Kafka Connect实战攻略:数据集成与扩展的5个实用技巧
发布时间: 2024-12-14 12:05:09 阅读量: 1 订阅数: 3 

Kafka急速入门与实战.doc
参考资源链接:[Kafka权威指南:从入门到部署详解](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f68?spm=1055.2635.3001.10343)
# 1. Kafka Connect简介与架构理解
Kafka Connect是Apache Kafka的一个子项目,旨在简化与外部系统进行数据集成的过程。它提供了一套可扩展且可靠的解决方案,以支持不同数据源之间的无缝连接。作为Kafka生态中用于连接器(Connectors)的框架,Kafka Connect使得数据从外部系统流入Kafka或从Kafka流出到其他系统成为可能。
## Kafka Connect的基本概念
在深入探讨架构之前,首先需要了解几个核心概念:
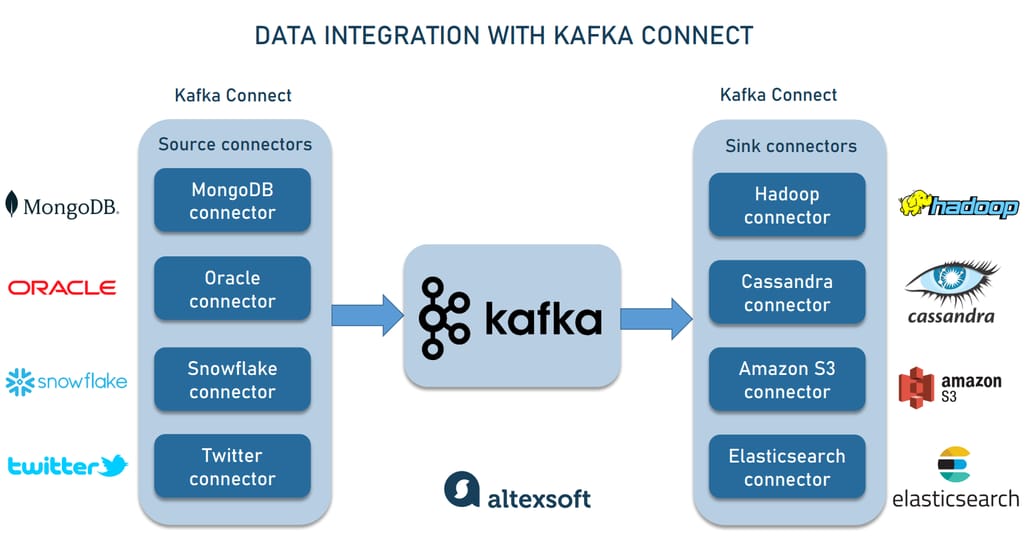
- **连接器(Connectors)**:连接器是连接Kafka与外部数据源的关键组件,它们定义了如何与特定数据源或目标系统交互。连接器可以分为源连接器(source connectors)和汇连接器(sink connectors),分别负责数据流入和流出。
- **任务(Tasks)**:连接器负责定义工作单元,而任务则是在集群中执行这些工作单元的具体实例。任务是不可变的,并且能够在不同的工作节点间迁移。
- **工作者(Workers)**:工作者是运行连接器和任务的进程。它们在集群模式下运行,提供高可用性和可扩展性。
## Kafka Connect的架构
Kafka Connect的架构设计使得其既适用于轻量级单节点场景,也适用于需要高吞吐量和高可靠性的分布式集群场景。
- **单节点模式**:在这种模式下,一个Kafka Connect进程负责整个连接器的生命周期,包括任务的分配和执行。这种方式适合轻量级任务或测试环境。
- **分布式模式**:分布式模式由多个工作者进程组成,可以自动并行处理数据。工作者之间通过REST API进行通信,因此可以很容易地横向扩展。在分布式模式中,连接器的定义被分发给所有工作者,而每个工作者自行决定如何处理任务。这种方式提高了系统的可靠性和容错性,同时允许动态地调整资源分配。
在这个架构的基础上,Kafka Connect还支持转换(Transformation)功能,允许在数据流入或流出Kafka时对其进行转换。转换可以在连接器配置中指定,或通过独立的转换器插件实现更复杂的处理逻辑。
理解了Kafka Connect的基本概念和架构之后,我们就可以进一步探讨如何进行安装配置、连接器的使用以及监控和故障排查等操作。在第二章中,我们将详细介绍Kafka Connect的安装步骤、配置选项以及连接器的分类和使用方法,为读者提供实用的入门指南。
# 2. Kafka Connect基础操作
## 2.1 Kafka Connect的安装与配置
### 2.1.1 安装Kafka Connect前的准备工作
安装Kafka Connect之前,需要确保已具备以下条件:
- 一个正在运行的Kafka集群,因为Kafka Connect依赖于Kafka的代理(broker)进行数据传输。
- Java开发工具包(JDK),版本至少为8,因为Kafka及Kafka Connect通常用Java编写。
- 运行Kafka的用户权限,因为安装和配置Kafka Connect通常需要在与Kafka集群相同的环境中进行。
准备工作完成后,接下来需要下载Kafka Connect的安装包。可以从Apache Kafka的官方下载页面获取与集群版本相匹配的Kafka Connect分发包。
### 2.1.2 Kafka Connect的配置选项解析
Kafka Connect提供了丰富的配置选项,可以在`connect-distributed.properties`文件中设置。以下是一些关键配置项的说明:
- `bootstrap.servers`: Kafka集群中至少一个代理(broker)的地址,Kafka Connect使用它来建立连接。
- `key.converter` 和 `value.converter`: 指定消息转换器的类,消息转换器用于转换接收到的消息格式。
- `offset.storage.topic`: Kafka Connect使用该主题存储其任务的偏移量,确保数据处理状态的持续性。
- `status.storage.topic`: 用于存储Kafka Connect任务状态信息的主题。
- `config.storage.topic`: 存储Kafka Connect任务配置信息的主题。
- `group.id`: Kafka Connect任务所属的消费者组ID。
除了以上配置项,还可以根据实际应用场景调整其他参数,如`buffer.memory`, `max.request.size`等,来优化Kafka Connect的性能。
## 2.2 Kafka Connect连接器的使用
### 2.2.1 连接器的分类与选择
Kafka Connect提供了两大类连接器:源连接器(source connector)和汇连接器(sink connector)。源连接器负责从外部系统导入数据到Kafka,而汇连接器则负责将数据从Kafka导出到外部系统。
选择连接器时,应考虑以下因素:
- 数据源类型:需要集成的数据来源或目标,例如数据库、文件系统、搜索引擎等。
- 数据格式:外部系统与Kafka之间的数据格式转换,如Avro、JSON等。
- 性能要求:数据传输的速度和稳定性,特别是在高负载场景下的表现。
- 扩展性:连接器是否支持可定制化扩展,以适应特定的集成需求。
- 社区支持和维护:选择广泛使用和支持的连接器,以便于问题解决和更新。
### 2.2.2 连接器的基本操作与示例
安装并配置好Kafka Connect后,可以开始连接器的操作。连接器通过REST API进行管理,以下是一个连接MySQL数据库作为数据源的示例步骤:
1. 启动Kafka Connect节点。
2. 创建一个新的源连接器配置文件,例如`mysql-source.properties`。
3. 配置必要的参数,如数据库连接信息、表名、Kafka主题等。
4. 通过REST API将配置文件发送给Kafka Connect节点,创建并启动连接器任务。
示例配置:
```properties
name=MySQLSourceConnector
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydatabase?user=root&password=pass
mode=bulk
table.whitelist=mytable
topic.prefix=mytopic_
```
通过上述步骤,可以将MySQL数据库中的数据实时同步到Kafka主题中。如果需要进一步操作,可以参考Kafka Connect的官方文档和连接器的特定使用说明。
## 2.3 Kafka Connect的监控与故障排查
### 2.3.1 监控Kafka Connect的性能与状态
监控是确保Kafka Connect稳定运行的关键。以下是推荐的监控指标和方法:
- **指标监控**:通过Kafka Connect暴露的JMX指标来监控连接器状态、任务进度、性能指标等。
- **日志监控**:定期检查日志文件,识别和分析错误、警告和异常信息。
- **Kafka集群监控**:使用如Kafka Manager、Prometheus等工具监控Kafka集群的状态和性能。
- **任务状态检查**:通过REST API获取任务的当前状态,以及失败任务的错误信息。
示例JMX指标查询:
```bash
curl -s http://localhost:8083/connectors/MySourceConnector/statistics | jq .
```
### 2.3.2 常见故障案例分析与解决
Kafka Connect在实际使用过程中可能会遇到各种问题,以下是一些常见的故障及其排查方法:
- **任务失败**:查看任务状态信息,找到失败原因。常见的失败原因为配置错误、数据源不可达、版本兼容性问题等。
- **性能瓶颈**:性能问题可能是由于连接器配置不当、硬件资源限制或者数据量过大导致。检查并优化配置项,如`batch.size`, `linger.ms`等。
- **同步延迟**:当Kafka Connect同步数据到目标系统时发生延迟,需要检查网络状况、目标系统的负载能力、连接器的批处理配置。
故障排查示例:
```bash
# 查看连接器状态
curl -s http://localhost:8083/connectors/MySourceConnector/status | jq .
```
如果遇到异常,则需要根据返回的错误信息进行问题定位。例如,如果遇到连接错误,检查数据库连接URL和认证信息是否正确。如果是因为性能问题,则需要调整相关性能参数,并观察指标变化。
### 检查硬件和系统资源使用情况
除了上述监控方法之外,使用系统监控工具(如`top`, `htop`, `iostat`, `free`等)来检查硬件和系统资源的使用情况,可以更好地理解Kafka Connect在系统中的表现。尤其注意CPU、内存和磁盘I/O的使用情况,以及网络吞吐量是否符合预期。
上述内容为Kafka Connect基础操作的详细介绍,包括安装配置、连接器使用以及监控与故障排查。通过这些信息,您可以更好地理解和应用Kafka Connect的基本功能,为后续的数据集成技巧和扩展应用打下坚实的基础。
# 3. Kafka Connect数据集成技巧
## 3.1 实现数据的实时集成
### 3.1.1 利用Kafka Connect实现数据流的实时同步
Kafka Connect作为一种用于高效地在Kafka与外部系统之间移动数据的工具,其最重要的优势之一便是提供实时数据集成的能力。实时数据集成涉及从源系统持续抓取数据并实时推送到Kafka主题,或者从Kafka主题实时流向目标系统。这使得数据可以以最小的延迟被其他应用程序所消费和处理。
数据流的实时同步需要关注的几个关键点包括:
- **连接器的性能**:选择高效的连接器,可以快速地处理数据,减少延迟。
- **分区与并行处理**:合理利用Kafka的分区特性,通过并行处理提高数据同步的吞吐量。
- **批处理大小与频率**:合适的批处理大小和频率可以平衡延迟与吞吐量,避免数据积压。
#### 示例:从数据库实时同步数据到Kafka
假设我们有一个MySQL数据库,我们希望将其中的订单数据实时同步到Kafka主题中,以便进行进一步的实时分析。
首先,我们需要使用Kafka Connect的JDBC连接器。配置文件`jdbc-source-connector.properties`可能包含如下配置:
```properties
name=M
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Kafka 权威指南 PDF》是一本全面深入的指南,涵盖了 Kafka 消息系统的各个方面。它从入门基础开始,逐步深入探讨 Kafka 的架构、性能优化、集群管理、故障排除、数据流处理、微服务集成、安全实践、数据集成和扩展、消费模型优化、生产者优化以及事务性消息处理等高级主题。该指南提供了大量实用的秘诀、技巧和最佳实践,帮助读者掌握 Kafka 的核心概念,并将其有效应用于实际场景中。无论是 Kafka 新手还是经验丰富的用户,都能从这本指南中获得宝贵的知识和见解。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
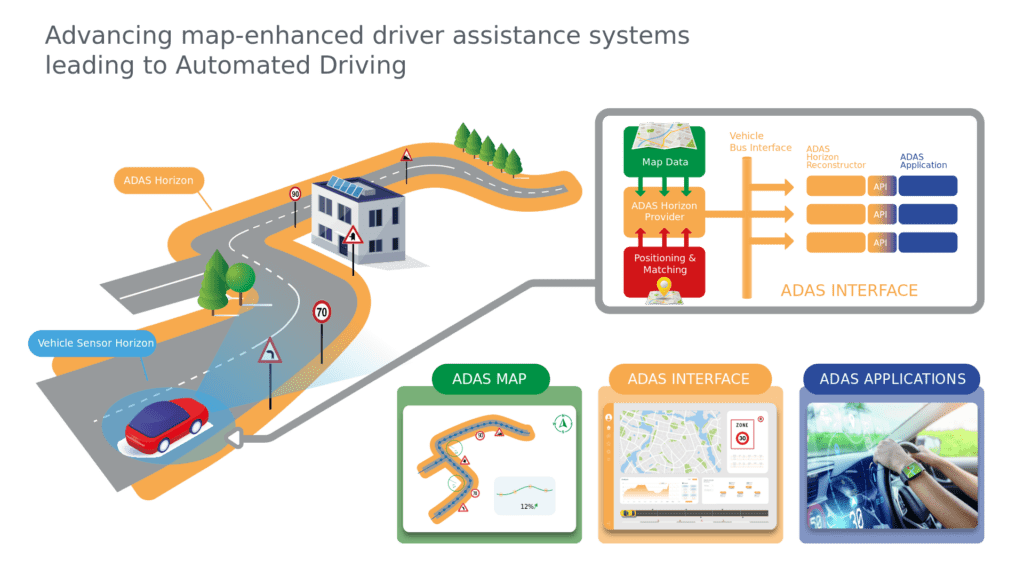
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )