PyTorch CNN超参数调优指南:提升模型精度的金钥匙
发布时间: 2024-12-11 14:26:46 阅读量: 14 订阅数: 15 

PyTorch模型评估全指南:技巧与最佳实践

# 1. PyTorch CNN基础与超参数概念
在现代深度学习领域,卷积神经网络(CNN)已成为图像识别和处理的核心技术。PyTorch作为一个开源的机器学习库,提供了强大的工具来构建和训练CNN模型。本章将介绍CNN的基础知识,以及在PyTorch环境中如何理解和操作超参数。
## 1.1 CNN基础
CNN是一种专门处理具有类似网格结构数据的深度学习模型,最常见的应用领域是图像处理。它的核心组件包括卷积层、池化层、全连接层以及非线性激活函数等。这些组件协同工作,通过学习数据的局部特征和抽象层次,使得CNN在图像识别任务中表现出色。
## 1.2 超参数概念
在构建CNN时,我们经常讨论的一个重要概念是“超参数”。与模型参数不同,超参数是在训练过程之前设置的,它们控制着学习过程和模型架构的配置。典型的超参数包括学习率、批次大小、卷积核的尺寸、网络层数等。合理地选择和调整这些超参数对于提高模型性能至关重要。
```python
# 示例代码:在PyTorch中定义一个简单的CNN结构
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc = nn.Linear(32 * 7 * 7, 10) # 假设输入图像大小为28x28
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 32 * 7 * 7) # 展平特征图以输入全连接层
x = self.fc(x)
return x
```
在上述代码中,`SimpleCNN`类定义了一个简单的卷积神经网络结构。其中,`nn.Conv2d`定义了一个卷积层,其超参数包括输入通道数、输出通道数、卷积核尺寸、步长和填充方式。这个基础的CNN模型将作为后续章节深入讨论超参数调优的起点。
# 2. CNN模型超参数解析与调优理论
### 2.1 卷积层关键超参数
#### 2.1.1 卷积核大小与数量
卷积神经网络(CNN)的卷积层是其核心组件之一,其中卷积核(也称为滤波器)的大小和数量是两个关键的超参数。卷积核的大小决定了感受野的大小,而卷积核的数量则影响模型的特征提取能力。
- **卷积核大小**:通常情况下,卷积核的大小为3x3或者5x5。较小的卷积核可以捕捉到更细致的特征,而较大的卷积核则能捕捉到更宽泛的特征。实践中,不同大小的卷积核往往结合使用,以达到最佳的特征提取效果。
例如,在一个图像识别任务中,我们可能会使用一个3x3的卷积核来捕捉边缘特征,同时使用一个5x5的卷积核来捕捉较大的图案特征。
- **卷积核数量**:卷积核的数量定义了在给定层中模型能够学习的特征数量。增加卷积核的数量可以提升模型的复杂度和表达能力,但也增加了模型的计算量和可能的过拟合风险。
在设计卷积层时,需要权衡模型的复杂度和训练数据的量级。一个经验法则是开始时选择较小数量的卷积核,随着模型的迭代逐渐增加。
#### 2.1.2 步长与填充策略
卷积操作中,步长(stride)和填充(padding)是决定卷积层输出维度的重要超参数。
- **步长**:步长定义了卷积核移动的间隔。较小的步长会导致更高的输出维度,而较大的步长则会减少输出的维度。较小的步长适用于保持空间信息,而较大的步长有助于减少模型的参数数量,但可能会导致信息的丢失。
- **填充策略**:填充是在输入数据的边缘添加额外的行和列,以便卷积操作后保持输入的空间维度不变。常见的填充策略有 "same" 和 "valid"。使用 "same" 填充时,输出的宽度和高度与输入相同;而 "valid" 填充则不进行任何填充,可能导致输出维度小于输入。
对于卷积层的设计,通常使用 "same" 填充以保持空间维度,特别是在网络的早期层,确保图像的空间信息不丢失。而在网络的深层,则可能会根据需要使用 "valid" 填充以减少特征图的大小,减少计算负担。
### 2.2 激活函数与损失函数的选择
#### 2.2.1 激活函数的作用与调优
激活函数是神经网络中的非线性映射,它引入非线性因素使得网络能够学习复杂的函数映射。常见的激活函数包括ReLU、Sigmoid和Tanh等。
- **ReLU (Rectified Linear Unit)**:是当前最受欢迎的激活函数,其函数形式为f(x) = max(0, x)。ReLU能有效解决梯度消失问题,并在计算上非常高效。然而,ReLU的负部分梯度为零,可能会导致所谓的“死亡ReLU”问题。
- **Sigmoid 和 Tanh**:这两个激活函数在早期的神经网络中广泛使用,但它们存在梯度消失的问题,并且计算效率不如ReLU。
在实践中,通常首选ReLU激活函数,并在必要时引入其变体如Leaky ReLU或Parametric ReLU等,以改善网络的性能。
#### 2.2.2 损失函数的选择对模型性能的影响
损失函数衡量的是模型预测值与真实值之间的差异。选择合适的损失函数对于模型的训练至关重要。
- **均方误差 (MSE)**:对于回归任务,MSE是常用的损失函数,其形式为MSE = (1/n)Σ(y_i - ŷ_i)²,其中y_i是真实值,ŷ_i是预测值,n是样本数量。
- **交叉熵损失**:对于分类任务,交叉熵损失是最常用的损失函数。它衡量的是两个概率分布之间的差异,其形式为CrossEntropy = -Σy_i * log(ŷ_i),其中y_i是真实标签的独热编码,ŷ_i是预测标签的概率分布。
在设计模型时,应根据任务的性质选择合适的损失函数,并根据需要进行调整。例如,对于不平衡分类问题,可能会使用加权交叉熵来平衡类别间的权重。
### 2.3 正则化与优化器的选择
#### 2.3.1 正则化策略:L1、L2、Dropout
为了防止模型过拟合,正则化策略是必不可少的。常见的正则化方法包括L1正则化、L2正则化和Dropout。
- **L1正则化**:通过在损失函数中加入权重的绝对值总和作为惩罚项,能够使得模型的权重倾向于稀疏,有助于特征选择。
- **L2正则化**:通过加入权重的平方和作为惩罚项,能够使得权重分布更为平滑,减少模型复杂度。
- **Dropout**:在训练过程中随机将一部分神经元的输出置为0,可以有效防止过拟合并提高模型泛化能力。Dropout的保留概率(即不置零的概率)是一个重要的超参数。
在实践中,通常会将L1和L2正则化结合使用(称为Elastic Net正则化),或者结合Dropout进行模型训练,以达到最佳的正则化效果。
#### 2.3.2 优化器:SGD、Adam、RMSprop
优化器是调整网络参数以最小化损失函数的算法,对模型的训练速度和收敛性有重要影响。
- **随机梯度下降(SGD)**:是最基础的优化算法,它通过随机选择的一个小批量数据来更新模型权重。虽然SGD具有良好的收敛性,但其学习率通常是固定的,需要手动调整。
- **Adam**:是自适应矩估计优化算法,它结合了RMSprop和动量(Momentum)的优点,能够自动调整每个参数的学习率。Adam算法对不同的问题和数据集都表现良好,是一个较为通用的选择。
- **RMSprop**:是专门用来解决RNN训练中梯度爆炸问题的优化算法。它通过维持一个移动的平均数来调整学习率,能够应对具有大量特征的复杂模型。
选择合适的优化器对于优化过程至关重要,需要根据模型的具体任务和数据集来决定使用哪种优化器,有时还需要调整优化器的超参数(例如学习率)以获得更好的训练效果。
# 3. PyTorch CNN超参数调优实践
## 3.1 使用PyTorch实现CNN模型
### 3.1.1 基本CNN模型搭建步骤
在PyTorch中,CNN模型的搭建涉及几个主要组件:卷积层(Conv2d)、激活函数(如ReLU)、池化层(MaxPool2d)、全连接层(Linear)以及最后的输出层。我们首先需要导入PyTorch的相关模块:
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
```
接下来,我们可以定义一个简单的CNN模型。以一个包含两个卷积层和两个全连接层的CNN为例,我们定义了一个类`SimpleCNN`,继承自`nn.Module`。在构造函数中,我们初始化了网络层,并在`forward`方法中定义了数据流动的路径。
```python
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 定义第一个卷积层,使用3个10x10的卷积核,步长为1,填充为0
self.conv1 = nn.Conv2d(3, 10, kernel_size=10, stride=1, padding=0)
# 定义第二个卷积层,使用20个5x5的卷积核,步长为1,填充为0
self.conv2 = nn.Conv2d(10, 20, kernel_size=5, stride=1, padding=0)
# 定义第一个全连接层,输入特征数为5*5*20,输出特征数为50
self.fc1 = nn.Linear(20 * 5 * 5, 50)
# 定义第二个全连接层,输入特征数为50,输出特征数为10
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# 卷积层 -> 激活函数 -> 池化层的流程
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
# 展平特征图以便输入全连接层
x = x.view(-1, 20 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
```
### 3.1.2 超参数的初始化与赋值
在定义CNN模型时,我们已经涉及到了一些基本的超参数,如卷积层的核大小、数量,池化层的大小等。在PyTorch中,这些超参数是在定义网络层时直接指定的。例如,我们给`conv1`卷积层指定了10个大小为10x10的卷积核,并通过`stride=1`和`padding=0`设置了卷积的步长和填充策略。在后续的调优过程中,这些超参数将是我们优化的重点。
```python
self.conv1 = nn.Conv2d(3, 10, kernel_size=10, stride=1, padding=0)
```
在实际应用中,超参数的初始化与赋值通常需要基于先前的知识或经验来初步设置。例如,卷积核的大小通常选择3x3或5x5这样的较小尺寸,因为它们能在捕捉特征的同时减少参数数量。步长通常设置为1以保持空间维度,而填充策略则用于控制输出特征图的尺寸。
在模型构建后,我们通常会对网络的权重进行初始化,例如可以使用`torch.nn.init.kaiming_normal_`方法对卷积层的权重进行初始化,使其接近于He初始化。
```python
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
model.apply(weights_init)
```
## 3.2 超参数调优技巧与实验设计
### 3.2.1 网格搜索与随机搜索方法
为了寻找最佳的超参数组合,常用的策略包括网格搜索(Grid Search)和随机搜索(Random Search)。网格搜索通过遍历预定义的超参数组合来寻找最优配置。尽管这种方法直观且易于实现

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏通过一系列深入浅出的文章,全面介绍了使用 PyTorch 实现卷积神经网络 (CNN) 的各个方面。从构建 CNN 模型的基础步骤到高级技巧和优化策略,该专栏提供了全面的指南。它涵盖了 CNN 的前向传播和反向传播、图像识别案例分析、性能优化、批量归一化、超参数调优、迁移学习、故障排除、激活函数选择、多 GPU 训练和损失函数优化。无论你是 CNN 初学者还是经验丰富的从业者,本专栏都能为你提供宝贵的见解和实用的技巧,帮助你构建和优化高效的 CNN 模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IT6801FN深度解析】:一文掌握手册中的20个核心技术要点

参考资源链接:[IT6801FN 数据手册:MHL2.1/HDMI1.4 接收器技术规格](https://wenku.csdn.net/doc
【电机控制实践】:DCS系统中电机启停原理图深度解读
参考资源链接:[DCS系统电机启停原理图.pdf](https://wenku.csdn.net/doc/646330c45928463033bd8df4?spm=1055.2635.3001.10343)
# 1. DCS系统概述与电机控制基础
## 1.1 DCS系统简介
分布式控制系统(DCS)是一种集成了数据采集、监控、控制和信息管理功
Win7_Win8系统Prolific USB-to-Serial适配器故障快速诊断与修复大全:专家级指南

参考资源链接:[Win7/Win8系统解决Prolific USB-to-Serial Comm Port驱动问题](https://wenku.csdn.net/doc/4zdddhvupp?spm=1055.2635.3001.10343)
# 1. Prolific USB-to-Serial适配器故障概述
在当今数字化时代,Prolific USB-to-Seria
iSecure Center 日志管理技巧:追踪与分析的高效方法
参考资源链接:[海康iSecure Center运行管理手册:部署、监控与维护详解](https://wenku.csdn.net/doc/2ibbrt393x?spm=1055.2635.3001.10343)
# 1. 日志管理的重要性和基础
## 1.1 日志管理的重要性
日志记录了系统运行的详细轨迹,对于故障诊断、性能监控、安全审计和
SSD1309性能优化指南

参考资源链接:[SSD1309: 128x64 OLED驱动控制器技术数据](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48805?spm=1055.2635.3001.10343)
# 1. SSD1309显示技术简介
SSD1309是一款广泛应用于小型显示设备中的单色OLED驱动芯片,由上海世强先进科技有限公司生产。它支持多种分辨率、拥有灵活的接口配置,并且通过I2C或S
Rational Rose顺序图性能优化:10分钟掌握最佳实践
参考资源链接:[Rational Rose顺序图建模详细教程:创建、修改与删除](https://wenku.csdn.net/doc/6412b4d0be7fbd1778d40ea9?spm=1055.2635.3001.10343)
# 1. Rational Rose顺序图简介与性能问题
## 1.1 Rational Rose工具的介绍
Rational Rose是IBM推出
无线快充技术革新:IP5328与无线充电的完美融合
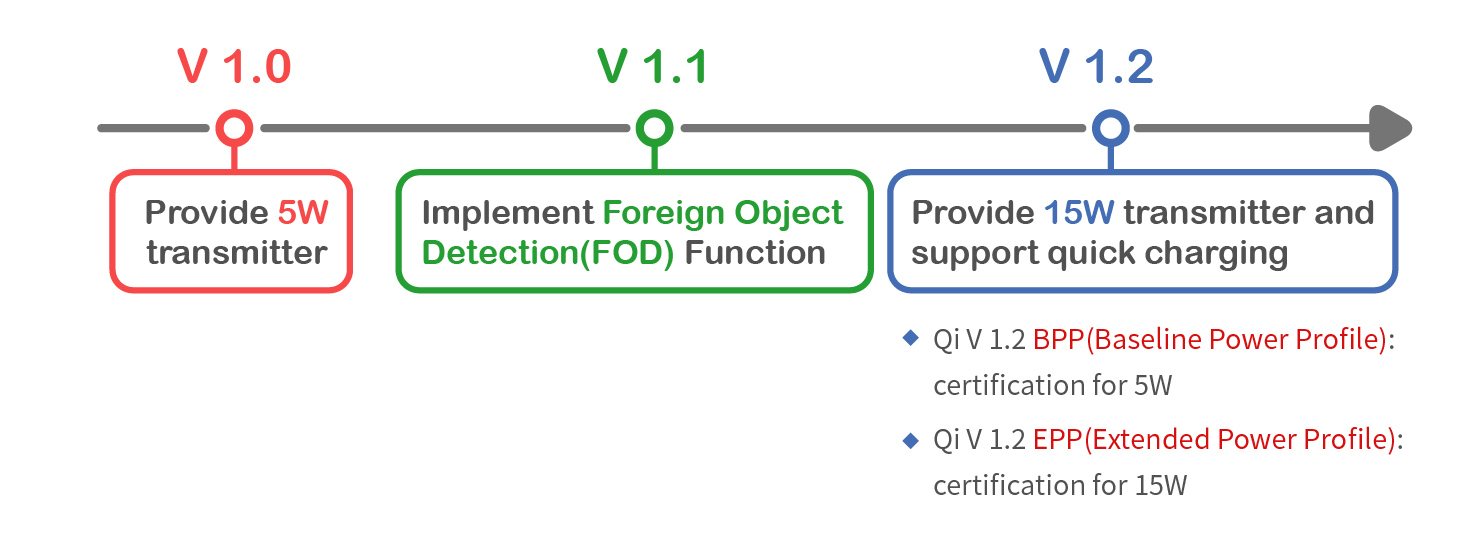
参考资源链接:[IP5328移动电源SOC:全能快充协议集成,支持PD3.0](https://wenku.csdn.net/doc/16d8bvpj05?spm=1055.2635.3001.10343)
# 1. 无线快充技术概述
无线快充技术的兴起,改变了人们为电子设备充电的习惯,使得充电变得更加便捷和高效。这种技
【AI引擎高级功能开发】:Prompt指令扩展的实践与策略
参考资源链接:[掌握ChatGPT Prompt艺术:全场景写作指南](https://wenku.csdn.net/doc/2b23iz0of6?spm=1055.2635.3001.10343)
# 1. AI引擎与Prompt指令概述
在当前的IT和人工智能领域,AI引擎与Prompt指令已经成为提升自然语言处理能力的重要工具。AI引擎作为核心的技术驱动,其功能的发挥往往依赖于高效、准确的Prompt指令。通过使用这些指令,AI引擎能够更好地理解和执行用户的查询、请求和任务,从而展现出强大的功能和灵活性。
AI引擎与Prompt指令的结合,不仅加速了人工智能的普及,也推动了智能技术在
【汇川H5U Modbus TCP性能提升】:高级技巧与优化策略
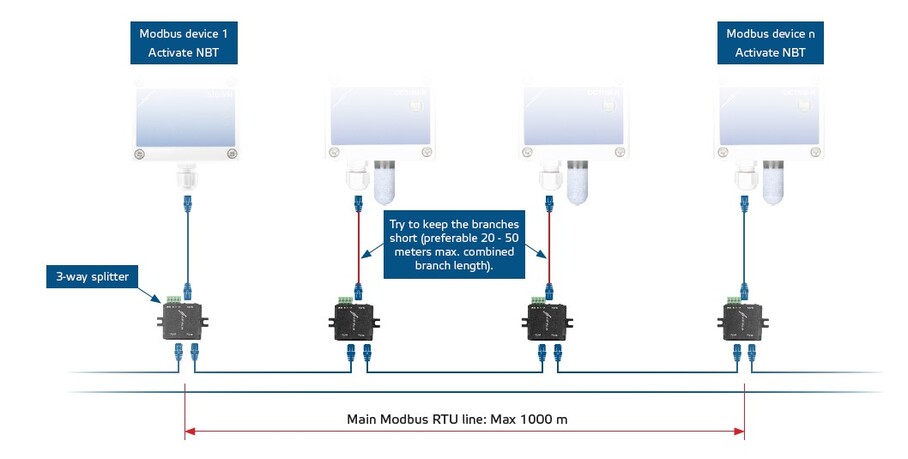
参考资源链接:[汇川H5U系列控制器Modbus通讯协议详解](https://wenku.csdn.net/doc/4bnw6asnhs?spm=1055.2635.3001.10343)
# 1. Modbus TCP协议概述
Modbus TCP协议作为工业通信领域广泛采纳的开放式标准,它在自动化控制和监视系统中扮演着至关重要的角色。本章首先将简要回顾Mod
【TFT-OLED速度革命】:提升响应速度的驱动电路改进策略

参考资源链接:[TFT-OLED像素单元与驱动电路:新型显示技术的关键](https://wenku.csdn.net/doc/645e54535
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )