二叉树构造:前序与中序遍历解析
需积分: 22 35 浏览量
更新于2024-08-05
收藏 501KB PDF 举报
"这篇资料主要介绍了如何通过前序遍历和中序遍历的数据来构建二叉树。问题的关键在于理解两种遍历方式的特点,并利用它们的特性进行递归构造。"
在计算机科学中,二叉树是一种常用的数据结构,它的每个节点最多有两个子节点,通常分为左子节点和右子节点。前序遍历、中序遍历和后续遍历是二叉树的三种基本遍历方法,它们各有特点,常常用于二叉树的构建和查找等问题。
**前序遍历**(Preorder Traversal)的顺序是“根左右”,即首先访问根节点,然后递归地访问左子树,最后访问右子树。这种遍历方式中,根节点始终是第一次出现的节点。
**中序遍历**(Inorder Traversal)的顺序是“左根右”,即先递归地访问左子树,然后访问根节点,最后递归地访问右子树。在二叉搜索树(BST)中,中序遍历可以得到节点值的升序序列。
给定前序遍历和中序遍历的序列,可以唯一确定一棵二叉树。这是因为前序遍历的第一个元素一定是树的根节点,而在中序遍历中,根节点将左子树和右子树分隔开来。因此,我们可以根据这两个序列构建二叉树。
**构建过程**:
1. 使用中序遍历找到根节点,根节点将中序遍历序列分成两部分:左边是左子树的中序遍历,右边是右子树的中序遍历。
2. 根据前序遍历,根节点之后的部分分别对应左子树和右子树的前序遍历。
3. 递归地对左子树和右子树执行相同的操作,直到构建完整个二叉树。
为了提高定位根节点的效率,可以使用哈希表记录中序遍历中每个元素的索引位置。这样,在构造二叉树时,可以直接通过哈希表查找到根节点,降低时间复杂度。
**Java代码实现**:
```java
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
// 哈希表存储中序遍历中每个元素的索引
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
return buildTreeHelper(preorder, 0, preorder.length - 1, inorder, 0, inorder.length - 1, map);
}
private TreeNode buildTreeHelper(int[] preorder, int preStart, int preEnd, int[] inorder, int inStart, int inEnd, Map<Integer, Integer> map) {
// 当区间为空时,返回null
if (preStart > preEnd || inStart > inEnd) return null;
// 前序遍历的第一个元素是当前子树的根节点
TreeNode root = new TreeNode(preorder[preStart]);
// 查找根节点在中序遍历中的位置
int rootIndex = map.get(root.val);
// 递归构建左子树和右子树
root.left = buildTreeHelper(preorder, preStart + 1, preStart + rootIndex - inStart, inorder, inStart, rootIndex - 1, map);
root.right = buildTreeHelper(preorder, preStart + rootIndex - inStart + 1, preEnd, inorder, rootIndex + 1, inEnd, map);
return root;
}
```
这段代码首先创建了一个哈希表来存储中序遍历中的元素及其索引,然后通过`buildTreeHelper`方法递归地构建二叉树。在每次递归中,都找到前序遍历的第一个元素作为当前子树的根节点,然后根据中序遍历中根节点的位置划分左子树和右子树的范围,继续递归构建。
通过这种方法,我们可以在给定前序遍历和中序遍历序列的情况下,有效地构造出对应的二叉树。对于给定的示例,输入和输出都符合预期,证明了该算法的正确性。
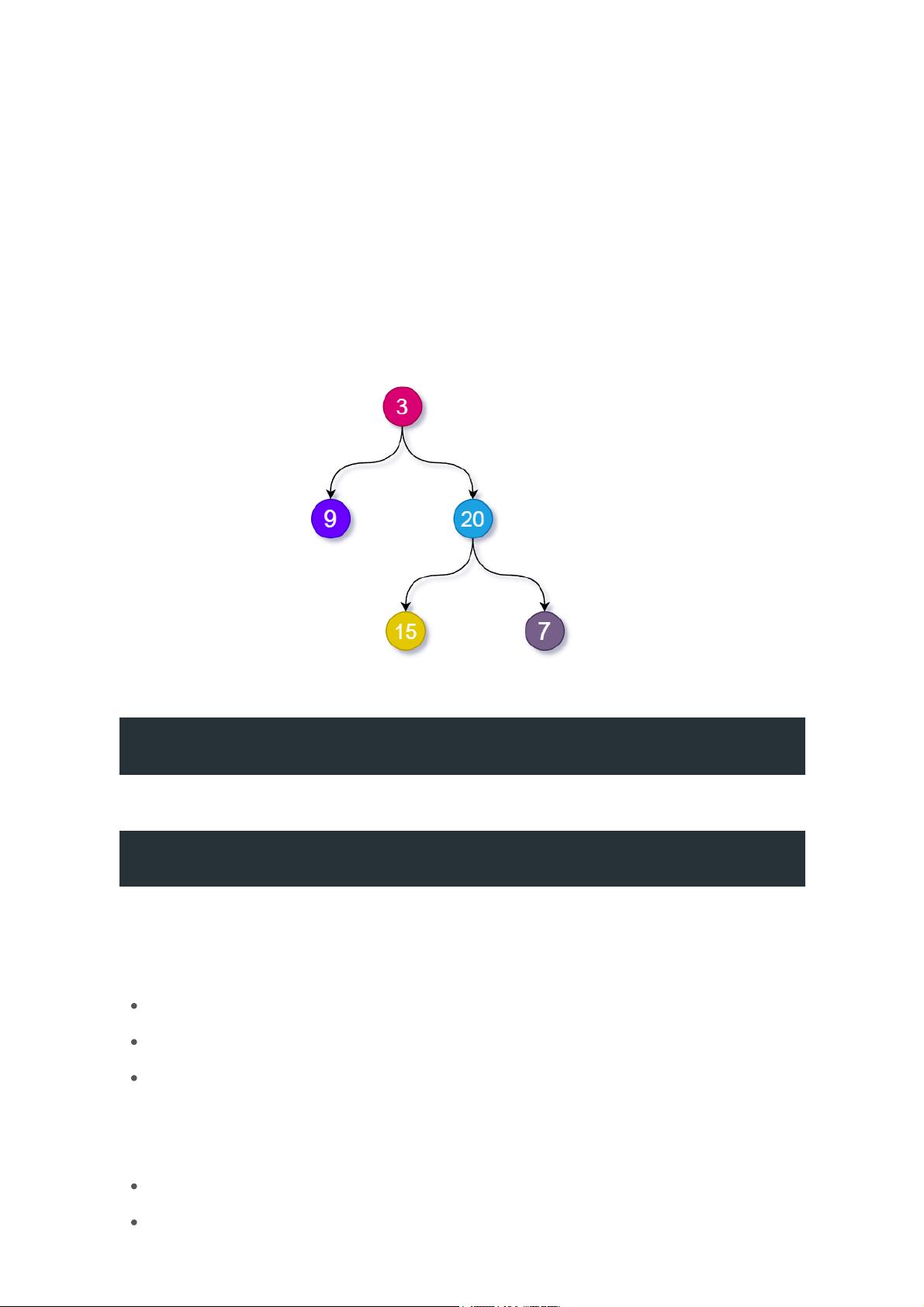
前序与中序遍历构造二叉树
题目
解析:
给定两个整数数组 preorder 和 inorder,其中preorder是二叉树的先序遍历,inorder是同一颗=棵树
的中序遍历,构造二叉树并返回其根节点。
示例1:
示例2:
遍历规则
二叉树前序遍历的顺序为:简称" 根 左 右"
先遍历根节点;
随后递归地遍历左子树;
最后递归地遍历右子树。
二叉树中序遍历的顺序为:简称" 左 根 右"
先递归地遍历左子树;
随后遍历根节点;
input:preorder = [3, 9, 20, 15, 7], inorder = [9, 3, 15, 20, 7]
output:[3, 9, 20, null, null, 15, 7]
1
2
input:preorder = [-1], inorder = [-1]
output:[-1]
1
2
下载后可阅读完整内容,剩余7页未读,立即下载
2021-06-30 上传
2024-01-30 上传
2021-12-30 上传
2024-03-02 上传
2023-10-05 上传
2023-06-07 上传
2023-10-17 上传
2023-12-21 上传
2023-06-28 上传

JoyfulRust
- 粉丝: 37
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
