Kafka数据流处理进阶:掌握Kafka Streams的6个关键技巧
发布时间: 2024-12-14 11:51:14 阅读量: 3 订阅数: 3 

流式架构 Kafka与MapR Streams数据流处理
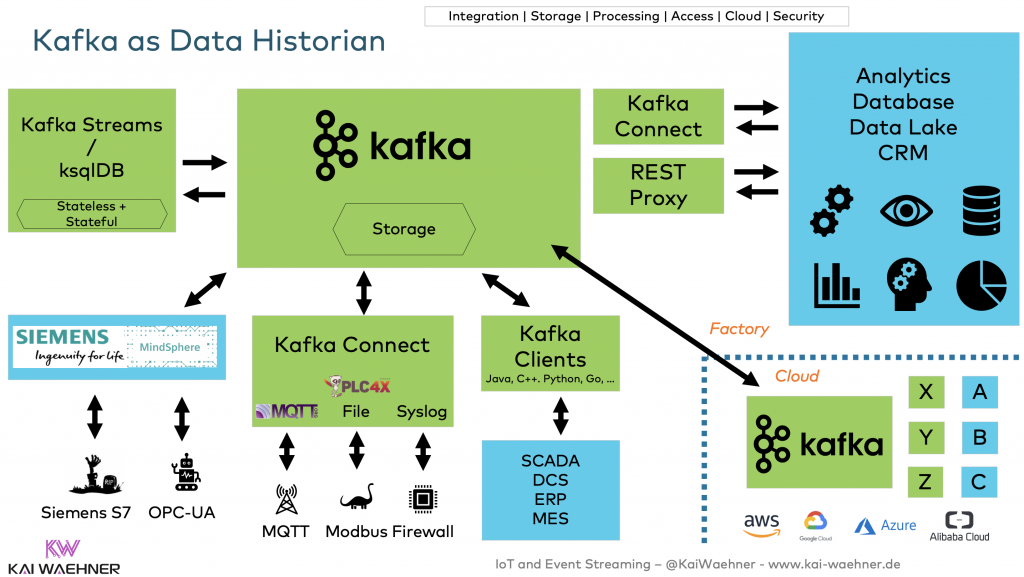
参考资源链接:[Kafka权威指南:从入门到部署详解](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f68?spm=1055.2635.3001.10343)
# 1. Kafka Streams概述
在大数据处理的生态系统中,Apache Kafka Streams是专为实时数据处理和流分析设计的客户端库。它简化了在Kafka上构建流处理应用程序的复杂性,允许开发者以声明式方式构建微服务,从而实现轻量级、可扩展的数据处理管道。
Kafka Streams可以无缝地与现有的Kafka集群集成,使得数据的摄入、处理和输出更为高效和可靠。它提供了丰富的API,从低级的处理器API到高级的KStream和KTable,使得开发者可以轻松实现复杂的数据流操作。
## 1.1 Kafka Streams的适用场景
Kafka Streams非常适合用于需要实时处理和分析数据流的场景,例如实时监控、日志处理、计数器和仪表板更新、实时ETL等。其易于使用的API和与Kafka的紧密集成,使得它成为处理实时数据流的理想选择。
# 2. Kafka Streams核心概念与架构
Kafka Streams 是一个用于构建实时流处理应用程序的客户端库。它建立在Apache Kafka的基础之上,提供了灵活且强大的编程模型来实现数据的处理和转换。在深入了解Kafka Streams之前,我们需要掌握它的核心概念和架构。
## 2.1 Kafka Streams的数据模型
在Kafka Streams中,数据模型主要由流(Stream)和表(Table)两种类型构成。这两个概念都是对Kafka中消息流(Topic)数据的抽象表示。
### 2.1.1 流和表的定义
流,也就是KStream,代表了一组无界、顺序的记录(Record)的集合。每一个记录由键(Key)、值(Value)、时间戳(Timestamp)和可选的窗口信息组成。流是Kafka Streams中最基础的数据结构,它相当于Kafka中一个Topic的数据流。
表,也就是KTable,代表了一个变更日志流的抽象表示。在Kafka Streams中,KTable可以被视为一个数据库表或者一个具有主键的数据集。KTable提供了记录的插入、更新和删除操作,其变化可以通过流的方式进行订阅。
在处理流数据时,流和表之间经常需要互相转换。例如,可以将KStream合并成一个KTable,或者将KTable流化为KStream。
### 2.1.2 分区和键的选择
在Kafka Streams中,数据模型的另一个重要概念是分区(Partition)。分区可以提供并行处理的能力,同时还能保证消息的有序性。在处理流数据时,选择合适的键(Key)是非常关键的,因为消息会根据键的哈希值分配到相应的分区中。
对于KStream来说,分区保证了数据在全局范围内的有序性。而对于KTable,分区保证了在每个键范围内的有序性,但是不同键的数据之间是没有顺序保证的。
合理地设置分区数量和选择键的策略对于系统性能和扩展性至关重要。在设计流处理应用程序时,要考虑到键的选择会影响数据如何分布以及后续的处理逻辑。
## 2.2 Kafka Streams的处理拓扑
Kafka Streams的处理逻辑是通过构建一个有向无环图(DAG)来实现的,这个图被称为处理拓扑(Topology)。拓扑定义了应用程序中数据流的流动路径以及处理的节点。
### 2.2.1 有状态和无状态操作
Kafka Streams中的操作可以分为有状态(stateful)和无状态(stateless)两种。有状态操作指的是那些需要维护状态信息的操作,比如窗口操作、聚合操作等。无状态操作则不需要维护状态,比如过滤操作、映射操作等。
在构建拓扑时,需要特别注意有状态操作。Kafka Streams会自动管理这些状态,但在发生故障时,状态的恢复是需要考虑的。因此,有状态操作通常需要额外的状态存储(State Store)来保证数据的一致性和可靠性。
### 2.2.2 多流和流的合并
在拓扑中,可以创建多个流的源(Source),并对这些流进行合并。合并操作允许将不同来源的数据整合在一起,进行进一步的处理。这在处理来自不同分区或主题的数据时非常有用。
例如,一个源流可能处理订单数据,另一个源流处理库存数据。通过KStream的合并操作,可以将这两种数据流整合起来,实现订单和库存的实时匹配。这种合并操作提供了高度的灵活性,让开发者可以根据不同的业务需求来设计处理流程。
## 2.3 Kafka Streams的事件时间处理
在流处理中,事件时间(Event Time)是区分系统处理时间和数据实际生成时间的一个重要概念。Kafka Streams允许用户以事件时间为基准来处理数据。
### 2.3.1 事件时间与处理时间的区别
事件时间是指事件实际发生的时间,而处理时间是事件被处理的时间。在流处理中,两者可能存在时间差。例如,一个事件可能在发生后数分钟甚至数小时后才被处理。
理解事件时间和处理时间的区别非常重要,因为在处理延迟和数据一致性的场景中,基于事件时间的处理可以提供更加准确的结果。Kafka Streams提供了丰富的工具来处理事件时间,包括时间戳的提取和时间窗口的定义。
### 2.3.2 时间窗口的使用和管理
时间窗口是流处理中一个常用的概念,它将连续的数据流分割成固定长度的时间段,然后对每个时间段内的数据进行处理。在Kafka Streams中,窗口可以基于事件时间或处理时间来定义。
在实际应用中,时间窗口使得开发者可以针对特定时间段内的数据进行聚合、连接或其它操作。使用窗口可以简化流处理逻辑,因为开发者不需要关心单个事件,而是关注于时间段内的数据集合。
Kafka Streams提供了两种时间窗口类型:滚动窗口(Tumbling Window)和滑动窗口(Sliding Window)。滚动窗口指的是每个窗口固定且互不重叠,而滑动窗口则可以根据需要进行重叠。开发者需要根据具体的应用场景来选择合适的窗口类型和窗口大小。
请继续阅读下一节:[2.1 Kafka Streams的数据模型](#21-kafka-streams的数据模型)。
# 3. Kafka Streams的高级编程技巧
在深入了解了Kafka Streams的基础知识和架构之后,我们现在将深入探讨高级编程技巧,这些技巧将帮助您在实际应用中提高Kafka Streams应用的性能和可靠性。本章节将重点介绍状态存储与恢复机制、时间管理和高效流处理及并行计算。
## 3.1 状态存储与恢复机制
Kafka Streams的一个主要特点是它能够处理和分析持续流入的数据流,而且为了提供复杂的数据处理功能,Kafka Streams引入了状态的概念。理解和运用状态存储对于编写可靠的流处理应用至关重要。
### 3.1.1 内置状态存储的原理
Kafka Streams提供了多种内置状态存储机制,其中包括:
- **本地状态存储**: 应用在本地磁盘上存储状态,适合不需要跨应用共享的状态。
- **远程状态存储**: 例如使用RockDB,它允许数据在本地磁盘上存储,并通过网络与其他进程共享。
状态存储通常是通过键值对的形式来维护数据的,它们可以被配置为可变或不可变。状态存储为流处理操作提供了高效的键查找

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Kafka 权威指南 PDF》是一本全面深入的指南,涵盖了 Kafka 消息系统的各个方面。它从入门基础开始,逐步深入探讨 Kafka 的架构、性能优化、集群管理、故障排除、数据流处理、微服务集成、安全实践、数据集成和扩展、消费模型优化、生产者优化以及事务性消息处理等高级主题。该指南提供了大量实用的秘诀、技巧和最佳实践,帮助读者掌握 Kafka 的核心概念,并将其有效应用于实际场景中。无论是 Kafka 新手还是经验丰富的用户,都能从这本指南中获得宝贵的知识和见解。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
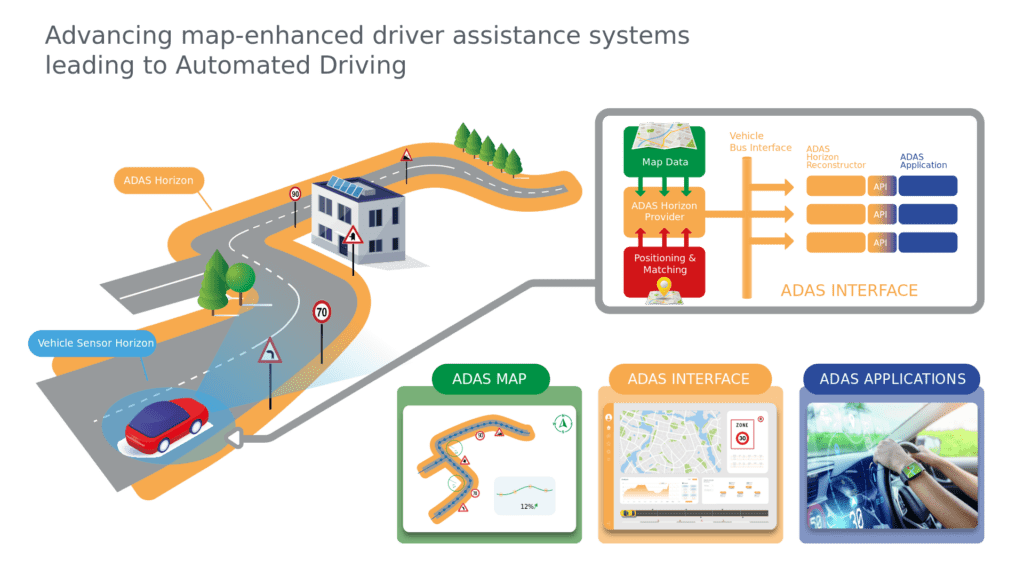
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )