PyTorch CNN批量归一化的威力:原理与实现技巧
发布时间: 2024-12-11 14:06:28 阅读量: 28 订阅数: 15 

pytorch 归一化与反归一化实例

# 1. CNN批量归一化的基础理解
深度学习模型训练的过程中,批量归一化(Batch Normalization, BN)是一种关键的技术,它有助于提升模型的训练速度和稳定性。批量归一化是通过规范化网络中每层输入的均值和方差,从而减少内部协变量偏移(Internal Covariate Shift),这一过程允许开发者在训练过程中使用更高的学习率,同时减少对初始化权重的依赖。
从实践的角度来看,批量归一化为CNN提供了增强的泛化能力。CNN通过层级结构逐渐提取和抽象数据的特征,批量归一化使得每个层次面对的数据分布更为稳定,从而加速模型收敛。
本章节将浅入深出地探讨批量归一化的基础概念,介绍其在卷积神经网络中的作用,并简要描述其背后的关键思想。接下来的章节将深入分析批量归一化的理论基础、实现细节和最佳实践,最终探索其在各种任务中的应用和进阶话题。
# 2. 批量归一化的理论基础
## 2.1 批量归一化的概念和作用
### 2.1.1 归一化的定义和意义
归一化是数据预处理中常用的一种技术,目的在于将数据特征标准化,以消除不同尺度对数据处理的影响。归一化的处理方式包括最小-最大归一化和z-score标准化等。对于深度学习而言,归一化可以使模型训练更快收敛,并提高模型的泛化能力。具体到批量归一化,它是在每个小批量数据上独立地进行归一化处理,从而保证输入数据的分布稳定,缓解梯度消失和梯度爆炸的问题。
### 2.1.2 批量归一化的提出背景
随着深度神经网络层数的增加,训练过程容易出现梯度不稳定和收敛速度慢等问题。批量归一化(Batch Normalization, BN)的概念由Ioffe和Szegedy在2015年提出,旨在解决这些训练难题。批量归一化通过对每一批数据的输入进行归一化处理,使得输入数据在每一层的输入保持相对稳定,从而改善模型训练性能,加快模型收敛。
## 2.2 批量归一化的数学原理
### 2.2.1 归一化过程的数学描述
批量归一化的数学过程主要分为三个步骤:
1. **计算均值和方差**:在每个小批量样本上,计算每个特征的均值(mean)和方差(variance)。
2. **归一化处理**:对每个特征进行归一化处理,使其均值为0,方差为1。
3. **尺度变换和位移**:引入可学习的参数γ和β,对归一化的结果进行尺度变换和位移,以保持网络表示的表达能力。
数学公式如下:
- 均值和方差计算公式:
$$ \mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i $$
$$ \sigma^2_B = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2 $$
其中,\( x_i \) 是批量 \( B \) 中的样本特征,\( m \) 是批量大小。
- 归一化处理:
$$ \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma^2_B + \epsilon}} $$
其中,\( \epsilon \) 是一个很小的值,用于防止除以零的情况。
- 尺度变换和位移:
$$ y_i = \gamma \hat{x}_i + \beta $$
其中,\( \gamma \) 和 \( \beta \) 是可学习的参数,允许模型学习输入数据的分布。
### 2.2.2 批量归一化中的统计量估计
批量归一化的统计量估计是在小批量数据上计算得到的,这为深度神经网络提供了一种假设:如果模型的输入在每个层都保持一致的分布,那么模型的训练将会更稳定。实践中,使用整个训练集的统计量进行归一化处理也可以获得不错的效果,这称为“全批量归一化”。
## 2.3 批量归一化与深度学习性能
### 2.3.1 训练过程中的收敛性提升
批量归一化通过稳定每个层的输入分布,从而减少了模型对初始化权重的敏感性,降低了训练过程中的梯度消失和梯度爆炸的风险。它使得网络能够使用更高的学习率,从而加速模型的收敛。
### 2.3.2 防止过拟合的原理
在理论层面,批量归一化通过引入额外的随机性,可以作为模型的正则化手段,从而在一定程度上缓解过拟合的问题。此外,它还可以使得学习率的选择更加宽松,进一步降低过拟合的风险。然而,需要注意的是,批量归一化本身并不等同于传统的正则化方法,如L1、L2正则化,因此并不能完全替代正则化手段。
接下来,我们将深入了解在PyTorch中如何实现批量归一化,并探讨如何在实际应用中对其进行配置与优化。
# 3. PyTorch中批量归一化的实现
## 3.1 PyTorch批量归一化层的使用
### 3.1.1 应用批量归一化的API
在PyTorch中,批量归一化(Batch Normalization)被实现为`torch.nn.BatchNorm1d`、`torch.nn.BatchNorm2d`和`torch.nn.BatchNorm3d`,分别对应于一维(如全连接层)、二维(如卷积层)和三维(如3D卷积层)数据的批量归一化操作。下面将举例演示如何在PyTorch中应用批量归一化层。
```python
import torch
import torch.nn as nn
# 创建一个批量归一化层示例
batch_norm = nn.BatchNorm2d(num_features=128) # 适用于卷积层输出的特征通道数
# 示例输入数据,用于演示
input_data = torch.randn(1, 128, 10, 10) # (batch_size, channels, height, width)
# 通过批量归一化层处理输入数据
normalized_data = batch_norm(input_data)
print(normalized_data)
```
以上代码展示了如何定义一个适用于二维数据的批量归一化层,并将一个随机生成的输入数据通过这个层进行归一化处理。在实践中,通常将批量归一化层嵌入到神经网络模型中,紧接卷积层或全连接层之后。
### 3.1.2 在模型中集成批量归一化层
批量归一化通常被嵌入到神经网络的模型定义中。下面给出一个简单的卷积神经网络示例,并在其中集成批量归一化层:
```python
class ConvBNNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvBNNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features=32)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=64)
self.fc = nn.Linear(in_features=64 * 7 * 7, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = torch.relu(x)
x = nn.MaxPool2d(kernel_size=2, stride=2)(x)
x = self.conv2(x)
x = self.bn2(x)
x = torch.relu(x)
x = nn.MaxPool2d(kernel_size=2, stride=2)(x)
x = x.view(x.size(0), -1) # Flatten the tensor
x = self.fc(x)
return x
```
在这个简单的模型中,我们定义了一个`ConvBNNet`类,其中嵌入了两个卷积层和两个批量归一化层。批量归一化层被放置在每个卷积层的输出之后,并且通常后面

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏通过一系列深入浅出的文章,全面介绍了使用 PyTorch 实现卷积神经网络 (CNN) 的各个方面。从构建 CNN 模型的基础步骤到高级技巧和优化策略,该专栏提供了全面的指南。它涵盖了 CNN 的前向传播和反向传播、图像识别案例分析、性能优化、批量归一化、超参数调优、迁移学习、故障排除、激活函数选择、多 GPU 训练和损失函数优化。无论你是 CNN 初学者还是经验丰富的从业者,本专栏都能为你提供宝贵的见解和实用的技巧,帮助你构建和优化高效的 CNN 模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PDK安装与配置秘籍】:10个步骤带你掌握PDK安装与高级优化技巧
参考资源链接:[SMIC 28nm PDK安装与cdl、gds文件导入教程](https://wenku.csdn.net/doc/3r40y99kvr?spm=1055.2635.3001.10343)
# 1. PDK安装与配置的理论基础
PDK(Platform Development Kit)是开发和配置特定平台应用的关键工具,它为企业提供了一套完整的解决方案,以支持快速、高效和一致的平台应用开发。理
【案例分析】:DCS系统电机启停控制故障诊断与处理技巧

参考资源链接:[DCS系统电机启停原理图.pdf](https://wenku.csdn.net/doc/646330c45928463033bd8df4?spm=1055.2635.3001.10343)
# 1. DCS系统电机控制概述
在现代工业控制系统中,分布式控制系统(DCS)被广泛应用于复杂的工业过程中,其中电机控制是DCS
Rational Rose顺序图性能优化:10分钟掌握最佳实践
参考资源链接:[Rational Rose顺序图建模详细教程:创建、修改与删除](https://wenku.csdn.net/doc/6412b4d0be7fbd1778d40ea9?spm=1055.2635.3001.10343)
# 1. Rational Rose顺序图简介与性能问题
## 1.1 Rational Rose工具的介绍
Rational Rose是IBM推出
【Prolific USB-to-Serial适配器故障】:Win7_Win8系统用户必学的故障排除技巧

参考资源链接:[Win7/Win8系统解决Prolific USB-to-Serial Comm Port驱动问题](https://wenku.csdn.net/doc/4zdddhvupp?spm=1055.2635.3001.10343)
# 1. Prolific USB-to-Serial适配器故障概述
随着信息技术的发展
IT6801FN系统集成案例分析:跟随手册实现无缝集成
参考资源链接:[IT6801FN 数据手册:MHL2.1/HDMI1.4 接收器技术规格](https://wenku.csdn.net/doc/6412b744be7fbd1778d49adb?spm=1055.2635.3001.10343)
# 1. IT6801FN系统集成概述
## 1.1 IT6801FN系统集成的定义
IT6801FN系统集成通常涉及将多个不同的软件、硬件和服务整合到一起
【SPWM波形工具:从原理到实践】:全面掌握技术应用与优化
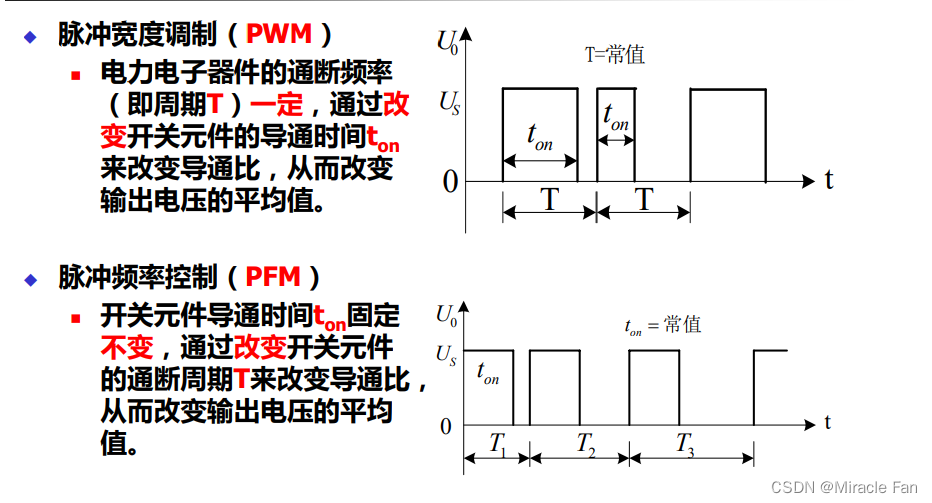
参考资源链接:[spwm_calc_v1.3.2 SPWM生成工具使用指南:简化初学者入门](https://wenku.csdn.net/doc/6401acfecce7214c316ede5f?spm=1055.2635.3001.10343)
# 1. SPWM波形技术概述
正弦脉宽调制(SPWM)技术是电力电子领域中的一项重要技术,它通过调制波形的占空比来接近一个正弦波形,用于控制电机驱
SSD1309编程实践

参考资源链接:[SSD1309: 128x64 OLED驱动控制器技术数据](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48805?spm=1055.2635.3001.10343)
# 1. SSD1309 OLED显示屏简介
## SSD1309 OLED显示屏简介
SSD1309是一款广泛应用于小型显示设备中的OLED(有机发光二极管)显示屏控制器。由于其高对比度、低
掌握离散数学:刘玉珍编著中的20大精髓与应用案例分析

参考资源链接:[离散数学答案(刘玉珍_编著)](https://wenku.csdn.net/doc/6412b724be7fbd1778d493b9?spm=1055.2635.3001.10343)
# 1. 离散数学概述与基础知识
## 1.1 离散数学的定义和重要性
离散数学是一门研究离散量的数学分支,与连
【Prompt指令优化策略】:AI引擎响应速度提升的终极指南

参考资源链接:[掌握ChatGPT Prompt艺术:全场景写作指南](https://wenku.csdn.net/doc/2b23iz0of6?spm=1055.2635.3001.10343)
# 1. Prompt指令优化的理论基础
## 1.1 理解Prompt优化的目的
Prompt指令优化的目的是为了让智能系统更准确、快速地
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )