在自然语言处理中应用BP神经网络的实例分析
发布时间: 2024-04-14 18:58:18 阅读量: 107 订阅数: 50 

一个BP神经网络例子
# 1. 引言
在当今信息爆炸的时代,自然语言处理技术正扮演着越来越重要的角色。随着深度学习的发展,BP神经网络作为一种经典的神经网络模型,在自然语言处理领域展现出鲜明的优势。本文将系统介绍BP神经网络的基本原理以及其在自然语言处理中的应用。通过对文本分类和命名实体识别任务的案例分析,深入探讨BP神经网络在解决自然语言处理问题中的实际效果和潜力。通过总结已有研究成果并展望未来研究方向,旨在为进一步推动BP神经网络在自然语言处理领域的发展提供参考和借鉴。同时,本文也将介绍相关研究综述,为读者提供更广泛的学术背景和研究视野。
# 2. BP神经网络的基本原理
### 2.1 神经元模型
在神经网络中,神经元是信息处理的基本单元。常见的神经元模型包括感知器模型和Sigmoid模型。
#### 2.1.1 感知器模型
感知器是一种简单的神经元模型,输入经过加权求和后通过阈值函数输出。其数学表达式如下:
y = \begin{cases} 1, & \text{if } \sum_{i=1}^{n} w_i x_i + b > 0 \\ 0, & \text{otherwise} \end{cases}
这里 $x_i$ 是输入特征,$w_i$ 是对应的权重,$b$ 是偏置。
#### 2.1.2 Sigmoid模型
Sigmoid函数常被用作神经元的激活函数,将输入映射到0到1之间。其公式为:
\sigma(x) = \frac{1}{1+e^{-x}}
Sigmoid函数的优点是输出连续且可导,适合在反向传播算法中使用。
### 2.2 反向传播算法
反向传播是训练神经网络的常用方法,包括正向传播过程和反向传播过程。
#### 2.2.1 正向传播过程
正向传播是指输入数据通过网络逐层传播,直至得到输出结果。具体步骤如下:
1. 将输入数据乘以权重并加上偏置,得到每个神经元的输入;
2. 将输入传入激活函数,计算每个神经元的输出;
3. 将输出作为下一层的输入,重复以上步骤,直至输出层得到结果。
#### 2.2.2 反向传播过程
反向传播是通过计算损失函数对网络参数的梯度,实现参数更新的过程。具体步骤如下:
1. 计算输出层的误差,根据误差计算输出层权重的梯度;
2. 将梯度向前传播至隐藏层,计算隐藏层的误差和梯度;
3. 根据梯度和学习率更新网络参数,减小损失函数值。
#### 2.2.3 权值更新步骤
权值更新是反向传播算法的关键步骤,通过梯度下降法更新权重以减小损失。具体步骤如下:
1. 计算损失函数对权重的偏导数;
2. 更新权重 $w_{ij}$ 的公式为:$w_{ij} \leftarrow w_{ij} - \alpha \frac{\partial Loss}{\partial w_{ij}}$;
3. 迭代以上步骤直至达到收敛条件。
以上是BP神经网络的基本原理,包括神经元模型和反向传播算法。在接下来的章节中,我们将深入探讨神经网络在自然语言处理中的应用。
# 3. 自然语言处理中的基本概念
自然语言处理(NLP)是人工智能领域中的一个重要方向,它致力于让计算机能够理解、处理和生成人类语言。在NLP中,有一些基本概念是我们需要了解和掌握的,包括文本预处理、词嵌入技术以及神经网络在文本分类中的应用。
#### 3.1 文本预处理
在进行自然语言处理任务之前,通常需要对文本数据进行预处理,以便更好地进行后续处理。文本预处理包括分词处理、停用词去除和词干提取。
##### 3.1.1 分词处理
分词是将一个句子分割成词语的过程,是文本处理的基础步骤。在中文NLP中,分词是一个比较重要且具有挑战性的任务,因为中文没有像英文那样用空格相隔的词语。
```python
import jieba
text = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=False)
print(" ".join(seg_list))
```
代码解释:
- 使用结巴分词工具进行中文分词。
- cut_all=False表示采用精确模式分词。
- 最终将分词结果以空格连接并输出。
##### 3.1.2 停用词去除
停用词是指在文本分析中无实际意义的词语,如“的”、“是”等。去除停用词可以提高文本处理的效率和精度。
```python
stopwords = ["的", "是", "在", "了"]
filtered_text = [word for word in seg_list if word not in stopwords]
print(" ".join(filtered_text))
```
代码解释:
- 定义了一组停用词。
- 通过列表推导式过滤掉文本中的停用词。
- 输出去除停用词后的文本。
##### 3.1.3 词干提取
词干提取是将词语的词干或词根提取出来的过程,去除词语的变化形式,使得词语能够更好地统一表示。
```python
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stemmed_text = [stemmer.stem(word) for word in filtered_text]
print(" ".join(stemmed_text))
```
代码解释:
- 使用NLTK库的PorterStemmer进行词干提取。
- 遍历过滤后的文本,提取每个词语的词干。
- 输出词干提取后的文本。
#### 3.2 词嵌入技术
词嵌入是将词语映射到一个连续向量空间的技术,可以帮助我们更好地表征词语之间的语义关系。常见的词嵌入技术包括Word2Vec、GloVe和fastText。
##### 3.2.1 Word2Vec
Word2Vec是一种常用的词嵌入模型,它

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**专栏简介:**
本专栏深入探讨了 BP 神经网络,一种广泛应用于机器学习和深度学习中的神经网络模型。它从基本概念和原理入手,逐步介绍了 BP 神经网络中的激活函数、优化算法、训练过程、过拟合问题解决方案、正向和反向传播的作用、隐藏层节点数选择、梯度消失和梯度爆炸问题的处理方法。此外,专栏还探讨了 BP 神经网络与深度学习的关系和区别,以及它在图像识别、序列数据处理、异常检测、多任务学习、结构化数据处理和自然语言处理中的应用。通过深入的解析和丰富的实例分析,本专栏为读者提供了对 BP 神经网络的全面理解,使其能够有效地应用该模型解决实际问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S32K SPI开发者必读:7大优化技巧与故障排除全攻略
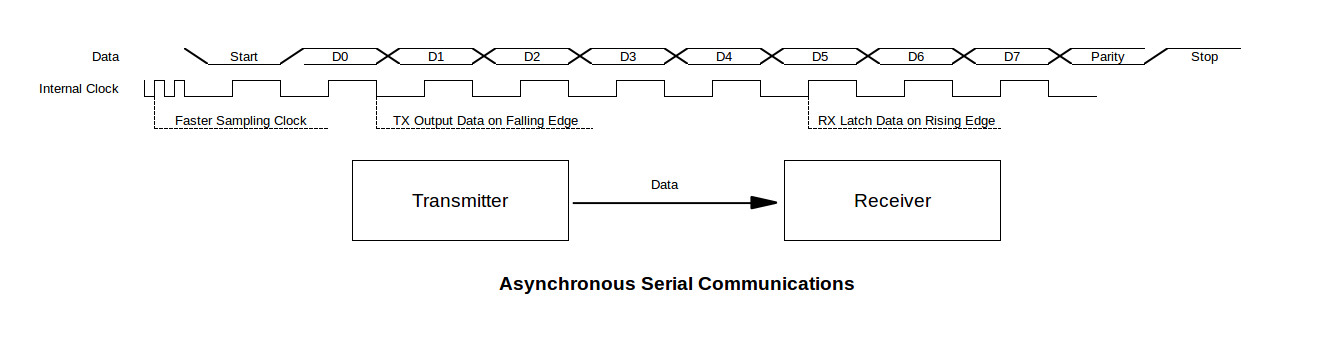
# 摘要
本文深入探讨了S32K微控制器的串行外设接口(SPI)技术,涵盖了从基础知识到高级应用的各个方面。首先介绍了SPI的基础架构和通信机制,包括其工作原理、硬件配置以及软件编程要点。接着,文章详细讨论了SPI的优化技巧,涵盖了代码层面和硬件性能提升的策略,并给出了故障排除及稳定性的提升方法。实战章节着重于故障排除,包括调试工具的使用和性能瓶颈的解决。应用实例和扩展部分分析了SPI在
图解数值计算:快速掌握速度提量图的5个核心构成要素
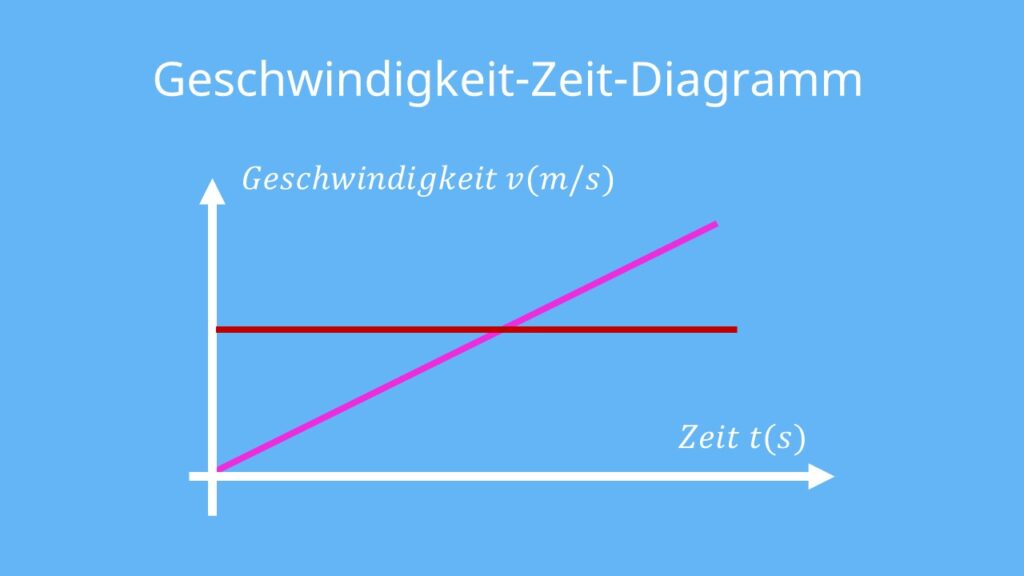
# 摘要
本文全面探讨了速度提量图的理论基础、核心构成要素以及在多个领域的应用实例。通过分析数值计算中的误差来源和减小方法,以及不同数值计算方法的特点,本文揭示了实现高精度和稳定性数值计算的关键。同时,文章深入讨论了时间复杂度和空间复杂度的优化技巧,并展示了数据可视化技术在速度提量图中的作用。文中还举例说明了速度提量图在
动态规划:购物问题的终极解决方案及代码实战

# 摘要
动态规划是解决优化问题的一种强大技术,尤其在购物问题中应用广泛。本文首先介绍动态规划的基本原理和概念,随后深入分析购物问题的动态规划理论,
【随机过程精讲】:工程师版习题解析与实践指南
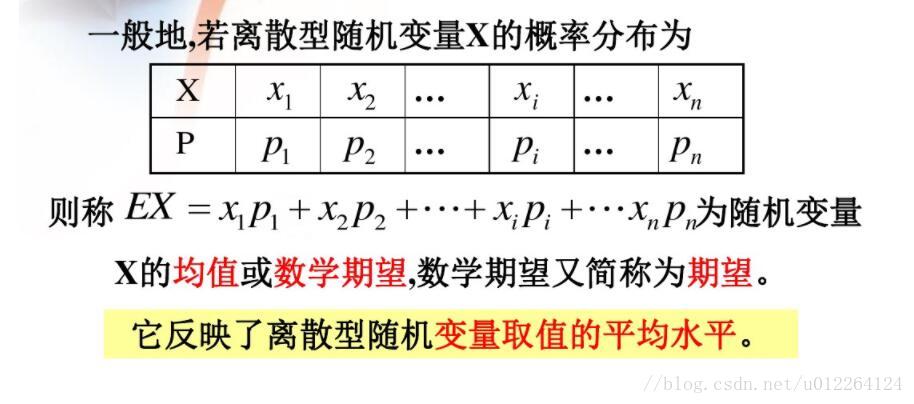
# 摘要
随机过程是概率论的一个重要分支,被广泛应用于各种工程和科学领域中。本文全面介绍了随机过程的基本概念、分类、概率分析、关键理论、模拟实现以及实践应用指南。从随机变量的基本统计特性讲起,深入探讨了各类随机过程的分类和特性,包括马尔可夫过程和泊松过程。文章重点分析了随机过程的概率极限定理、谱分析和最优估计方法,详细解释了如何通过计算机模拟和仿真软件来实现随机过程的模拟。最后,本文通过工程问题中随机过程的实际应用案例,以
【QSPr高级应用案例】:揭示工具在高通校准中的关键效果
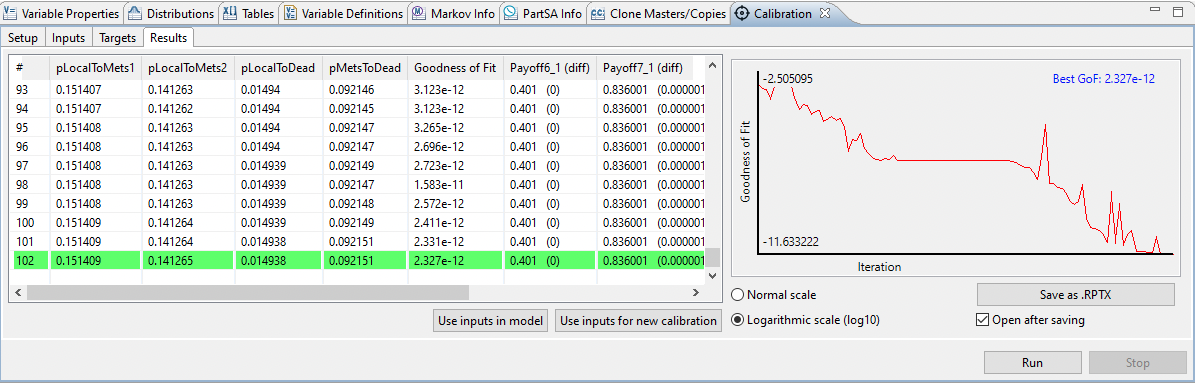
# 摘要
本论文旨在介绍QSPr工具及其在高通校准中的基础和应用。首先,文章概述了QSPr工具的基本功能和理论框架,探讨了高通校准的重要性及其相关标准和流程。随后,文章深入分析了QSPr工具的核心算法原理和数据处理能力,并提供了实践操作的详细步骤,包括数据准备、环境搭建、校准执行以及结果分析和优化。此外,通过具体案例分析展示了QSPr工具在不同设备校准中的定制
Tosmana配置精讲:一步步优化你的网络映射设置

# 摘要
Tosmana作为一种先进的网络映射工具,为网络管理员提供了一套完整的解决方案,以可视化的方式理解网络的结构和流量模式。本文从基础入门开始,详细阐述了网络映射的理论基础,包括网络映射的定义、作用以及Tosmana的工作原理。通过对关键网络映射技术的分析,如设备发现、流量监控,本文旨在指导读者完成Tosmana网络映射的实战演练,并深入探讨其高级应用,包括自动化、安全威胁检测和插件应用。最
【Proteus与ESP32】:新手到专家的库添加全面攻略

# 摘要
本文详细介绍Proteus仿真软件和ESP32微控制器的基础知识、配置、使用和高级实践。首先,对Proteus及ESP32进行了基础介绍,随后重点介绍了在Proteus环境下搭建仿真环境的步骤,包括软件安装、ESP32库文件的获取、安装与管理。第三章讨论了ESP32在Proteus中的配置和使用,包括模块添加、仿真
【自动控制系统设计】:经典措施与现代方法的融合之道
# 摘要
自动控制系统是工业、航空、机器人等多个领域的核心支撑技术。本文首先概述了自动控制系统的基本概念、分类及其应用,并详细探讨了经典控制理论基础,包括开环和闭环控制系统的原理及稳定性分析方法。接着,介绍了现代控制系统的实现技术,如数字控制系统的原理、控制算法的现代实现以及高级控制策略。进一步,本文通过设计实践,阐述了控制系统设计流程、仿真测试以及实际应用案例。此外,分析了自动控制系统设计的当前挑战和未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )