Kafka消息队列实战:掌握分布式消息处理技术
发布时间: 2024-07-02 00:35:18 阅读量: 4 订阅数: 7 

# 1. Kafka基础理论**
Kafka是一种分布式消息队列系统,它提供了高吞吐量、低延迟的消息传递服务。本节将介绍Kafka的基本概念和架构,包括:
- **消息模型:** Kafka使用发布-订阅模型,生产者将消息发布到主题,消费者从主题订阅消息。
- **集群架构:** Kafka集群由多个Broker组成,每个Broker存储一部分数据分区。
- **分区机制:** Kafka将主题划分为多个分区,每个分区由一个Broker负责,确保高可用性和负载均衡。
- **副本机制:** 每个分区都有多个副本,存储在不同的Broker上,保证数据的冗余和容错性。
# 2. Kafka消息队列编程
### 2.1 Kafka生产者和消费者
#### 2.1.1 生产者API
Kafka生产者API允许应用程序将消息发送到Kafka集群。它提供了以下主要方法:
- `send()`:发送一条消息到指定主题。
- `send(callback)`:发送一条消息并指定一个回调函数,当消息被发送成功或失败时调用。
- `flush()`:强制刷新所有未发送的消息。
**代码块:**
```java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// 设置生产者配置
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 创建消息记录
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "hello, world");
// 发送消息
producer.send(record);
// 刷新未发送的消息
producer.flush();
// 关闭生产者
producer.close();
}
}
```
**逻辑分析:**
* `ProducerConfig.BOOTSTRAP_SERVERS_CONFIG`:指定Kafka集群的引导服务器地址。
* `ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG`:指定消息键的序列化器。
* `ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG`:指定消息值的序列化器。
* `ProducerRecord`:表示一条要发送到Kafka主题的消息。
* `send()`:将消息发送到指定的主题。
* `flush()`:强制刷新所有未发送的消息。
* `close()`:关闭生产者,释放资源。
#### 2.1.2 消费者API
Kafka消费者API允许应用程序从Kafka集群接收消息。它提供了以下主要方法:
- `subscribe()`:订阅一个或多个主题。
- `poll()`:从订阅的主题中拉取消息。
- `commitOffset()`:提交已消费消息的偏移量。
**代码块:**
```java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“javhi”专栏汇集了Java开发领域的宝贵知识和实践技巧。它深入剖析Java虚拟机调优、内存泄漏、并发编程、垃圾回收机制等关键技术,提供实战技巧和解决方案。此外,专栏还揭秘了MySQL死锁和索引失效等常见问题,帮助读者深入理解数据库优化。通过阅读本专栏,Java开发者可以提升应用性能、解决内存泄漏、掌握多线程编程精髓、优化内存管理,并有效解决MySQL数据库中的死锁和索引失效问题,从而提升整体开发效率和应用性能。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32单片机滤波算法实践:消除噪声,提升信号质量
# 1. STM32单片机滤波算法概述
滤波算法是信号处理中不可或缺的技术,它可以有效去除信号中的噪声和干扰,提取有用的信息。在STM32单片机中,滤波算法有着广泛的应用,包括噪声信号处理、电机控制、图像处理和语音处理等领域。
本章将对STM32单片机滤波算法进行概述,包括滤波算法的分类、特性和在STM32单片机中的应用。通过本章的学习,读者可以对STM32单片机滤波算法有一个全面的了解
MySQL数据库云端部署,拥抱云计算的优势
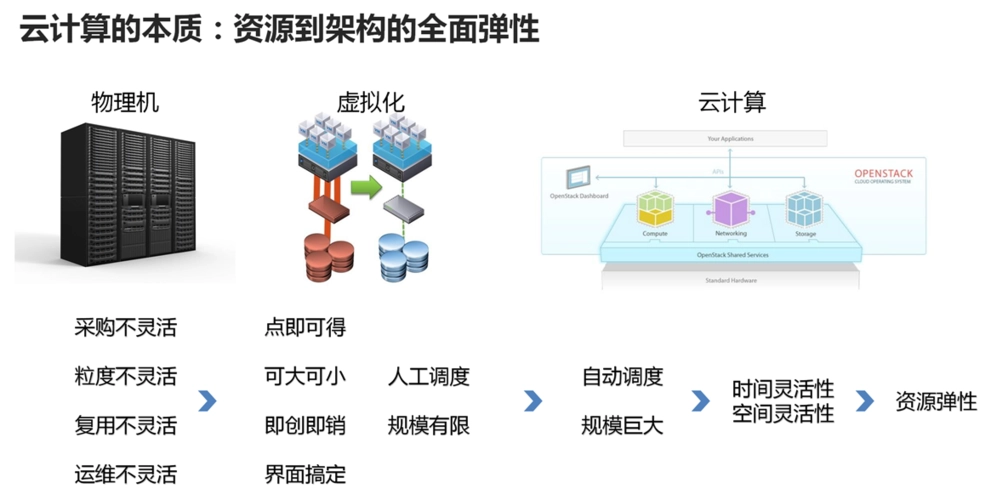
# 1. MySQL数据库云端部署概述
### 1.1 云端数据库的优势
云端数据库相较于传统本地部署数据库,具有以下优势:
- **弹性扩展:**云端数据库可以根据业务需求弹性扩展,无需提前预估容量,避免资源浪费或不足。
- **高可用性:**云端数据库通常采用多副本机制,保证数据的高可用性,避免单点故障导致数据丢失。
- **低运维成本:**云端数据库由云服务商负责运维,用户无需投
STM32单片机屏幕驱动与汽车电子:实现智能驾驶与车载娱乐,打造未来出行体验

# 1. STM32单片机简介**
STM32单片机是意法半导体公司生产的一系列32位微控制器,基于ARM Cortex-M内核。STM32单片机以其高性能、低功耗和丰富的片上外设而闻名,广泛应用于工业控制、消费电子、汽车电子等领域。
STM32单片机系列包括多个产品线,如STM32F、STM32L
STC单片机 USB通信:连接外部世界,拓展单片机应用,打造智能物联网设备

# 1. STC单片机USB通信概述**
USB(通用串行总线)通信是一种广泛应用于电子设备之间数据传输的标准接口。STC单片机集成了USB接口,支持与外设设备进行USB通信。本节将概述STC单片机USB通信的基本概念和特点。
STC单片机USB通信主要用于连接外设设备,例如键盘、鼠标、打印机和存储设备。通过USB接口,STC单片机可以与这些设备交换数据,实
离散分布的计算方法:从解析到模拟,掌握离散分布的计算技巧

# 1. 离散分布的解析计算方法
离散分布是一种概率分布,其取值只能为离散的整数值。解析计算方法是通过数学公式直接计算分布的概率、期望值和方差等参数。
### 1.1 概率质量函数(PMF)的计算
PMF 给出离散分布中每个取值的概率。对于一个离散分布 X,其 PMF 为:
```
P(X = x) = f(x)
```
其中,x 是 X 的取值,f(x) 是 PMF 函数。
### 1.
算术运算优化秘籍:利用编译器优化和算法技巧,提升效率

# 1. 算术运算优化概述
算术运算优化是计算机科学中的一种技术,旨在提高算术运算的性能。通过应用各种优化技术,可以减少执行时间并提高代码效率。算术运算优化包括以下几个主要方面:
- **常量折叠和传播:**将常量表达式替换为其计算结果,消除不必要的计算。
- **表达式简化:**应用代数恒等式和数学规则简化表达式,减少计算量。
- **循环展开和融合:**将循环展开为一组顺序执行的语
STM32单片机选型与传感器应用:从温度传感器到加速度传感器,详解不同传感器的选型与使用,打造智能感知的嵌入式系统
# 1. STM32单片机简介**
STM32单片机是意法半导体(STMicroelectronics)推出的一系列基于ARM Cortex-M内核的32位微控制器。STM32单片机以其高性能、低功耗、丰富的外设和广泛的应用而闻名。
STM32单片机具有多种型号,涵盖从入门级到高级别的各种应用需求。这些型号包括STM32F0、STM32F1、STM32F2、S
反双曲正弦函数:在娱乐和游戏中的必备知识

# 1. 反双曲正弦函数的理论基础**
反双曲正弦函数(sinh⁻¹)是双曲正弦函数(sinh)的反函数,定义为:
```
sinh⁻¹(x) = ln(x + √(x² + 1))
```
其中,x 是实数。
反双曲正弦函数具有以下性质:
* **单调递增:**sinh⁻¹(x) 随着 x 的增加而单调递增。
* **奇函数:**sinh⁻¹(
STM32单片机高级应用:实时操作系统、图形引擎实战
# 1. STM32单片机简介**
STM32单片机是意法半导体(STMicroelectronics)公司推出的一系列基于ARM Cortex-M内核的高性能微控制器。STM32单片机以其强大的性能、丰富的 периферийные устройства、低功耗和易用性而著称,广泛应用于工业控制、医疗设备、汽车电子、物联网等领域。
STM32单片机系列包含多种型号,从入门级的
MySQL性能测试与分析:5个步骤,发现性能瓶颈并优化数据库

# 1. MySQL性能测试与分析概述
MySQL性能测试与分析是确保数据库系统高效运行和满足业务需求的关键。它涉及使用各种方法和工具来评估数据库的性能,识别瓶颈并实施优化措施。
通过性能测试,我们可以确定数据库在不同负载和场景下的表现,并确定其性能瓶颈。性能分析则帮助我们深入了解数据库内部的工作原理,识别慢查询、资源消耗和潜在的优化机会。
通过结合测试和分析,我们可以获得对MySQL性能的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )