Ubuntu上V2.0 Hadoop MapReduce集群搭建教程:详解步骤与SSH配置
需积分: 3 94 浏览量
更新于2024-07-20
1
收藏 7.22MB DOCX 举报
本篇教程详细介绍了如何在Ubuntu操作系统上搭建Hadoop MapReduce集群,从基础准备到实际操作,一步步帮助读者掌握搭建过程。以下是关键知识点:
1. **基本准备:Java & JDK**
- 首先,用户需要下载JDK-7-linux-i586.tar.gz,推荐使用迅雷下载并将其放置在Linux的/usr/lib/jvm/java目录下。
- 如果下载的是bin文件,需使用sudo chmod u+x 命令赋予可执行权限。
- 接着,进行JDK的解压和安装,通过tar -xvf jdk-7-linux-i586.tar.gz来完成。
- 然后,编辑环境变量,添加JAVA_HOME和PATH,确保JAVA命令可以在终端中调用。通过vim ~/.bashrc或nano ~/.bashrc编辑文件,添加相应的路径,保存并使设置生效。
2. **配置默认JDK版本**
- Ubuntu可能预装了OpenJDK,需要将新安装的JDK设为默认。通过更新系统环境变量并列出所有可用的JDK版本来实现。
3. **安装SSH服务**
- SSH服务用于远程登录和集群管理。在Ubuntu上,首先安装openssh-server,可能需要解决网络中断导致的更新问题。
- 确保22端口已开启,可以通过netstat-nat命令检查。
4. **SSH无密码登录**
- 创建SSH密钥对,常用的是RSA方式。用户需要运行ssh-keygen命令,一路回车,系统会自动生成id_rsa和id_rsa.pub两个文件,分别存储私钥和公钥。
5. **集群配置与启动**
- 完成以上步骤后,开始配置Hadoop集群,包括主节点和从节点的配置,以及配置文件的调整。这包括编辑核心配置文件如core-site.xml和hdfs-site.xml,以及mapred-site.xml等。
- 接下来,启动Hadoop服务,包括HDFS(Hadoop Distributed File System)和MapReduce。通常会涉及到启动守护进程如namenode、datanode、jobtracker和tasktracker。
6. **测试与验证**
- 启动后,可以通过命令行工具如jps检查服务是否运行正常。同时,可以通过运行一些Hadoop的示例程序(如WordCount)来测试集群的功能。
本文档结构清晰,逐步指导读者搭建Hadoop MapReduce集群,适合初学者学习和实践经验。通过实践这些步骤,用户将能掌握如何在Ubuntu上搭建并管理和测试Hadoop集群。
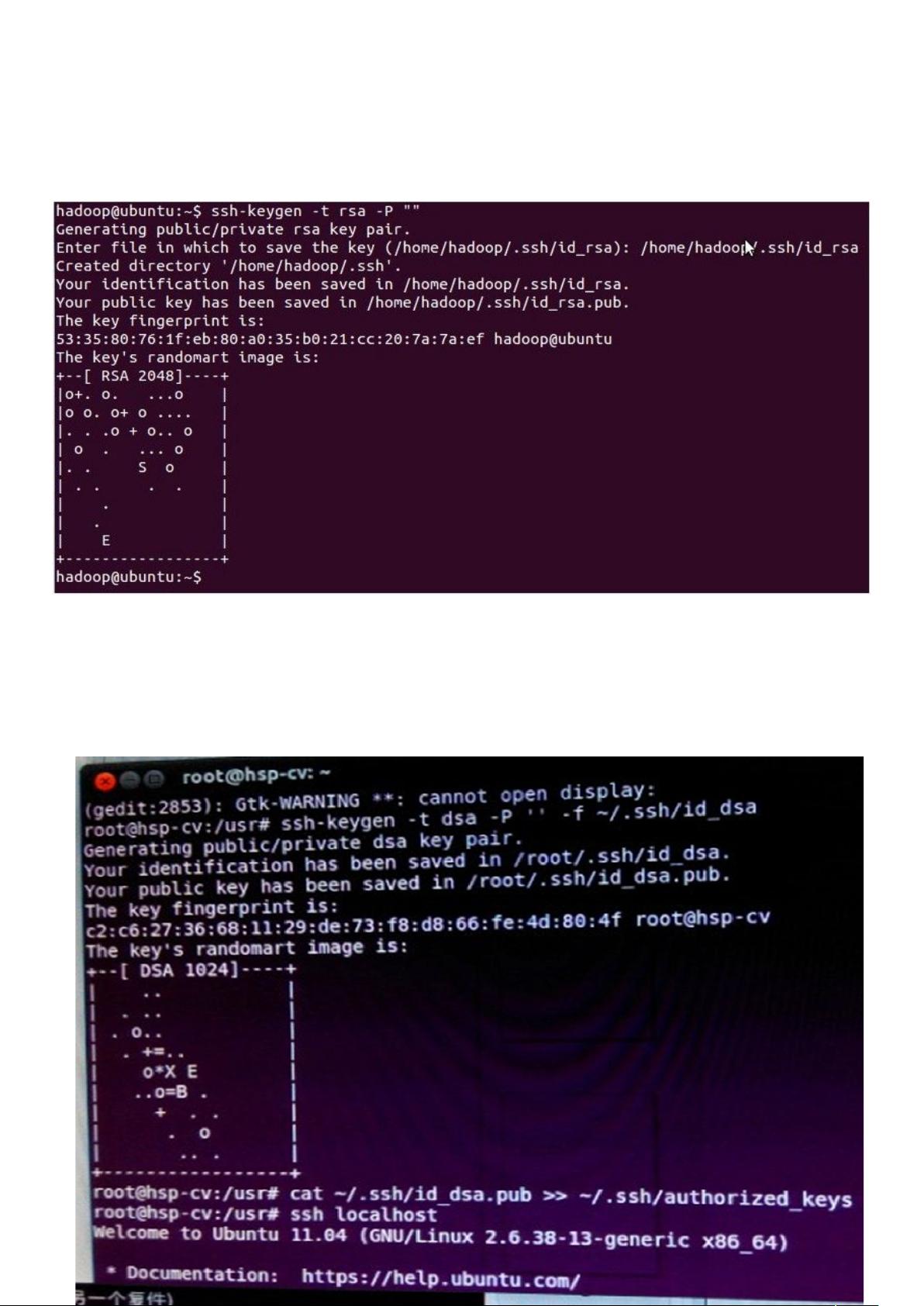
六. $建立 ssh 无密码登录本机t
ssh 生成密钥有 rsa 和 dsa 两种生成方式,默认情况下采用 rsa 方式。
1、创建 ssh-key,,这里我们采用 rsa 方式t
剩余26页未读,继续阅读
2020-12-26 上传
2013-05-04 上传
2023-06-28 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-05-27 上传

huberk
- 粉丝: 2
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
