Caffe入门教程:CIFAR-10数据集实战与CNN模型构建
需积分: 9 103 浏览量
更新于2024-07-20
收藏 2.48MB PDF 举报
Caffe学习笔记是一份详尽的教程,主要介绍了如何在Caffe(一个流行的深度学习框架)上进行CIFAR-10数据集的训练和学习。CIFAR-10是一个包含60000张32x32彩色图像,共10类的常用计算机视觉数据集,其中50000张用于训练,10000张用于测试。
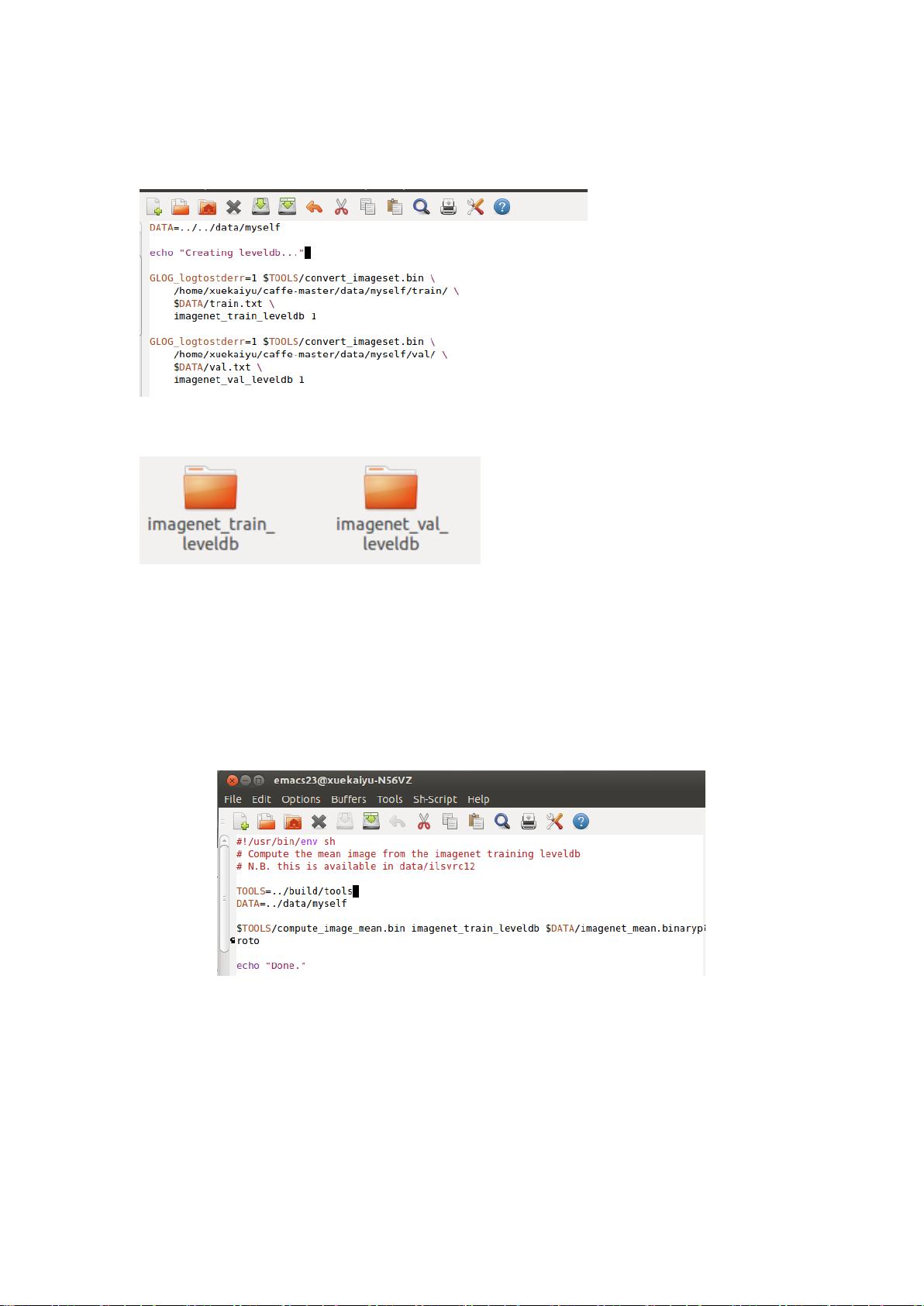
首先,学习者需要将CIFAR-10数据集下载到Caffe的安装目录下,并通过`get_cifar10.sh`和`create_cifar10.sh`脚本来创建相应的数据库文件,如`cifar10-leveldb`以及图像均值文件`mean.binaryproto`。这些文件对于预处理和模型训练至关重要。
Caffe模型的基础结构包括卷积层(convolutional layers)、池化层(pooling layers)、非线性变换层(如ReLU或sigmoid),以及顶层的局部响应归一化(Local Response Normalization)和全连接层,最后是线性分类器。模型配置文件,如`cifar10_quick_train.prototxt`,定义了网络结构和参数,允许用户根据需求进行定制。
训练和测试阶段相对简单,只需要准备两个关键的配置文件:`cifar10_quick_solver.prototxt`用于设置训练参数,而`train_quick.sh`脚本则调用`train_net.bin`工具进行训练,同时显示出实时的训练信息,例如网络层的创建和连接情况。例如,训练过程中会看到类似于"CreatingLayer conv1"、"conv1 <- data"等输出,表明网络正在逐步构建和连接各个层。
这份学习笔记提供了一个从头开始搭建和训练Caffe模型的具体步骤,非常适合初学者理解Caffe的基本工作流程,以及如何使用它来解决实际的图像分类问题。通过跟随教程中的例子,读者能够掌握如何设置数据、配置模型,以及如何观察和解读训练过程中的输出,从而加深对深度学习框架的理解。
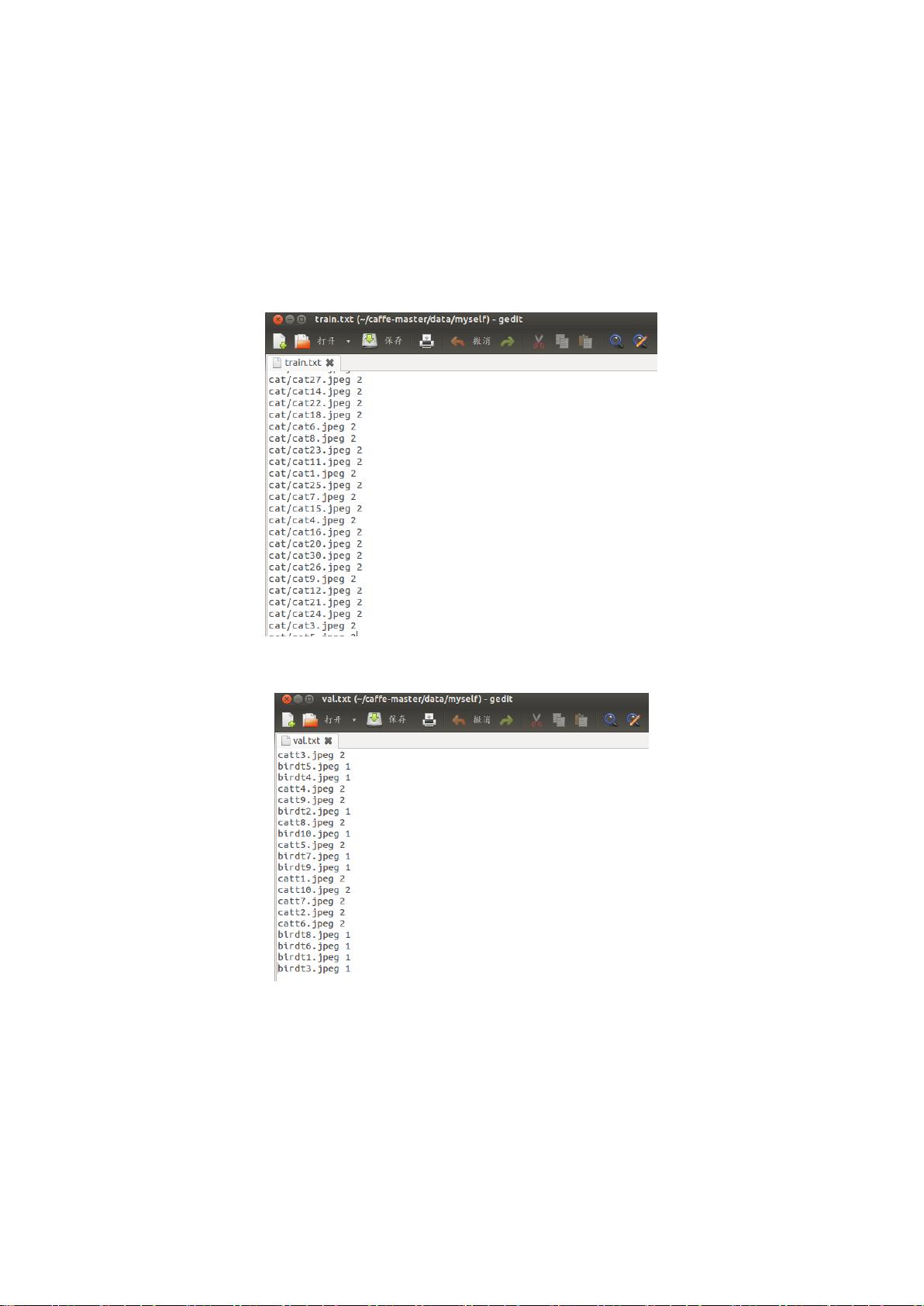
培训和测试的输入是用 train.txt 和 val.txt 描述的,这些文档列出所有文件和他们的标签。
注意,我们分类的名字是 ASCII 码的顺序,即 0-999,对应的分类名和数字的映射在
synset_words.txt(自己写)中。
运行以下指令:
find -name *.jpeg |cut -d '/' -f2-3 > train.txt
注意路径
然后,因为样本数比较少,可以自行手动做分类标签。在 train.txt 的每个照片后用 0-999
分类。当样本过多,就自己编写指令批量处理。
同理,获得 val.txt
Test.txt 和 val.txt 一样,不过后面不能标签,全部设置成 0。
我们还需要把图片的大小变成 256X256,但在一个集群环境,可以不明确的进行,使用
Mapreduce 就可以了,像杨青就是这样做的。如果我们希望更简单,用下面的命令:
for name in /path/to/imagenet/val/*.JPEG; do
convert -resize 256x256\! $name $name
done
我做成了 sh,方便以后使用。
剩余35页未读,继续阅读
2018-07-25 上传
2022-08-08 上传
2017-11-08 上传
2018-06-25 上传
2016-03-20 上传

_DeMofCJ
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
