【深度学习细节】:权重衰减与L1_L2正则化应用指南
发布时间: 2024-11-24 22:49:20 阅读量: 42 订阅数: 33 

深度学习中的正则化方法研究.pdf

# 1. 深度学习中的权重衰减概念
在深度学习模型训练过程中,权重衰减是一种常见的正则化技术,它通过在损失函数中加入一个额外的项来控制模型的复杂度,以防止过拟合。权重衰减通常与L2正则化联系在一起,因为它会惩罚大权重,促使模型在训练过程中对权重值进行限制。当权重值较大时,其对损失函数的贡献也会相应增大,从而在优化过程中驱动模型倾向于选择较小的权重值。这种方法不仅有助于提高模型的泛化能力,还可以通过减少模型的复杂度来简化模型结构,从而降低模型对训练数据的依赖。
# 2. L1与L2正则化的理论基础
## 2.1 L1正则化的基本原理
### 2.1.1 L1正则化的数学表达
L1正则化,也被称为Lasso正则化,是一种线性模型的正则化技术,其目标函数通常具有如下形式:
\[
\min_{w} \left( \frac{1}{2n} \sum_{i=1}^{n} (w^Tx^{(i)} - y^{(i)})^2 + \lambda \sum_{j=1}^{p} |w_j| \right)
\]
其中,\(x^{(i)}\) 表示第 \(i\) 个样本,\(y^{(i)}\) 表示该样本的实际值,\(w\) 是模型参数,\(n\) 表示样本总数,\(p\) 表示特征数量,\(\lambda\) 是正则化参数,用于平衡训练误差和正则化项的权重。
在数学上,L1正则化使得目标函数成为凸函数,而绝对值的使用导致最优解倾向于包含很多零权重的特征,这有助于特征选择。
### 2.1.2 L1正则化与稀疏性的关系
L1正则化在机器学习领域的一个显著特点就是它的稀疏性。这是因为L1正则化的惩罚项是一个绝对值的和,使得最优参数 \(w\) 中的一部分倾向于绝对值很小,从而在优化过程中容易被驱逐至零。
稀疏性在特征选择中非常有用,因为它可以帮助我们识别并保留那些最重要的特征,而忽略掉对模型预测贡献较小的特征。这不仅简化了模型,减少了过拟合的风险,而且还可以加速模型的预测速度,因为特征的数量减少了。
```python
import numpy as np
from sklearn.linear_model import Lasso
# 假设 X 是特征矩阵,y 是目标向量
X = np.random.rand(100, 10) # 100个样本,10个特征
y = np.random.rand(100) # 100个目标值
# 应用L1正则化
lasso = Lasso(alpha=0.1) # alpha 是正则化参数
lasso.fit(X, y)
# 输出权重向量
print(lasso.coef_)
```
在上述代码块中,我们使用了 `sklearn` 库中的 `Lasso` 类来展示L1正则化在实际代码中的应用。我们首先创建了一些随机数据,然后使用 `Lasso` 拟合了数据。通过调整 `alpha` 参数,我们可以控制正则化的强度,进而影响特征选择的结果。`Lasso` 类默认会输出非零权重值,这反映了L1正则化带来的稀疏性。
## 2.2 L2正则化的基本原理
### 2.2.1 L2正则化的数学表达
L2正则化,也被称为岭回归(Ridge Regression),它的目标函数通常具有如下形式:
\[
\min_{w} \left( \frac{1}{2n} \sum_{i=1}^{n} (w^Tx^{(i)} - y^{(i)})^2 + \frac{\lambda}{2} \sum_{j=1}^{p} w_j^2 \right)
\]
这里,同样地,\(x^{(i)}\) 是第 \(i\) 个样本,\(y^{(i)}\) 是样本的实际值,\(w\) 是模型参数,\(n\) 表示样本总数,\(p\) 表示特征数量,而 \(\lambda\) 是正则化参数。
L2正则化对权重的惩罚是一个平方项,这使得目标函数在参数空间内形成一个椭圆形的等高线,导致模型更偏好于小的、非零的权重值。不同于L1正则化导致稀疏解,L2正则化倾向于将权重均匀缩小,但不为零。
### 2.2.2 L2正则化与权重衰减的关系
L2正则化与权重衰减(weight decay)密切相关。在梯度下降优化中,权重衰减是通过在每个梯度步中减去一小部分权重来实现的,这个过程等价于在损失函数中添加L2惩罚项。当使用L2正则化时,正则化项会推动参数向量的长度(即权重的L2范数)减小,因此起到了权重衰减的作用。
```python
from sklearn.linear_model import Ridge
# 使用同样的数据集
ridge = Ridge(alpha=0.1) # alpha 是正则化参数
ridge.fit(X, y)
# 输出权重向量
print(ridge.coef_)
```
在上面的代码块中,我们使用了 `sklearn` 库中的 `Ridge` 类来展示L2正则化。与L1正则化类似,我们使用随机生成的数据集拟合了模型。通过调整 `alpha` 参数,我们可以控制L2正则化的强度,这个过程等同于权重衰减。
## 2.3 L1与L2正则化的比较
### 2.3.1 正则化效果的对比分析
L1和L2正则化的区别不仅在于它们的数学表达式,还在于它们对模型的影响。L1正则化倾向于产生稀疏的权重矩阵,这是由于绝对值项的存在,从而使得模型在优化过程中某些权重变为零。相比之下,L2正则化则倾向于产生较小且非零的权重值,这有助于平滑模型的复杂度,减少过拟合的风险,但不会像L1那样进行特征选择。
### 2.3.2 应用场景的差异探讨
在选择L1和L2正则化时,我们应当考虑具体的应用场景。当模型需要进行特征选择时,L1正则化更为合适。例如,在文本分类或者图像识别中,我们可能希望减少特征的数量以简化模型,并通过减少特征的维度来提高计算效率。相对地,如果我们的目标是防止过拟合并平滑模型的权重,同时保留所有特征,则L2正则化是更好的选择。
```python
# 假设我们在进行一个回归任务,并且希望比较L1和L2正则化的效果
# 假设我们有一些数据
# 这里我们使用sklearn的make_regression函数来生成一些回归数据
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=20, noise=0.1)
# 分割数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 分别使用L1和L2正则化拟合模型
from sklearn.linear_model import LassoCV, RidgeCV
# L1正则化模型选择
lasso_cv = LassoCV(cv=5).fit(X_train, y_train)
# L2正则化模型选择
ridge_cv = RidgeCV(cv=5).fit(X_train, y_train)
# 输出最优的alpha参数
print(f"最优的L1正则化参数(alpha): {lasso_cv.alpha_}")
print(f"最优的L2正则化参数(alpha): {ridge_cv.alpha_}")
# 比较模型在测试集上的性能
from sklearn.metrics import mean_squared_error
y_pred_lasso = lasso_cv.predict(X_test)
y_pred_ridge = ridge_cv.predict(X_test)
print(f"L1正则化模型的测试误差: {mean_squared_error(y_test, y_pred_lasso)}")
print(f"L2正则化模型的测试误差: {mean_squared_error(y_test, y_pred_ridge)}")
```
在上述代码中,我们使用了 `make_regression` 函数生成了一组回归数据,并且分割出训练集和测试集。接着,我们分别应用了带有交叉验证的L1和L2正则化模型 `LassoCV` 和 `RidgeCV` 来找到最优的正则化参数,并在测试集上进行性能比较。这个例子展示了如何在实际问题中对比L1和L2正则化的效果,并选择了最合适的正则化方法。
# 3. 正则化在模型训练中的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨机器学习模型中的参数,涵盖模型参数与超参数的差异、模型调优实战技巧、参数初始化方法、Python模型调优实战、正则化技术、参数共享策略、模型参数解释性提升、参数寻优算法、模型调优误区、超参数调优自动化、贝叶斯优化、参数学习曲线、权重衰减与正则化、梯度下降算法、参数泛化能力等关键主题。通过深入浅出的讲解和实战演练,帮助读者全面理解模型参数,掌握模型调优技巧,提升模型性能,让机器学习模型更易于理解和应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
3D Slicer 快速上手秘籍:掌握界面布局与基础工具的终极指南
# 摘要
本文全面介绍了3D Slicer这一功能强大的医学影像处理软件,从界面布局与导航到基础工具的使用技巧,再到高级功能的深入解析。文章首先概述了3D Slicer的基本功能和用户界面,接着深入讲解了基础工具如图像处理、三维重建以及注释和测量的使用方法。在高级功能部分,本文解析了分割、配准、手术规划和自动化脚本接口。此外,还探讨了3D S
【频率响应测量技巧】:快速提升安捷伦4395A使用效率的5大技巧!

# 摘要
频率响应测量是电子工程领域中的关键技能,涉及到从基础测量到高级技术的多个层面。本文首先介绍了频率响应测量的基础知识,随后深入探讨了安捷伦4395A仪器的设置和使用,包括其功能介绍、仪器配置、校准和基准设置。第三章重点讲解了测量过程中的技巧与实践,如提升测量精度和数据分析方法。第四章介绍了高级频率响应测量技术,包括自动化测试流
【应用洛必达法则解决并发问题】:优化并发算法,效率倍增
# 摘要
本论文深入探讨了并发编程的基础概念、挑战以及洛必达法则在并发控制中的应用。首先,我们回顾了并发编程的基本理论和洛必达法则的数学原理,并分析了该法则在解决并发控制问题中的潜在优势和实际限制。接着,通过具体案例和算法实例,展示了洛必达法则在提升并发算法性能方面的实际应用和优化效果。文章进一步探讨了洛必达法则在分布式系统中的扩展应用,并与其他并发控制方法进行了比较分析。最后,展望了并发控制技术和洛必达法则研究的未来趋势,并提出了对开发者和行业的建议。本文旨在为并发优化领域提供新的视角和工具,为解决并发编程中的性能瓶颈和理论局限提供参考。
# 关键字
并发编程;洛必达法则;理论解读;算法优
SEE软件V8R2实战教程:零基础快速入门与问题速解
# 摘要
本文对SEE软件V8R2版本进行了全面介绍,涵盖了软件的概览与安装、基础操作、进阶技巧以及常见问题解决策略。首先介绍了软件的基本界面布局和配置选项,然后讲解了数据管理、视图和报表的设计与应用。接着,文章深入探讨了高级查询、数据分析、安全性和权限管理,以及定制化开发的可能性。此外,本文还提供了常见运行问题的诊断方法、功能
TEF668XA系统监控:实时性能分析与故障预警
# 摘要
本文介绍了TEF668XA系统的监控机制,并从理论和实践两个维度对其进行全面分析。首先,概述了TEF668XA系统监控的基础理论,包括系统架构分析、实时性能分析原理以及故障预警机制的理论基础。随后,详细探讨了在实际应用中如何部署监控工具、设计预警规则,并对性能优化与故障排除进行了案例分析。
ERP集成新视角:基于ISO 19453-1的最佳实践案例分析
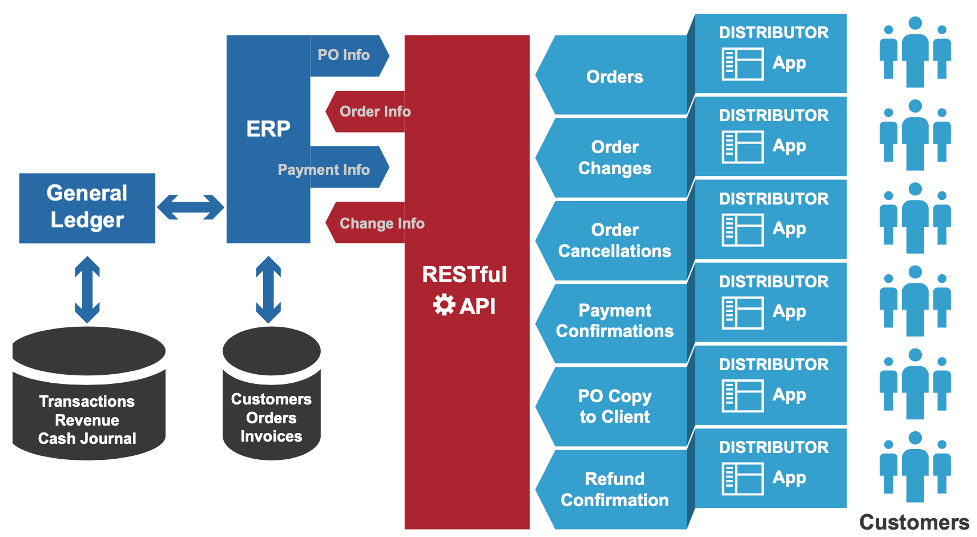
# 摘要
本文全面探讨了ERP集成与ISO 19453-1标准的应用,从理论基础到最佳实践案例,再到实践中遇到的挑战和解决方案。文章详细介绍了ERP系统的核心模块及其集成必要性,阐述了ISO 19453-1标准的框架与关键要求,并对集成策略和方法论进行了深入分析。案例研究部分展示了ERP集成在供应链管理、客户关系管理及财务流程自动化中的实
数据结构精通之道:深度剖析树形结构与图算法

# 摘要
树形结构与图算法是数据结构与算法领域的核心内容,对计算机科学中的多种应用具有重要意义。本文首先概述了树形结构与图算法的基本理论和实践应用,接着深入探讨了树形结构和图论的基础知识、经典算法及其实
跨平台EDEM-Fluent耦合开发:环境配置与调试策略完整指南
# 摘要
跨平台EDEM-Fluent耦合开发涉及将离散元方法(EDEM)和计算流体动力学(Fluent)软件整合,以进行复杂的多物理场分析和仿真。本文首先概述了EDEM-Fluent耦合开发的基本概念,随后详细介绍了软件环境的配置方法,包括系统要求、安装步骤、参数设置与优化以及耦合接口的配置。接着,文章探讨了耦合开发的调试策略,包括调试前的准备工作、调试技巧、性能调优策略。在实践应用方面,通过工程案例分析和代码优化,演示了耦合开发在解决实际问题中的应用。最后,文章展望了未来跨平台EDEM-Fluent耦合开发的趋势,包括软件新版本功能和社区资源分享的未来发展方向。
# 关键字
EDEM-F
JDK 1.8性能优化:掌握这5个实用技巧,立即提升Linux服务器性能
# 摘要
本文针对JDK 1.8版本的Java性能优化进行了全面的探讨,重点关注JVM内存管理、Java代码层面、以及Linux服务器环境下的JVM性能监控与调整。从内存管理优化到代码层面的性能坑、集合和并发处理,再到JMX工具的使用和系统级参数调优,本文详细论述了各种优化技术和策略。特别指出,JDK 1.8引入的新特性和API,例如Lambda表达式、Stream
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )