搭建5台服务器Hadoop集群实战:运行大规模Wordcount
需积分: 3 168 浏览量
更新于2024-09-15
收藏 24KB DOCX 举报
"Hadoop分布式集群配置指南"
Hadoop是一个开源的分布式计算框架,它允许在廉价硬件上处理和存储大规模数据。这个集群配置指南详细阐述了如何在一个由5台计算机构成的环境中搭建和配置Hadoop集群,以支持处理超过50GB的大数据任务,如WordCount应用。
首先,集群架构由一个Master节点和四个Slave节点组成。Master节点负责协调和管理整个集群的工作,而Slave节点则执行实际的数据处理任务。在这样的设置中,Master通常包括NameNode(负责文件系统的元数据管理)和JobTracker(调度任务和资源管理),而Slave节点包含DataNode(存储数据)和TaskTracker(执行MapReduce任务)。
在配置Hadoop集群之前,必须确保所有节点都安装了兼容的操作系统和软件。本指南选择了Red Hat Enterprise Linux Server 6.3作为操作系统,以及Hadoop-1.0.3和JDK-6u34-linux-x64作为主要的软件组件。JDK是Java Development Kit的简称,它是运行和开发Java应用程序的基础,对于Hadoop这样的Java编写系统至关重要。
安装JDK的步骤包括:
1. 给jdk-6u34-linux-x64.bin文件赋予执行权限。
2. 运行该文件进行安装。
3. 修改/etc/profile文件,设置JAVA_HOME、JRE_HOME和CLASSPATH环境变量,指向JDK的安装路径。
接着,安装Hadoop的过程包括:
1. 解压缩hadoop-1.0.3.tar.gz文件到指定目录。
2. 在/etc/profile文件中添加HADOOP_HOME环境变量,将PATH变量扩展以包含Hadoop的bin目录。
配置Hadoop环境涉及以下几个关键步骤:
1. 在hadoop-env.sh文件中,取消JAVA_HOME的注释,并设置正确的JDK路径。
2. 在core-site.xml文件中,定义Hadoop的基本配置,例如命名空间的默认值和文件系统的URI。虽然示例没有给出完整的core-site.xml内容,但通常会包含如`fs.defaultFS`这样的属性来指定HDFS的根目录。
此外,还需要配置Hadoop的其他两个核心文件:hdfs-site.xml用于HDFS的参数设置,mapred-site.xml用于MapReduce框架的配置。例如,可能需要指定DataNode的数量、副本因子、NameNode的地址等。
完成这些配置后,还需要进行格式化NameNode、启动Hadoop服务、测试集群的连通性和运行WordCount示例等操作,以验证集群的正确性和功能性。WordCount是一个简单的例子,用于统计文本文件中的单词出现次数,是测试Hadoop集群处理能力的常见方法。
在实际生产环境中,还需要考虑安全性、监控、性能优化等方面,例如启用Hadoop的安全模式(如Kerberos)、配置日志聚合、调整内存和CPU分配等。配置Hadoop集群是一个涉及多方面细节的过程,需要对Hadoop的架构和工作原理有深入理解。
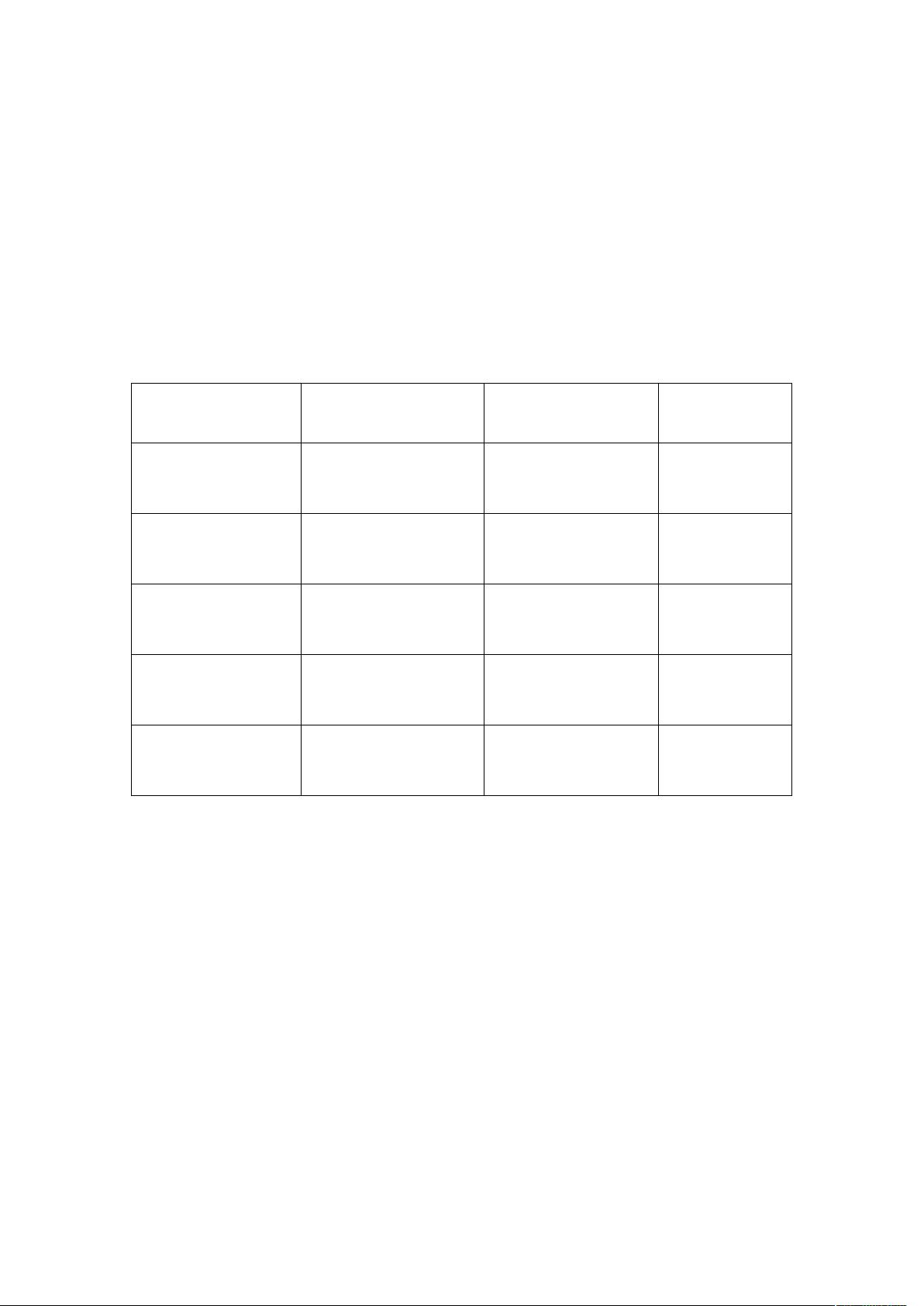
Hadoop 集群配置
1 集群简要介绍
Hadoop 集群采用一个 Master 节点,和四个 Slave 节点。Master 和 Slave 节
点信息如下:
机器名称
IP Master/Slave
任务
MasterHostname 192.168.39.200 Master
NameNode
JobTracker
Slave1Hostname 192.168.39.201 Slave
DataNode
TaskTracker
Slave2Hostname 192.168.39.202 Slave
DataNode
TaskTracker
Slave3Hostname 192.168.39.203 Slave
DataNode
TaskTracker
Slave4Hostname 192.168.39.204 Slave
DataNode
TaskTracker
2 安装环境
Hadoop 集群配置涉及到的系统及软件版本如下:
(1) 系统环境:RedHat Enterprise Linux Server 6.3;
(2) Hadoop 版本:Hadoop-1.0.3;
(3) JDK 版本:jdk-6u34-linux-x64
下载后可阅读完整内容,剩余7页未读,立即下载
115 浏览量
点击了解资源详情
113 浏览量
点击了解资源详情
110 浏览量
点击了解资源详情
167 浏览量
点击了解资源详情
点击了解资源详情

wzz0725
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机实验指导书资料
- 用Eclipse开发J2ME手机游戏入门讲座.doc
- ARM嵌入式系统C语言编程
- JAVA基础好东西啊快来看看吧
- 安装 oracle 数据库 10g 的基础知识
- 数据结构教学大纲 数据结构考研复习
- SQL Server笔试题解答
- flex 3 cookbook
- 软件工程VC++深入详解,包括mfc的相关介绍,一定让您功力大增
- java葵花宝典——知识库
- MB V6 Inst Notes SLES 10 Linux
- Eclipse in Action A GUIDE FOR JAVA DEVELOPERS
- 网络经典命令行(网络高手必备)
- 编程\WinXP技巧小结
- 单片机入门之c51语言
- ACM入门 系统地向初学ACM的同学讲解ACM的注意事项
