Kafka消费模型深度解析:优化消费效率的5大策略
发布时间: 2024-12-14 12:10:43 阅读量: 1 订阅数: 3 
参考资源链接:[Kafka权威指南:从入门到部署详解](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f68?spm=1055.2635.3001.10343)
# 1. Kafka消费模型概览
Apache Kafka作为一个高性能的分布式消息系统,被广泛用于构建实时数据管道和流式应用程序。Kafka消费模型是其核心组成部分之一,它允许系统以可扩展、可靠的方式处理数据流。本章将对Kafka消费模型进行概览,为读者提供一个对后续内容的理解基础。
## Kafka消费者组的概念
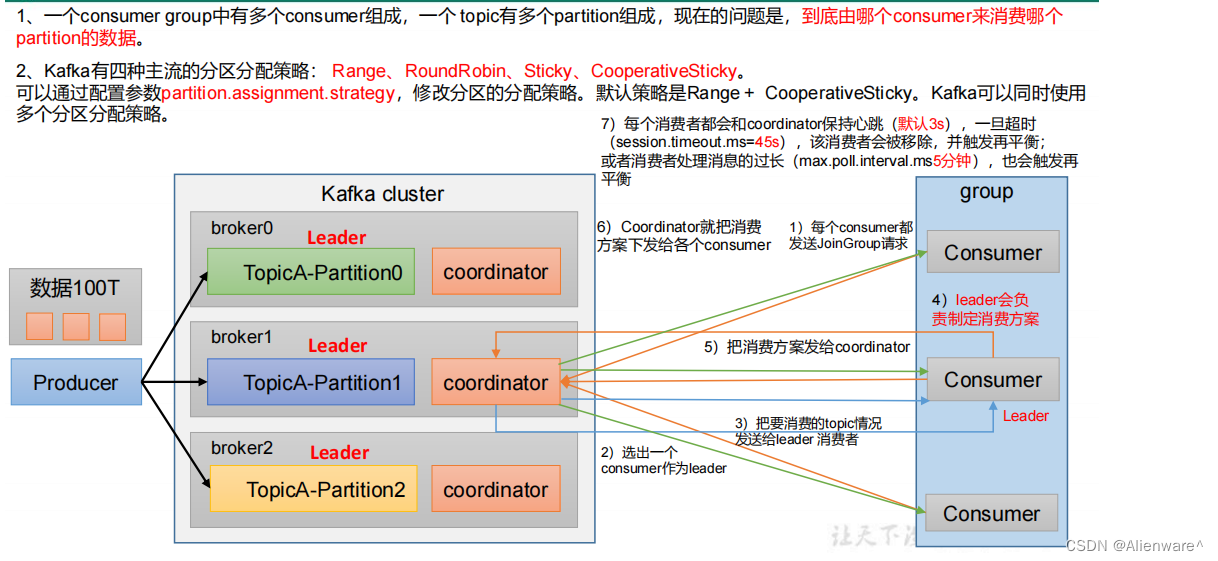
消费者组(Consumer Group)是Kafka中实现消息并行处理的抽象概念,它允许一组消费者协同工作处理多个分区中的数据。理解消费者与消费者组的关系,以及分区与消费者组的交互机制,是深入研究Kafka消费模型不可或缺的一环。
### 消费者与消费者组的关系
Kafka中的消费者是连接到消费者组的客户端实例。同一个消费者组内的消费者可以协作处理一个或多个主题的消息。当分区被分配给消费者组内的消费者时,每个分区只能被该组内的一个消费者读取,这样就保证了分区消息的有序消费。
### 分区与消费者组的交互机制
分区与消费者组的交互基于Kafka的Rebalance机制。当新增或移除消费者时,系统会重新分配分区到消费者组内的消费者,确保负载均衡。这个过程涉及到了消费者偏移量的维护和记录,对消费性能和数据一致性有直接影响。
接下来的章节将深入探讨Kafka消费模型的理论基础,以及如何优化消费效率,提高消息处理的性能。
# 2. Kafka消费模型理论基础
## 2.1 Kafka消费者组的概念
### 2.1.1 消费者与消费者组的关系
在Kafka中,消费者组(Consumer Group)的概念是实现消息并行消费的关键组件。消费者组由一个或多个消费者实例组成,这些消费者实例协作消费主题(Topic)中的消息。每个消费者实例可以在不同的机器上运行,也可以在同一台机器上运行多个实例。
当一个新的消费者加入到消费者组时,它会从消费者组协调器(Coordinator)那里获取到一个分区的列表,并开始从这些分区中拉取数据。如果消费者组中某个消费者发生故障,协调器会触发分区重新分配,将故障消费者所负责的分区交给其他存活的消费者处理,确保消息不丢失且只被处理一次。
消费与消费者组之间的关系可以用下表来表示:
| 关系特性 | 说明 |
| ---------------- | ------------------------------------------------------------ |
| 并行消费 | 同一消费者组内不同消费者可以同时消费不同分区的消息,实现高吞吐量。 |
| 分区独占性 | 同一消费者组内的不同消费者之间,不会消费同一分区的消息,保证了消息的有序消费。 |
| 故障转移 | 消费者发生故障时,消费者组能够自动进行故障转移,保证消费者的高可用性。 |
| 消费者扩展性 | 可以根据业务需要动态增加消费者数量,平滑提升消息处理能力。 |
| 消费者平衡负载 | 随着消费者组中的消费者数量变化,Kafka能够自动重新分配分区,实现负载均衡。 |
| 粒度调整灵活性 | 分区数的增加可以增加并行度,但需要权衡消费者组内的协调成本。 |
### 2.1.2 分区与消费者组的交互机制
分区是Kafka实现高吞吐量的核心,每个分区可以被消费者组中的不同消费者独立消费。消费者组通过与分区的交互机制实现了消息的并行消费和负载均衡。
在消费者组中,每个分区只能分配给组内的一个消费者实例消费,保证了分区内的消息顺序性。当消费者组中的消费者实例数量发生变化时(如增加或减少消费者实例),Kafka会自动进行分区重新分配(Rebalance)。这是一个动态的过程,分区会根据新的消费者数量重新进行分配,使得每个消费者实例都能均匀地获得一定数量的分区进行消费。
分区与消费者组的交互流程可以描述如下:
1. 消费者实例向Kafka集群注册,并声明它所属的消费者组。
2. Kafka的消费者协调器负责管理消费者组的状态,包括分区的分配。
3. 当消费者实例加入或离开消费者组时,协调器会触发一次分区再分配过程。
4. 消费者实例根据协调器返回的分区列表,开始从这些分区中拉取消息并进行消费。
5. 消费者实例会定期发送心跳(Heartbeat)给协调器,以表明自己的存活状态。
6. 当某个消费者实例无法再发送心跳(例如崩溃或网络故障),协调器会标记这个消费者实例为失效,并触发新的分区再分配。
这一交互机制确保了消费者组可以动态地调整其处理能力,以适应不断变化的负载需求。
## 2.2 消费者的拉取模型
### 2.2.1 拉取间隔与批量处理
Kafka的消费者拉取模型是指消费者从Kafka集群中获取数据的方式。该模型的核心是消费者控制数据的拉取频率和批量大小,也就是每次拉取多少数据以及多久拉取一次。
消费者的拉取间隔和批量处理有以下特点:
1. **拉取间隔(poll interval)**:消费者每次调用poll方法的间隔。这个间隔一般较短,通常几毫秒到几十毫秒。消费者可以在poll方法中设置最大拉取记录数`max.poll.records`,以控制一次拉取操作的最大消息数量。
2. **批量处理(batch processing)**:消费者在执行pull操作时,会将消息尽可能以最大的批量(batch size)进行拉取。批量拉取可以有效减少网络开销,提升消费性能。但过大的批量大小会导致更高的延迟,因为消费者必须等待足够的数据才进行下一次拉取操作。
3. **消费者配置**:批量处理的大小可以通过Kafka消费者配置`fetch.max.bytes`(一次fetch请求允许返回的最大数据量)、`fetch.min.bytes`(一次fetch请求需要从服务器获取的最小数据量)、`max.poll.records`来微调。
以下是一个配置批量处理的代码示例,以及对参数的逻辑分析:
```java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "example-group");
// 设置每次fetch请求的最大数据量
props.put("fetch.max.bytes", 52428800); // 50MB
// 设置一次fetch请求需要从服务器获取的最小数据量
props.put("fetch.min.bytes", 1);
// 设置单次poll方法调用返回的最大消息数量
props.put("max.poll.records", 500);
```
在上述配置中,`fetch.max.bytes` 参数指定了消费者从Kafka集群中一次性拉取的最大数据量。在每次轮询(poll)中,消费者会尝试获取至少 `fetch.min.bytes` 指定大小的数据,如果在达到 `max.poll.records` 指定的记录数之前,数据还没有达到这个大小,则会立即返回。这种方式可以平衡性能和延迟。
### 2.2.2 消费者偏移量管理
消费者偏移量(offset)是指消费者在每个分区中已经消费的记录的位置。消费者偏移量是Kafka保证消息消费顺序性的重要机制之一。
消费者偏移量的管理流程如下:
1. **记录偏移量**:消费者在拉取到一批消息后,会逐条处理这些消息。每处理一条消息,消费者会记录下该消息的偏移量,并将其存储在本地的offsets topic中。
2. **提交偏移量**:在一定条件下(如处理完一批消息、达到预设的时间间隔、或者手动调用commit方法),消费者会将当前批次的最后一个偏移量提交到Kafka,这样就算发生故障消费者重新加入到消费者组,也可以从偏移量记录的位置开始继续消费,而不会导致消息重复消费。
3. **检查点**:偏移量的记录和提交操作,形成了消费者的检查点(checkpoint)。如果消费者在处理一批消息时失败,下次可以从检查点恢复,继续消费未处理的消息。
消费者偏移量管理的一个代码示例如下:
```java
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理消息
processMessage(record);
// 手动提交偏移量
consumer.commitAsync();
}
}
```
在这段代码中,消费者每拉取到一批消息后进行处理,然后使用`commitAsync`方法异步提交偏移量。这种方式虽然可以提供更高的吞吐量,但有可能在发生故障时丢失少量未处理的消息。如果对消息准确性要求更高,可以选择同步提交偏移量。
## 2.3 消费延迟与背压问题
### 2.3.1 消费延迟产生的原因
消费延迟是指消费者在消费消息时,由于某些原因导致消息处理速度落后于消息的生产速度,从而导致消息积压的现象。
消费延迟产生的原因可能包括:
1. **处理能力不足**:消费者单条消息处理时间长,例如进行复杂的数据转换、大量的I/O操作、或者网络延迟等。
2. **硬件资源限制**:消费者所在服务器的CPU、内存、磁盘I/O等资源紧张,无法满足处理需求。
3. **消费者配置不当**:如`max.poll.records`设置过小,导致消费者频繁调用poll方法,增加了网络往返延迟;又如`fetch.min.bytes`设置过大,导致消费者需要等待较长时间才能拉取到足够的数据。
4. **高负载下的分区重分配**:在消费者组中,分区重分配(Rebalance)可能会导致消费者短时间内无法消费消息,造成延迟。
### 2.3.2 背压机制对消费效率的影响
背压(Backpressure)是指消费者在消费过程中,对消息流入速度的一种控制机制。Kafka中并没有内置的背压机制,但可以通过合理配置和程序设计实现背压的效果,以控制消息的消费效率。
实现背压的策略包括:
1. **动态调整拉取速率**:根据消费者的负载情况动态调整拉取间隔和批量大小,控制消息的流入速度。
2. **阻塞和非阻塞策略**:在消费者端实现阻塞和非阻塞策略,根据消费队列中的消息数量和处理速度,调整消息的拉取和处理行为。
3. **流控制(Flow Control)**:在一些高级消息处理框架中,可以使用流控制机制来实现背压,例如Apache Pulsar中的流控制机制。
背压机制能够防止消费者在处理能力不足时被压垮,从而保持系统的稳定性和可靠性。但是,实现背压需要对系统有较深入的理解,并且可能会牺牲一部分吞吐量以换取系统稳定性。
# 3. 优化消费效率的实践策略
在现代的分布式系统中,Kafka已经成为了消息队列和事件流处理的事实标准。随着企业业务量的激增,对Kafka的消费效率要求也越来越高。优化消费效率不仅可以提高数据处理速度,还能提升整体系统的稳定性和可靠性。本章将深入探讨如何通过调整消费者配置、改进消费者代码逻辑以及对消费者组的管理和监控来提升Kafka的消费效率。
## 3.1 调整消费者配置
Kafka的消费者配置对消费效率有着直接的影响。合理地调整这些配置,可以显著地提升消费者的性能。
### 3.1.1 max.poll.records与fetch.min.bytes参数
`max.poll.records`参数限制了每次轮询调用`poll()`方法时可以返回的最大记录数。这个值可以根据应用处理能力来调整。如果一次返回的消息过多,处理不过来,可以适当减少此值;如果消息处理能力足够强,可以适当增加以减少网络请求的次数。
`fetch.min.bytes`参数定义了消费者从服务器获取记录的最小数据量。增加这个值可以减少网络请求的次数,但是如果消息产生很慢,增加此值可能会导致消费者空闲等待的时间增加。
```java
Properties props = new Properties();
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "500"); // 设置每次轮询最多返回500条记录
props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, "102400"); // 设置最小的数据量为102400字节
```
以上代码展示了如何在Java消费者中设置这两个参数。配置后,消费者会在满足任一条件时触发下一次`poll()`调用。
### 3.1.2 heartbeat.interval.ms与session.timeout.ms参数
心跳机制用于检测消费者的健康状态,`heartbeat.interval.ms`参数定义了消费者向broker发送心跳的间隔。如果设置得过长,可能会导致在消费者宕机时,broker不能及时发现并进行负载均衡;如果设置过短,则会增加broker的处理负担。
`session.timeout.ms`参数定义了消费者被认为死亡前的不活动间隔。如果消费者在该时间内没有发送心跳,则会被认为是死亡,并触发重平衡。如果这个时间设置得太短,正常的网络延迟可能会导致错误的重平衡;如果设置得太长,可能会延迟故障的检测。
```java
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000"); // 设置会话超时时间为30秒
props.put(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Kafka 权威指南 PDF》是一本全面深入的指南,涵盖了 Kafka 消息系统的各个方面。它从入门基础开始,逐步深入探讨 Kafka 的架构、性能优化、集群管理、故障排除、数据流处理、微服务集成、安全实践、数据集成和扩展、消费模型优化、生产者优化以及事务性消息处理等高级主题。该指南提供了大量实用的秘诀、技巧和最佳实践,帮助读者掌握 Kafka 的核心概念,并将其有效应用于实际场景中。无论是 Kafka 新手还是经验丰富的用户,都能从这本指南中获得宝贵的知识和见解。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )