知识图谱大会:结构化先验推动知识提取
需积分: 10 171 浏览量
更新于2024-07-17
收藏 16.74MB PDF 举报
本资源是一份关于2019年全国知识图谱与语义计算大会的前沿讲习班PPT和讲义,由XiangRen教授来自美国南加州大学计算机科学系、USC信息科学研究所和USC机器学习中心。讲座主题聚焦于“从数据到模型编程:注入结构化先验进行知识提取”,探讨了机器阅读如何将文本转化为知识结构。
主要内容分为两部分:
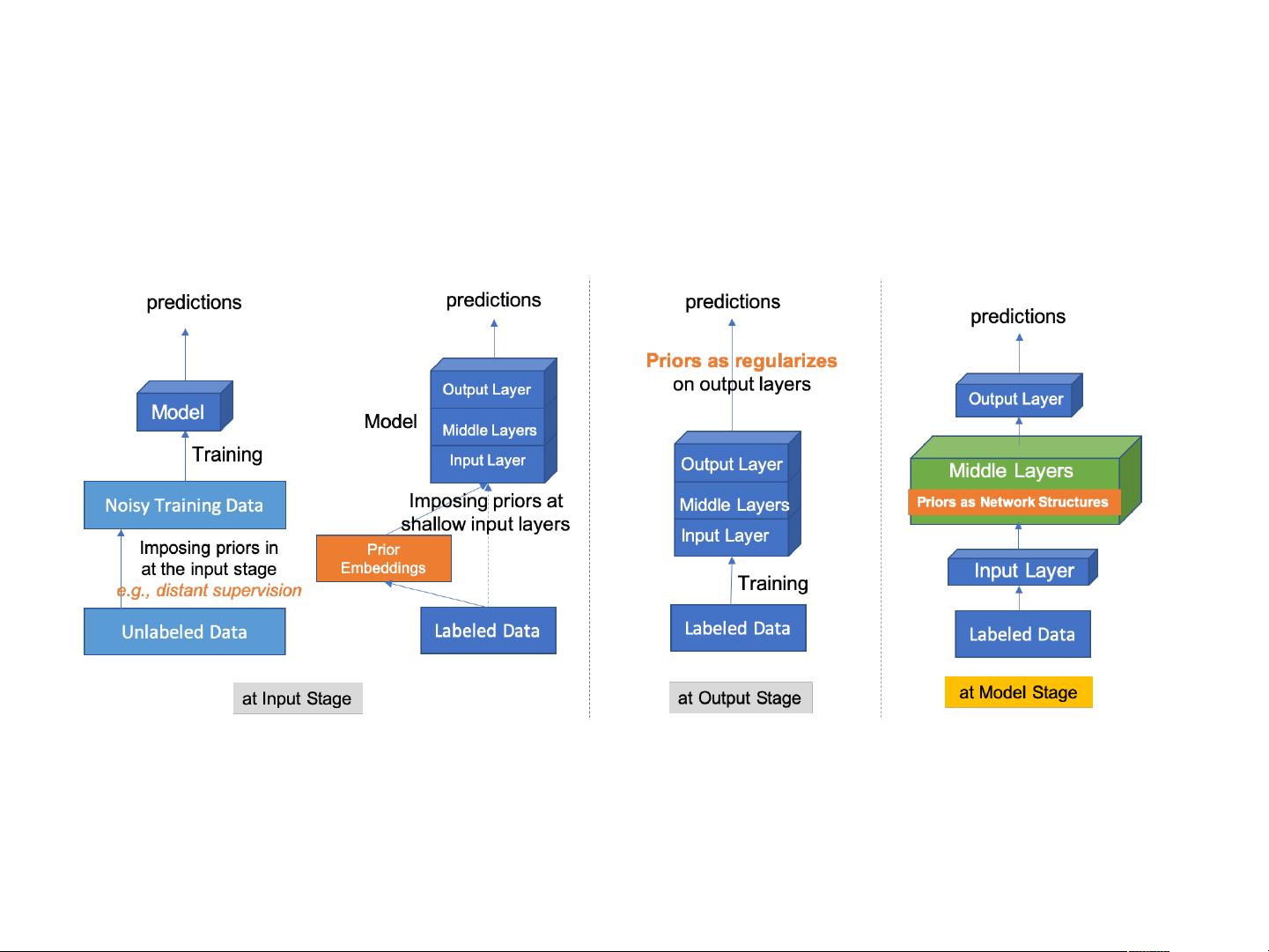
1. **从数据到模型编程:注入结构化先验**
这部分强调了在知识提取过程中,如何通过将结构化的先验知识融入到数据处理和模型构建中,提升算法的效率和准确性。这种方法可以为知识抽取任务提供导向,比如识别和解析特定类型的信息(如“Typed”实体和关系),例如,旅馆评论中的地理位置信息和与之相关的餐馆名称(如Junior’s Cheesecake和Virgil’s BBQ)。
2. **机器阅读:从文本到知识结构**
讲座深入讨论了如何通过机器阅读技术,从自然语言文本中识别并构建出结构化的知识。以酒店评论为例,系统能自动识别出旅馆名称(Hilton property)、具体位置(Times Square)、附近的设施(subways、Broadway shows和餐馆)等,这些都是知识图谱中的关键节点。同时,还提及了在实际应用中,如2013年埃及抗议事件这样的大规模社会事件,如何通过机器学习和人工标注相结合的方式,进行复杂事件的识别和理解。
在处理这类复杂文本时,人类标注作为先验知识的补充,起到了关键作用。例如,通过人工对酒店评论进行标记,系统可以学习如何理解和关联不同类型的结构化事实,如“位于”、“附近有”等关系。
总体来说,这份资料提供了关于如何利用机器学习和知识图谱技术来处理自然语言文本,提取和组织有价值的信息的方法,以及在实践中如何平衡自动化和人工干预以优化知识抽取和理解的过程。这对于那些关注知识图谱构建、自然语言处理和机器智能领域的研究者和实践者来说,具有很高的参考价值。
Previous Work & This Talk
""
Learning named en/ty tagger from domain
dic/onary LM20+@ (= 0/#< NOPG7 !Q"JR
Neural rule grounding LS21: (= 0/#< !Q"KR
KagNet: Learning to Answer
Commonsense Ques/ons with
Knowledge-aware Graph
Networks LG3+ (= 0/#< !Q"KR


剩余64页未读,继续阅读
2019-08-29 上传
2019-08-29 上传
2023-06-06 上传
2023-07-13 上传
2023-05-19 上传
2023-07-20 上传
2023-07-16 上传
2023-06-08 上传
2023-06-08 上传
2023-07-16 上传

Jayxp
- 粉丝: 6
- 资源: 137
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
