【理解文本生成的神经网络】:从RNN到Transformer,PyTorch实现的进化之路
发布时间: 2024-12-11 15:25:02 阅读量: 22 订阅数: 14 

PyTorch:循环神经网络与序列数据处理技术解析与实现
# 1. 文本生成与神经网络简介
## 1.1 文本生成与神经网络的融合
文本生成是计算机科学中的一个领域,它涉及到利用计算模型自动生成连贯、有意义的文本。这不仅是一种有趣的人工智能展示,还是一种实际应用广泛的工具。文本生成的需求可以在多个领域找到,比如自动聊天机器人、机器翻译、语音识别和语言模型等。神经网络,特别是深度学习模型,已经成为实现高级文本生成的关键技术。
## 1.2 神经网络在文本生成中的角色
神经网络是一类受人脑工作方式启发而设计的算法模型。它们在处理非结构化数据(如文本)时显示出出色的能力。神经网络模型可以学习复杂的模式和语言的语义、句法结构,使得它们非常适合用于文本生成。随着计算机计算能力的增强和算法的进步,这些模型在文本生成方面的表现越发出色。
## 1.3 文本生成面临的挑战
尽管神经网络在文本生成方面取得了进展,但仍面临若干挑战。例如,生成的文本有时可能不连贯,缺乏人类语言的丰富性和多样性。模型可能难以处理长篇文本中的上下文依赖问题,也就是说,它可能难以捕捉到长距离的依赖关系。此外,训练大型神经网络需要大量计算资源和高质量的数据集,这也带来了挑战。因此,不断优化神经网络的架构和训练技巧,是当前研究的热点。
# 2. 循环神经网络(RNN)基础与实践
## 2.1 RNN的基本概念与数学原理
### 2.1.1 RNN的结构与工作方式
循环神经网络(RNN)是专为处理序列数据而设计的神经网络类型。在RNN中,网络有一个隐藏状态,这个隐藏状态会传递到下一个时间步,这种结构使其能够维持对之前信息的记忆。数学上,RNN的这种递归性质可以通过以下等式来描述:
\[h_t = f(h_{t-1}, x_t)\]
其中,\(h_t\) 是当前时间步的隐藏状态,\(f\) 表示激活函数,通常为tanh或ReLU,\(x_t\) 是当前时间步的输入,\(h_{t-1}\) 是前一个时间步的隐藏状态。这种依赖于前一状态的特性使得RNN能够处理时间序列数据。
### 2.1.2 时间序列数据与序列建模
时间序列数据是按时间顺序排列的数据点的集合,如股票价格、天气记录等。序列建模的目的是预测或生成未来的数据点。RNN通过共享参数来处理不同时刻的输入,使其在序列建模任务中特别有效。RNN的隐藏层可以视作一个简化的动态系统,能够模拟时间序列数据的动态特性。
在代码层面,RNN的实现需要定义隐藏状态和更新规则,下面是一个简单的RNN前向传播的伪代码:
```python
def simple_rnn_cell(input, hidden_prev, W_xh, W_hh, b_h):
hidden_now = tanh(dot(W_xh, input) + dot(W_hh, hidden_prev) + b_h)
return hidden_now
```
这段代码展示了单个时间步的RNN单元的操作。`input` 是当前时间步的输入向量,`hidden_prev` 是前一个时间步的隐藏状态向量,`W_xh` 和 `W_hh` 分别是输入到隐藏状态和隐藏状态到隐藏状态的权重矩阵,`b_h` 是偏置项。tanh函数作为激活函数,用于引入非线性。
## 2.2 RNN在文本生成中的应用
### 2.2.1 文本数据的预处理与向量化
在文本生成任务中,首先需要将文本数据预处理成适合神经网络处理的格式。文本预处理一般包括分词(tokenization)、去除停用词、词干提取等步骤。之后,通过词嵌入(word embeddings)将词汇转换成向量。常用词嵌入有Word2Vec、GloVe等。
向量化完成后,每个词被转换为固定长度的向量,这些向量随后被输入到RNN模型中。在编码器-解码器(Encoder-Decoder)框架中,编码器负责理解输入序列,解码器则负责生成输出序列。
### 2.2.2 利用RNN实现简单文本生成
利用RNN进行文本生成,通常会通过训练一个基于字符或词的模型来预测下一个字符或词。模型训练好之后,可以通过给定一个初始序列,然后让模型逐步生成后续的文本。
文本生成的伪代码示例:
```python
for i in range(max_length):
next_char = model.sample(hidden_state)
hidden_state = model.update_hidden(hidden_state, next_char)
generated_text.append(next_char)
```
这里,`model.sample` 方法负责根据当前的隐藏状态生成下一个字符,并更新隐藏状态。通过这种方式,可以不断生成新的字符,形成一段文本。
## 2.3 RNN的缺陷与优化策略
### 2.3.1 长期依赖问题的探索
虽然RNN理论上可以维持长期依赖关系,但实际上由于梯度消失或梯度爆炸的问题,RNN难以学习到时间间隔较长的数据点之间的依赖关系。这种现象在处理长序列时尤为明显,被称为长期依赖问题。
为了解决这个问题,研究人员提出了长短期记忆网络(LSTM)和门控循环单元(GRU),它们通过引入门控机制,可以更好地控制信息的流动,从而缓解长期依赖问题。
### 2.3.2 提高RNN性能的技巧
为了提高RNN在文本生成等任务上的性能,可以采取多种策略,例如:
- 使用双向RNN(BiRNN)来同时处理前文和后文信息。
- 对模型进行正则化,比如dropout,以防止过拟合。
- 调整学习率和优化算法,如使用Adam优化器。
- 使用预训练的词嵌入来提高模型在特定任务上的表现。
- 应用注意力机制(Attention Mechanism)以允许模型在生成文本时关注输入序列的特定部分。
通过这些技巧的运用,可以优化RNN模型,提高其对长期依赖问题的处理能力,并提升其在具体任务上的表现。
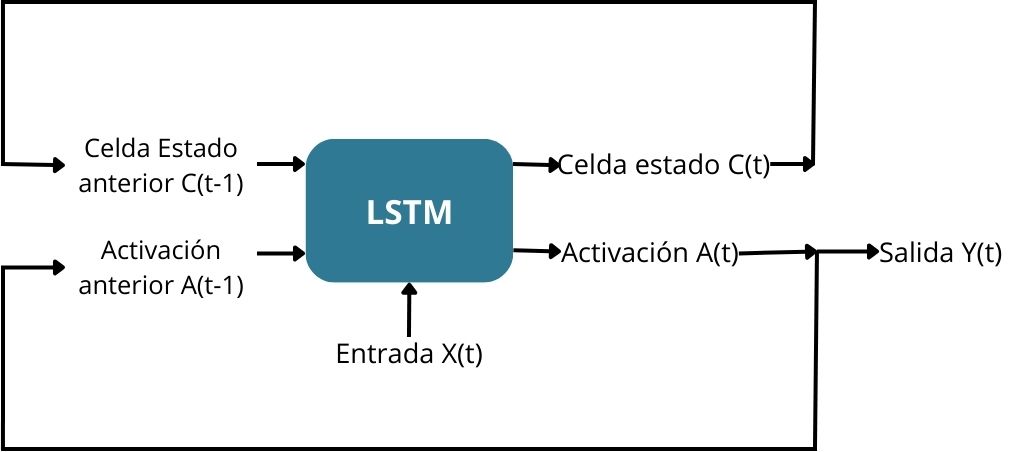
# 3. 长短期记忆网络(LSTM)与门控循环单元(GRU)
长短期记忆网络(LSTM)和门控循环单元(GRU)是循环神经网络(RNN)的两种变体,它们被设计用来解决传统RNN难以处理的长期依赖问题。LSTM通过引入“门”的概念来控制信息的流入和流出,而GRU则是对LSTM的一种简化,旨在减少参数的数量以提高效率。在本章中,我们将深入了解LSTM和GRU的工作原理,探讨它们在复杂文本生成中的应用,并比较它们的性能,以帮助读者做出更好的选择。
## 3.1 LSTM与GRU的原理与特点
### 3.1.1 LSTM单元结构详解
LSTM的核心思想是通过精心设计的门机制来调节信息的保留与遗忘。LSTM单元包含三个主要的门结构:遗忘门、输入门和输出门。
- **遗忘门** 决定应该保留或丢弃哪些信息。它通过当前输入和上一状态来计算一个0到1之间的值,表示要遗忘的信息比例。
- **输入门** 控制新的输入信息有多少会被加到单元状态中。同样,输入门使用当前输入和上一状态来确定哪些新信息是重要的。
- **输出门** 决定单元状态中的哪些信息将被用作输出。通常,输出是基于单元状态经过一个tanh函数后的结果。
LSTM单元的状态能够保持不变,或根据输入数据和门的控制来更新。这一设计使得LSTM在处理序列数据时,能够有效地保留长距离的依赖关系。
### 3.1.2 GRU与LSTM的比较分析
GRU是LSTM的一个简化版本,它通过合并遗忘门和输入门到一个“更新门”,并将单元状态和隐藏状态合并,来减少参数数量和简化计算。具体来说,GRU只包含两个门结构:重置门和更新门。
- **更新门** 决定保留多少历史信息,以及接受多少新信息。
- **重置门** 控制在将新信息传递到隐藏状态之前,当前输入能够多大程度上影响隐藏状态。
GRU的这些设计在许多任务中与LSTM性能相当,但参数更少,因此训练更快,内存占用更小。
## 3.2 LSTM和GRU在复杂文本生成中的应用
### 3.2.1 构建LSTM模型进行文本生成
LSTM模型由于其对长期依赖的良好处理能力,非常适合用于文本生成任务。在构建LSTM文本生成模型时,我们需要对文本进行向量化,然后设计一个能够处理这种序列数据的网络结构。
以下是一个简单的LSTM模型的构建流程:
```python
import torch
import torch.nn as nn
# 定义LSTM模型
class LSTMTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super(LSTMTextGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
output, hidden = self.lstm(x, hidden)
output = self.fc(output)
return output, hidden
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(1, batch_size, self.lstm.hidden_size).zero_(),
weight.new(1, batch_size, self.lstm.hidden_size).zero_())
return hidden
```
在这个模型中,`vocab_size`是词汇表的大小,`embedding_dim`是嵌入层的维度,`hidden_dim`是LSTM层的隐藏状态维度,`num_layers`是LSTM层的层数。模型的前向传播函数接收输入序列和一个隐藏状态,返回输出序列和新的隐藏状态。
### 3.2.2 实现GRU网络处理序列数据
构建一个基于GRU的文本生成模型与LSTM类似,主要区别在于网络中使用的层是GRU层而不是LSTM层。以下是GRU模型的构建示例:
```python
class GRUTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super(GRUTextGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.gru = nn.GRU(embedding_dim, hidden_dim, num_layers)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
output, hidden = self.gru(x, hidden)
output = self.fc(output)
return output, hidden
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = weight.new(1, batch_size, self.gru.hidden_size).zero_()
return hidden
```
在这个GRU模型中,我们使用了`nn.GRU`层来替换`nn.LSTM`层,并相应地调整了模型的初始化方法。
## 3.3 LSTM与GRU的性能比较与选择
### 3.3.1 不同场景下的模型性能评估
在选择使用LSTM还是GRU时,通常需要根据具体应用场景和性能要求进行考量。LSTM由于有更多的参数和复杂的门结构,在某些任务中可能能提供更复杂的建模能力,但这通常以更高的计算成本为代价。相反,GRU由于参数更少,在训练数据有限的情况下可能有更好的泛化能力,并且在速度上可能更优。
### 3.3.2 模型选择的考量因素
选择LSTM或GRU模型时,有几个关键因素需要考虑:
- **数据集的大小**:对于较小的数据集,GRU可能更适用。
- **训练资源**:LSTM由于参数更多,需要更多的训练资源。
- **任务的复杂度**:在需要捕捉复杂依赖关系的任务中,LSTM可能更胜一筹。
- **性能需求**:如果对模型的速度和内存占用有特殊要求,GRU可能是更好的选择。
在实际应用中,建议根据任务需求和可用资源进行实验,以确定哪种模型在给定场景中表现最佳。在某些情况下,甚至可以尝试混合使用LSTM和GRU层,以结合两者的优点。
接下来的章节将深入探讨Transformer模型以及其在文本生成中的应用。此外,我们还将探讨如何利用PyTorch框架进行模型实现,并提供一些高级技巧和性能优化策略。
# 4. Transformer模型的革命性突破
Transformer模型自2017年被提出以来,已经在自然语言处理(NLP)领域引发了革命性变革。其对自注意力机制的创新应用,颠覆了传统的序列处理方式,带来了性能上的显著提升。本章我们将深入探讨Transformer模型的内部结构与工作机制,探索其在文本生成中的实际应用,并对基于Transformer的扩展模型如BERT、GPT进行比较分析。
## 4.1 Transformer的结构与工作机制
Transformer模型的核心在于自注意力(Self-Attention)机制,它使得模型在处理序列数据时能够同时关注输入序列中的所有元素,并根据它们之间的关系进行加权求和。这种机制为模型提供了并行处理的能力,并解决了传统RNN和LSTM在处理长序列时的梯度消失和梯度爆炸问题。
### 4.1.1 自注意力机制的原理
自注意力机制允许模型动态地对输入序列的不同位置赋予不同的权重,从而捕捉序列内部的依赖关系。它包括三个主要的权重矩阵:查询(Query)、键(Key)和值(Value)。对于序列中的每个元素,通过计算与其他所有元素的相似度(通过点积得到)来得到注意力分数。这些分数随后通过softmax函数进行规范化,以获得最终的注意力权重。
自注意力权重矩阵的计算可以表示为:
\[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\]
其中,$Q$、$K$、$V$分别代表查询、键、值矩阵,$d_k$是键向量的维度。
为了提高模型的表达能力,Transformer通过多头注意力(Multi-Head Attention)的方式扩展了自注意力,允许模型并行地学习多组查询、键、值权重矩阵。
### 4.1.2 Transformer的核心组件解析
Transformer模型由多个编码器(Encoder)和解码器(Decoder)层堆叠而成。每个编码器和解码器层都包含了多个子层,其中包括多头自注意力机制和前馈神经网络。
- **编码器层**:每个编码器层有两部分组成,即自注意力层和前馈神经网络。自注意力层使模型能够关注输入序列的不同部分,前馈神经网络则在编码后的序列上应用非线性变换。
- **解码器层**:解码器层的结构更为复杂,它不仅包括自注意力层和前馈神经网络,还有一个额外的编码器-解码器注意力层。这个注意力层允许解码器在生成每个元素时,根据编码器的输出来聚焦于不同的输入部分。
Transformer模型还引入了位置编码(Positional Encoding)来注入序列元素的位置信息,因为原始的自注意力机制是无序的,不能区分序列元素的相对或绝对位置。
## 4.2 Transformer在文本生成中的应用
Transformer模型的提出对文本生成任务产生了深远的影响,特别是其后继模型如GPT和BERT,在各类文本生成任务上都取得了突破性的成果。
### 4.2.1 利用Transformer构建文本生成模型
构建基于Transformer的文本生成模型通常包括以下步骤:
1. **数据预处理**:对文本数据进行分词、编码,转换为模型可以处理的数值形式。
2. **模型设计**:设计模型架构,包括确定编码器和解码器的数量、隐藏层大小、注意力头的数量等参数。
3. **模型训练**:使用大量文本数据进行训练,使用交叉熵损失函数,通过梯度下降等优化算法更新模型参数。
4. **生成策略**:训练完成后,模型可以根据前文生成后续文本。常用的方法有贪婪搜索、束搜索(Beam Search)等。
一个简单的Transformer模型实现示例如下:
```python
import torch
import torch.nn as nn
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
from torch.nn import TransformerEncoder, TransformerEncoderLayer
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
```
### 4.2.2 模型的训练与调优策略
在训练Transformer模型时,可以采用多种策略来提高模型的性能:
- **学习率调度**:在训练过程中动态调整学习率,例如使用Transformer的原论文中提出的热身(warm-up)学习率策略。
- **权重衰减**:通过权重衰减正则化来防止过拟合。
- **数据预处理和增强**:通过更复杂的分词和数据增强技术提高模型的泛化能力。
- **早停法(Early Stopping)**:防止过拟合,当验证集的性能不再提升时停止训练。
- **集成学习**:训练多个模型并集成它们的输出,以提高预测的稳定性。
## 4.3 Transformer的优化与扩展模型
随着Transformer模型的普及,其基础架构也被不断优化和扩展,形成了众多变体,如BERT、GPT等,它们在文本生成及其他NLP任务上取得了惊人的成绩。
### 4.3.1 Bert、GPT等模型的演进
BERT(Bidirectional Encoder Representations from Transformers)通过预训练和微调的方式显著提升了模型在多项NLP任务上的性能。其关键在于使用了掩码语言模型(Masked Language Model, MLM)作为预训练任务,这种预训练方式能够让模型更深入地理解语言的双向上下文。
GPT(Generative Pretrained Transformer)则采用单向的语言模型作为预训练任务,通过从左到右的生成方式来训练模型。GPT系列模型在文本生成任务上表现出色,能够生成连贯、一致的文本。
### 4.3.2 对比不同模型的生成效果
在进行模型选择时,应考虑以下因素:
- **数据量和计算资源**:BERT类模型需要大量的计算资源进行预训练,而GPT类模型在生成时更耗资源。
- **任务类型**:某些任务可能更适合双向上下文理解(BERT),而其他如文本生成任务,则可能更适合单向的预测(GPT)。
- **性能与资源权衡**:选择模型时,需要平衡模型的性能和可用资源。
| 模型 | 优点 | 缺点 |
|--------|--------------------------------------|--------------------------------------|
| BERT | 双向理解能力强,适用多种NLP任务 | 需要大规模预训练,计算资源消耗大 |
| GPT | 在文本生成任务上表现出色 | 单向生成可能导致上下文理解不如BERT |
| RoBERTa | 提高了BERT的性能,增加了训练数据量和训练时长 | 计算资源消耗更大,训练时间长 |
| T5 | 统一了不同的NLP任务到一个文本到文本的框架 | 计算资源消耗大,训练复杂度高 |
在文本生成任务中,模型的性能通常通过BLEU、ROUGE等评估指标来衡量,这些指标可以反映出生成文本与参考文本之间的相似度。
```mermaid
graph LR
A[文本生成任务] --> B[模型选择]
B --> C[BERT]
B --> D[GPT]
B --> E[RoBERTa]
B --> F[T5]
C --> G[双向理解, 多任务适用]
D --> H[文本生成, 单向生成]
E --> I[高计算资源消耗]
F --> J[统一框架, 计算复杂度高]
```
通过对比不同模型的生成效果,我们可以根据具体任务需求、计算资源和性能要求,选择最合适我们的模型。
以上对Transformer模型进行了深入的分析,从其工作机制、在文本生成中的应用,到优化与扩展模型的演进。这一章节内容为读者提供了全面的视角,不仅包括理论分析,还有实际的模型实现代码和比较分析表格,有助于IT行业的专业人士深入理解并应用最新的人工智能技术。
# 5. PyTorch框架下的实现与优化
## 5.1 PyTorch基础及其在文本生成中的作用
### 5.1.1 PyTorch框架概述
PyTorch是一个开源的机器学习库,它由Facebook的AI研究团队开发,用于计算机视觉和自然语言处理领域的研究和开发。PyTorch的核心设计哲学是追求灵活性和易用性,它提供了一种称为"动态计算图"(Dynamic Computational Graph)的技术,能够允许研究人员和开发者以更加直观和动态的方式定义模型的结构和运行时的前向传播逻辑。
PyTorch的主要特点如下:
- **易用性**:它提供了高层API,对新手友好,也允许用户能够深入自定义模型。
- **动态计算图**:通过即时(Just-In-Time,JIT)编译,可实现更为灵活和直观的代码编写。
- **多GPU支持**:PyTorch允许在多个GPU上高效地训练模型,并支持分布式数据并行(Distributed Data Parallel, DDP)。
- **社区与生态**:PyTorch拥有一个活跃的开发者社区,拥有大量的教程、工具和扩展库。
### 5.1.2 PyTorch数据加载与预处理
在文本生成中,数据预处理是至关重要的步骤,因为其决定了模型能否学习到有意义的特征。PyTorch提供了一系列工具来帮助我们高效地处理文本数据。
一个典型的数据预处理流程包括:
- **分词(Tokenization)**:将文本分割成单个有意义的单元(通常是单词或者字符)。
- **编码(Encoding)**:将分词后的文本转换成整数或浮点数的数值表示,例如使用词嵌入(Word Embeddings)。
- **批处理(Batching)**:将文本组织成批次(Batch),以便于模型能够同时处理多个数据点。
- **填充(Padding)**:对于长度不同的文本数据,使用填充(Padding)操作使它们具有相同的长度。
PyTorch的数据加载器(DataLoader)能够自动化以上步骤,与Dataset类配合使用,可以方便地实现数据的加载和预处理。接下来将通过代码实例展示这一过程。
```python
import torch
from torch.utils.data import Dataset, DataLoader
class TextDataset(Dataset):
def __init__(self, texts, tokenizer, max_length):
self.texts = texts
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
encoding = self.tokenizer(text, padding='max_length', truncation=True, max_length=self.max_length, return_tensors='pt')
return encoding['input_ids'].squeeze(), encoding['attention_mask'].squeeze()
# 示例文本列表和分词器
texts = ['This is an example', 'Text generation is fun']
tokenizer = ...
# 实例化数据集
dataset = TextDataset(texts=texts, tokenizer=tokenizer, max_length=512)
# 加载数据
data_loader = DataLoader(dataset, batch_size=2, shuffle=True)
```
在上述代码中,我们首先定义了一个继承自`Dataset`的类,用于封装文本数据和处理逻辑。通过实例化`TextDataset`,我们创建了一个数据集,然后使用`DataLoader`来高效地加载和批处理数据,使其适用于模型训练。
## 5.2 PyTorch实现文本生成模型的步骤
### 5.2.1 定义网络结构与前向传播
定义一个文本生成模型通常涉及到构建一个神经网络,其负责处理输入文本,并生成预测输出。在PyTorch中,我们通过继承`nn.Module`类来定义自己的模型结构。
以下是一个简单的循环神经网络(RNN)文本生成模型的定义示例:
```python
import torch.nn as nn
class RNNTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(RNNTextGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
output, hidden = self.rnn(x, hidden)
output = self.fc(output)
return output, hidden
# 假设我们有词汇表大小为10000,嵌入维度为256,隐藏层维度为512
vocab_size = 10000
embedding_dim = 256
hidden_dim = 512
model = RNNTextGenerator(vocab_size, embedding_dim, hidden_dim)
```
在这个例子中,模型首先使用`Embedding`层将输入的文本索引映射到向量空间,然后一个`RNN`层用来处理序列数据,最后通过一个全连接层`Linear`输出最终的预测结果。
### 5.2.2 实现训练循环与验证流程
在定义了模型结构之后,接下来需要实现训练循环。训练循环包括前向传播、计算损失、反向传播以及参数更新等步骤。
以下是使用PyTorch实现模型训练过程的一个基本示例:
```python
import torch.optim as optim
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train()
total_loss = 0
for inputs, targets in data_loader:
optimizer.zero_grad()
# 前向传播
output, hidden = model(inputs, None)
loss = criterion(output.transpose(1, 2), targets)
# 反向传播和优化
loss.backward()
optimizer.step()
total_loss += loss.item()
# 打印平均损失
avg_loss = total_loss / len(data_loader)
print(f'Epoch {epoch+1}, Average Loss: {avg_loss}')
```
在上面的代码中,我们首先定义了一个交叉熵损失函数(`CrossEntropyLoss`),和一个Adam优化器(`Adam`)。然后,我们在一个指定的周期数(`num_epochs`)内运行训练循环,其中包含了对输入数据的批处理处理,前向传播计算输出,损失计算,反向传播梯度更新,以及每轮的平均损失打印。
## 5.3 PyTorch中的高级技巧与性能优化
### 5.3.1 使用PyTorch工具进行模型优化
随着研究的深入,模型变得越来越复杂,计算需求也越来越大。PyTorch提供了多种工具来帮助进行模型优化,例如:
- **梯度裁剪(Gradient Clipping)**:防止在训练过程中梯度爆炸的问题,保证模型稳定收敛。
- **学习率调度(Learning Rate Scheduling)**:通过调整学习率,如使用余弦退火等策略,提高模型训练效率。
- **混合精度训练(Mixed Precision Training)**:结合fp16和fp32精度的计算,减少内存使用和提高训练速度。
下面是一个使用学习率调度器的示例:
```python
from torch.optim.lr_scheduler import LambdaLR
# 定义一个学习率衰减函数
def lr_lambda(epoch):
return 0.9 ** epoch
# 初始化学习率调度器
scheduler = LambdaLR(optimizer, lr_lambda)
# 在训练循环中使用调度器
for epoch in range(num_epochs):
model.train()
for inputs, targets in data_loader:
# ... 省略训练过程的其它部分 ...
# 更新学习率
scheduler.step()
```
### 5.3.2 性能监控与调参策略
为了进一步优化模型性能,监控和调参是必不可少的。PyTorch提供了`torch.cuda`库来帮助我们监控GPU使用情况,并通过调整参数进行性能调优。
以下是一个简单的性能监控和调参的示例:
```python
import torch.cuda
# 获取当前设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 将模型和数据移至GPU(如果可用)
model.to(device)
inputs, targets = inputs.to(device), targets.to(device)
# 监控内存使用情况
max_memory = torch.cuda.max_memory_allocated()
print(f'Max memory allocated: {max_memory/1024**2:.2f} MB')
# 调整参数的策略包括但不限于:批处理大小、学习率、优化算法和模型结构等
```
在上述代码中,我们首先检查了是否可以使用GPU,并将模型和数据移动到GPU上(如果可用)。随后,我们使用`torch.cuda.max_memory_allocated()`函数监控GPU内存使用情况,这有助于我们了解在模型训练过程中内存的使用高峰。通过不断调整和测试不同的参数(例如批处理大小、学习率等),我们可以找到一个性能最优的配置。
通过PyTorch提供的这些工具和策略,开发者能够更加细致地管理和优化模型的训练过程,实现更高效率的文本生成模型开发。
# 6. 案例分析与未来展望
## 6.1 文本生成模型的实际应用案例
文本生成模型已经广泛应用于多个领域,从提供更加智能的用户体验,到为机器翻译和语言建模提供强有力的支持。接下来,我们将重点介绍两个具体的应用案例。
### 6.1.1 聊天机器人中的文本生成
聊天机器人在文本生成领域扮演了重要角色。随着自然语言处理技术的发展,聊天机器人已经能够理解并生成更加自然的对话文本。一个聊天机器人的实现,通常涉及到复杂的状态管理,以保证生成的回复是上下文相关的,并且能够处理用户提出的不同话题。
```python
# 示例代码:简单聊天机器人的实现
class ChatBot:
def __init__(self):
self.responses = {
"你好": "你好!有什么可以帮你的吗?",
"再见": "再见,有需要再来找我哦!",
# 更多上下文与回复的映射关系
}
def get_response(self, message):
# 基于预设的规则来获取回复
return self.responses.get(message, "对不起,我不明白你的意思。")
# 实例化并尝试对话
bot = ChatBot()
print(bot.get_response("你好"))
```
上述代码展示了如何构建一个非常基础的聊天机器人,其中使用了简单的映射关系来模拟对话。
### 6.1.2 机器翻译与语言模型的实际应用
机器翻译作为文本生成的一个重要应用领域,它通过分析源语言的文本并生成目标语言的文本,解决了跨语言的交流难题。高质量的机器翻译系统通常需要复杂的神经网络架构和大量的双语语料库进行训练。
```python
# 示例代码:利用已训练的语言模型进行翻译
# 注意:实际的机器翻译涉及到深层的模型训练和优化,这里仅提供一个概念性的示例
def translate_text(text, model):
# 这里的model是已经训练好的翻译模型
translated = model.translate(text)
return translated
# 假设有一个训练好的模型
trained_model = load_trained_translation_model()
input_text = "Hello, how are you doing today?"
translated_text = translate_text(input_text, trained_model)
print(translated_text)
```
## 6.2 神经网络在文本生成领域的挑战与机遇
### 6.2.1 面临的伦理、法律和技术问题
随着文本生成技术的不断进步,它所涉及的伦理和法律问题也日益凸显。例如,生成的文本可能被用于传播假新闻、侵犯版权或是进行不恰当的宣传等。技术上,确保模型的可靠性和安全性是目前研究的重点之一。
### 6.2.2 对未来文本生成技术的预测与展望
未来,文本生成模型可能会具有更强的上下文理解能力和创造能力,可以更准确地模仿人类的写作风格,甚至能够生成具有高度创造性、丰富情感和深度内容的文本。这将对内容创作、教育和娱乐等多个领域产生深远的影响。
此外,随着计算能力的提升和算法的优化,我们可能看到更加轻量级的模型部署在边缘设备上,实现即时、高效的文本生成服务。技术的不断演进将开启文本生成领域的全新篇章。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 PyTorch 为基础,深入探讨文本生成领域。它涵盖了从数据预处理和序列到序列学习到注意力机制和防止过拟合的各个方面。专栏还提供了有关 LSTM 网络、训练技巧、数据增强、并行计算和自注意力机制的详细指南。此外,它还探讨了文本生成模型的调优、案例研究和动态计算图的优势。通过一系列深入的文章和代码示例,本专栏为希望构建和优化文本生成模型的开发者提供了全面的指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SNAP自动化流程设计:提高备份效率的秘诀

# 摘要
SNAP备份技术作为一种数据备份解决方案,在保证数据一致性和完整性方面发挥着关键作用。本文全面概述了SNAP技术的基本概念、自动化流程的设计基础以及实现实践操作。文章不仅探
光学模拟原理:光源设定的物理学基础

# 摘要
本文从光学模拟的角度出发,对光源理论及其在光学系统中的应用进行了全面综述。首先介绍了光学模拟的基础知识和光源的基本物理特性,包括光的波粒二象性和光源模型的分类。随后,深入探讨了光学模拟软件的选用、光源模拟实验的设计、结果的验证与优化,以及在成像系统、照明设计和光学测量中的应用。文章还展望了新型光源技术的创新和发展趋势,特别是量子点光源与LED技术的进步,以及人工智能在光学模拟中的应
全球互操作性难题:实现不同MMSI编码表系统间的兼容性

# 摘要
本文系统性地探讨了MMSI编码表系统的基本概念、互操作性的重要性及其面临的挑战,并深入分析了理论框架下的系统兼容性。通过对现有MMSI编码表兼容性策略的研究,本文提出了实际案例分析及技术工具应用,详细阐述了故障排查与应对策略。最后,文章展望了MMSI系统兼容性的发展前景和行业标准的期待,指出了新兴技术在提升MMSI系统兼容性方面的潜力以及对行业规范制定的建议。
# 关键字
MMSI编
软件项目投标技术标书撰写基础:规范与格式指南

# 摘要
技术标书是软件项目投标中至关重要的文件,它详细阐述了投标者的项目背景、技术解决方案和质量保障措施,是赢得投标的关键。本文对技术标书的结构和内容规范进行了细致的分析,着重阐述了编写要点、写作技巧、案例和证明材料的利用,以及法律合规性要求。通过对标书的格式和排版、项目需求分析、技术方案阐述、风险评估及质量保障措施等方面的深入探讨,本文旨在提供一系列实用的指导和
FC-AE-ASM协议与容灾策略的整合:确保数据安全和业务连续性的专业分析

# 摘要
本文全面介绍了FC-AE-ASM协议的基本概念、特点及其在容灾系统中的应用。首先概述了FC-AE-ASM协议,接着详细探讨了容灾策略的基础理论,包括其定义、重要性、设计原则以及技术选择。第三章深入分析FC-AE-ASM协议在数据同步与故障切换中的关键作用。第四章通过实践案例,展示了如何将FC-AE-ASM协议与容灾策略结合起来,并详细阐述了实施过程与最佳实践。最后,文章展望了FC-AE-ASM与容灾策略的未来发展趋势,讨论了技
【PAW3205DB-TJ3T的维护和升级】:关键步骤助您延长设备寿命
# 摘要
本文全面介绍了PAW3205DB-TJ3T设备的维护与升级策略,旨在提供一套完善的理论知识和实践步骤。通过分析设备组件与工作原理,以及常见故障的类型、成因和诊断方法,提出了有效的维护措施和预防性维护计划。同时,详细阐述了设备的清洁检查、更换耗材、软件更新与校准步骤,确保设备的正常运行和性能维持。此外,本文还探讨了设备升级流程中的准备、实施和验证环节,以及通过最佳实践和健康管理延长设备寿命的策略。案例研究部分通过实际经验分享,对维护和升级过程中的常见问题进行了澄清,并对未来技术趋势进行展望。
# 关键字
设备维护;升级流程;故障诊断;健康管理;最佳实践;技术趋势
参考资源链接:[P
【Simulink模型构建指南】:实战:如何构建精确的系统模型
# 摘要
本文全面探讨了Simulink模型的构建、高级技术、测试与验证以及扩展应用。首先介绍了Simulin
【拥抱iOS 11】:适配中的旧设备兼容性策略与实践
# 摘要
随着iOS 11的发布,旧设备的兼容性问题成为开发者面临的重要挑战。本文从理论与实践两个层面分析了旧设备兼容性的基础、技术挑战以及优化实践,并通过案例研究展示了成功适配iOS应用的过程。本文深入探讨了iOS系统架构与兼容性原理,分析了性能限制、硬件差异对兼容性的影响,提供了兼容性测试流程和性能优化技巧,并讨论了针对旧设备的新API应用和性能提升方法。最后,文章对未来iO
【PetaLinux驱动开发基础】:为ZYNQ7045添加新硬件支持的必备技巧

# 摘要
本文旨在为使用ZYNQ7045平台和PetaLinux的开发人员提供一个全面的参考指南,涵盖从环境搭建到硬件驱动开发的全过程。文章首先介绍了ZYNQ7045平台和PetaLinux的基本概念,随后详细讲解了PetaLinux环境的搭建、配置以及系统定制和编译流程。接着,转向硬件驱动开发的基础知识,包括驱动程序的分类、Linux内核模块编
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )