers that
are different in style to Reddit answers, making the comparisons less blinded. In contrast,
WebGPT and human demonstrators compose answers in similar styles. Additionally, some
ELI5 answers contained links, which we instructed labelers not to follow, and this could
have biased labelers against those answers.
• Answer intent.
People ask questions on ELI5 to obtain original, simplified explanations
rather than answers that can already be found on the web, but these were not criteria we
wanted answers to be judged on. Moreover, many ELI5 questions only ever get a small
number of low-effort answers. With human demonstrations, it is easier to ensure that the
desired intent and level of effort are used consistently.
4.2 TruthfulQA
To further probe the abilities of WebGPT, we evaluated WebGPT on TruthfulQA [Lin et al., 2021], an
adversarially-constructed dataset of short-form questions. TruthfulQA questions are crafted such that
they would be answered falsely by some humans due to a false belief or misconception. Answers are
scored on both truthfulness and informativeness, which trade off against one another (for example, “I
have no comment” is considered truthful but not informative).
We evaluated both the base GPT-3 models used by WebGPT and the WebGPT models themselves
on TruthfulQA. For GPT-3, we used both the “QA prompt” and the “helpful prompt” from Lin
et al. [2021], and used the automated metric, since this closely tracks human evaluation on answers
produced by the GPT-3 model family. For WebGPT, we used human evaluation, since WebGPT’s
answers are out-of-distribution for the automated metric. TruthfulQA is a short-form dataset, so
6
剩余31页未读,继续阅读

2013crazy
- 粉丝: 831
- 资源: 2334
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


