【Python编码与解码】:unicodedata库使用技巧,让编码不再是障碍
发布时间: 2024-09-29 20:54:22 阅读量: 65 订阅数: 31 

python判断字符串编码的简单实现方法(使用chardet)

# 1. Python中的编码与解码基础
在现代信息处理领域中,编码和解码是一项基础而至关重要的技术。Python 作为一门广泛应用于数据处理和系统开发的语言,提供了强大的支持来处理编码与解码问题。理解编码和解码对于确保数据的准确性和一致性至关重要。本章将从基础概念出发,探讨 Python 中如何进行编码与解码,以及它对于文本处理的重要性。
## 1.1 编码和解码概述
编码(encoding)是将字符串、文本或其他数据形式转换为特定格式或序列的过程。解码(decoding)则是将这些格式或序列恢复回原始数据形式的过程。在 Python 中,字符编码通常涉及将字符串从一种字符集转换为另一种,如将 Unicode 字符串转换为 UTF-8 编码。
## 1.2 Python 中的编码操作
Python 中的编码和解码操作主要涉及到字符串的处理。字符串在 Python 中以 Unicode 形式存在,而 Unicode 是一个国际标准,用于表示文本中的字符。以下是 Python 中编码和解码的一个基本示例:
```python
text = "你好,世界!"
encoded_text = text.encode('utf-8') # 将 Unicode 字符串编码为 UTF-8 字节串
decoded_text = encoded_text.decode('utf-8') # 将 UTF-8 字节串解码回 Unicode 字符串
print(encoded_text) # 输出字节串
print(decoded_text) # 输出原始 Unicode 字符串
```
上述代码展示了将包含中文字符的 Unicode 字符串转换为 UTF-8 编码的字节串,然后再解码回原始字符串的过程。理解并正确使用 Python 中的编码和解码操作,能够有效避免在数据交换中出现乱码问题,保证文本数据的兼容性和一致性。
通过接下来的章节,我们将深入探讨如何利用 `unicodedata` 库来处理更复杂的编码问题。
# 2. unicodedata库核心功能详解
## 2.1 unicodedata库概述
### 2.1.1 库的安装和基本用法
`unicodedata`是Python标准库的一部分,因此不需要单独安装。要使用它,只需在Python脚本中导入即可:
```python
import unicodedata
```
`unicodedata`模块提供了访问Unicode字符数据库的功能,允许我们查询字符的属性,以及对字符进行标准化处理。它通常用于处理文本数据时的编码和解码问题。
举个例子,如果我们需要检查一个字符串是否全部由字母和数字组成,可以使用`unicodedata`来帮助我们完成:
```python
import unicodedata
def is_alphanumeric(string):
return all(unicodedata.category(char).startswith(('L', 'N')) for char in string)
print(is_alphanumeric("abc123")) # 输出:True
print(is_alphanumeric("abc!23")) # 输出:False
```
在这个例子中,我们定义了一个函数`is_alphanumeric`,它利用`unicodedata.category()`方法来获取每个字符的类别,并检查这些类别是否以'L'(字母)或'N'(数字)开头。
### 2.1.2 unicodedata库在编码处理中的角色
`unicodedata`库在编码处理中扮演了关键角色,尤其是在涉及到字符属性的查询和文本的规范化处理上。通过此库提供的接口,开发者可以更容易地实现Unicode兼容性。
一个常见的应用场景是在处理不同语言的文本时,确保字符的正确显示和存储。例如,同一个字符在不同的语言环境里可能会有不同的编码形式,使用`unicodedata`可以帮助我们规范化这些字符,确保数据的一致性和准确性。
```python
import unicodedata
text = "é"
normalized_text = unicodedata.normalize('NFC', text)
print(normalized_text) # 输出:é
```
在这个例子中,我们使用了Unicode的规范化形式NFC(Normalization Form Canonical Composition),它将字符组合成其规范形式。
## 2.2 字符属性查询与使用
### 2.2.1 查询字符的名称和类别
每个Unicode字符都有一个唯一的名称和一个类别,通过`unicodedata`可以查询这些信息。
```python
import unicodedata
char = 'A'
name = unicodedata.name(char)
category = unicodedata.category(char)
print(f"Character: {char}, Name: {name}, Category: {category}")
# 输出:Character: A, Name: LATIN CAPITAL LETTER A, Category: Lu
```
通过`unicodedata.name()`方法可以获取字符的名称,而`unicodedata.category()`可以获取字符所属的Unicode类别(比如`Lu`表示大写字母)。
### 2.2.2 获取字符的标准化形式
字符的标准化形式是指将字符表示为一种标准的格式,以便进行比较和处理。`unicodedata`提供了四种标准化形式:
- NFC:规范组合
- NFD:规范分解
- NFKC:兼容组合
- NFKD:兼容分解
```python
import unicodedata
text = "é"
nfc_text = unicodedata.normalize('NFC', text)
nfd_text = unicodedata.normalize('NFD', text)
print(nfc_text) # 输出:é
print(nfd_text) # 输出:é
```
在以上代码中,我们展示了同一个字符使用NFC和NFD两种不同标准化形式的差异。
### 2.2.3 检查字符的属性(如字母、数字等)
`unicodedata`不仅能够提供字符的名称和类别,还能够帮助我们判断字符的属性,例如是否为字母、数字或者标点符号等。
```python
import unicodedata
char = 'A'
is_letter = 'L' in unicodedata.category(char)
is_digit = 'N' in unicodedata.category(char)
print(f"Is the character '{char}' a letter? {is_letter}")
print(f"Is the character '{char}' a digit? {is_digit}")
# 输出:Is the character 'A' a letter? True
# Is the character 'A' a digit? False
```
## 2.3 字符的规范分解与组合
### 2.3.1 规范分解(Normalization Forms)
规范分解是将字符分解成更基本的形式的过程,这有助于消除不同编码中同一字符的表示差异。
### 2.3.2 字符的组合和分解操作
字符的组合和分解操作是文本处理中的基础,通过`unicodedata`模块中的方法,可以轻松实现这一功能。
```python
import unicodedata
# 示例:将分解的字符重新组合
text = "é"
composed_text = unicodedata.normalize('NFC', text)
print(composed_text) # 输出:é
```
通过`unicodedata.normalize()`方法,可以将分解的字符按照Unicode标准重新组合,确保字符的一致性。
通过以上内容,我们可以看到`unicodedata`模块在字符属性查询和文本规范化处理中的强大功能。这些功能对于开发需要处理国际化文本的应用程序尤其重要。
# 3. unicodedata库在实际编码问题中的应用
在这一章节中,我们将深入探讨如何将unicodedata库应用于解决现实世界中的编码问题。unicodedata库作为Python标准库的一部分,它允许程序员处理Unicode字符的多种属性和操作,例如字符的规范化、类别和名称查询以及字符分解和组合。我们将展示实际问题场景,涉及文本编码转换、文本清洗、数据规范化以及高级编码解决方案,并通过代码示例和分析深入理解unicodedata库如何在这些问题中发挥作用。
## 3.1 文本编码转换与兼容性问题
### 3.1.1 不同编码标准之间的转换
在计算机科学中,编码转换是一个常见的任务,尤其是在处理来自不同系统或语言的数据时。Python中的unicodedata库不能直接进行编码转换,但可以辅助理解和处理Unicode字符,以便在使用其他库(如`codecs`)进行编码转换时保持字符的完整性。
在不同编码标准之间进行转换,如从UTF-8转换到ISO-8859-1,通常需要借助`codecs`库:
```python
import codecs
import unicodedata
# 假设我们有一个UTF-8编码的字符串
utf8_string = 'Café'
# 将UTF-8字符串转换为ISO-8859-1
iso_string = codecs.encode(utf8_string, 'latin1')
print(iso_string)
```
此代码块的逻辑是首先导入需要的模块,然后执行一个转换过程。`codecs.encode`函数执行实际的编码转换,而`unicodedata`在这里虽然没有直接使用,但它有助于了解`utf8_string`中的字符如何映射到ISO-8859-1编码。
### 3.1.2 处理编码兼容性和字符映射问题
在转换编码时,可能会遇到某些字符在目标编码中不存在的情况,这时就需要进行字符映射。`unicodedata`库可以用来查询字符信息,并为编码转换提供辅助信息。例如,Unicode字符U+00E9(é)在ISO-8859-1中直接对应字符码0xE9:
```python
# 使用unicodedata查询字符信息
char_info = unicodedata.category('é')
print(char_info) # 输出 'Ll', 表示小写字母
```
结合`unicodedata`查询到的信息,可以在编码转换中进行适当的字符替换或处理,确保转换的准确性和数据的完整性。
## 3.2 文本清洗与数据规范化
### 3.2.1 清除非标准和不可打印字符
文本清洗

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Python 中强大的 unicodedata 库,帮助开发者掌握 Unicode 数据处理的方方面面。从编码规范到字符串处理进阶,从库的幕后机制到编码解码技巧,再到国际化应用开发和文本清洗,专栏涵盖了 unicodedata 库的广泛应用场景。此外,还深入剖析了 Unicode 字符分类、特殊字符处理、Unicode 标准化、编码问题排查、Unicode 版本控制、编码转换、兼容性处理、代码库国际化以及 Unicode 数学和货币符号处理,为开发者提供了全面的指南,助力其构建无懈可击的 Unicode 处理代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【GSEA基础入门】:掌握基因集富集分析的第一步

# 摘要
基因集富集分析(GSEA)是一种广泛应用于基因组学研究的生物信息学方法,其目的是识别在不同实验条件下显著改变的生物过程或通路。本文首先介绍了GSEA的理论基础,并与传统基因富集分析方法进行比较,突显了GSEA的核心优势。接着,文章详细叙述了GSEA的操作流程,包括软件安装配置、数据准备与预处理、以及分析步骤的讲解。通过实践案例分析,展示了GSEA在疾病相关基因集和药物作用机制研究中的应用,以及结果的
【ISO 14644标准的终极指南】:彻底解码洁净室国际标准
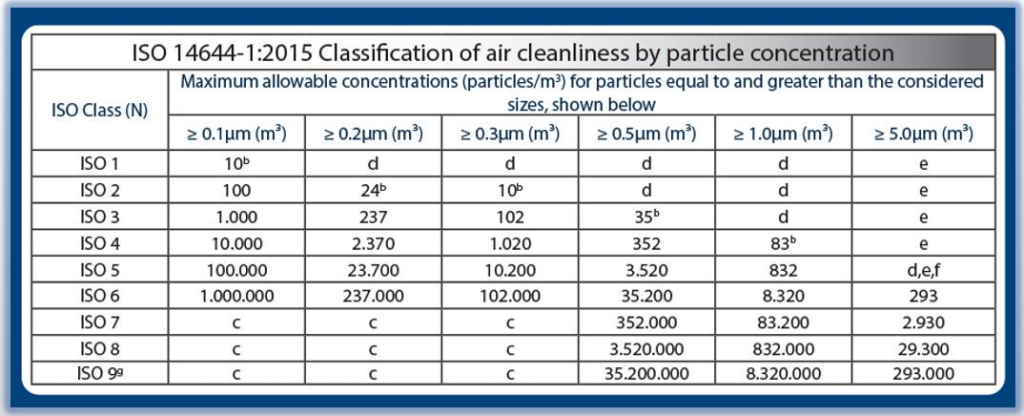
# 摘要
本文系统阐述了ISO 14644标准的各个方面,从洁净室的基础知识、分类、关键参数解析,到标准的详细解读、环境控制要求以及监测和维护。此外,文章通过实际案例探讨了ISO 14644标准在不同行业的实践应用,重点分析了洁净室设计、施工、运营和管理过程中的要点。文章还展望了洁净室技术的发展趋势,讨论了实施ISO 14644标准所
【从新手到专家】:精通测量误差统计分析的5大步骤

# 摘要
测量误差统计分析是确保数据质量的关键环节,在各行业测量领域中占有重要地位。本文首先介绍了测量误差的基本概念与理论基础,探讨了系统误差、随机误差、数据分布特性及误差来源对数据质量的影响。接着深入分析了误差统计分析方法,包括误差分布类型的确定、量化方法、假设检验以及回归分析和相关性评估。本文还探讨了使用专业软件工具进行误差分析的实践,以及自编程解决方案的实现步骤。此外,文章还介绍了测量误差统计分析的高级技巧,如误差传递、合
【C++11新特性详解】:现代C++编程的基石揭秘
# 摘要
C++11作为一种现代编程语言,引入了大量增强特性和工具库,极大提升了C++语言的表达能力及开发效率。本文对C++11的核心特性进行系统性概览,包括类型推导、模板增强、Lambda表达式、并发编程改进、内存管理和资源获取以及实用工具和库的更新。通过对这些特性的深入分析,本文旨在探讨如何将C++11的技术优势应用于现代系统编程、跨平台开发,并展望C++11在未来
【PLC网络协议揭秘】:C#与S7-200 SMART握手全过程大公开
# 摘要
本文旨在详细探讨C#与S7-200 SMART PLC之间通信协议的应用,特别是握手协议的具体实现细节。首先介绍了PLC与网络协议的基础知识,随后深入分析了S7-200 SMART PLC的特点、网络配置以及PLC通信协议的概念和常见类型。文章进一步阐述了C#中网络编程的基础知识,为理解后续握手协议的实现提供了必要的背景。在第三章,作者详细解读了握手协议的理论基础和实现细节,包括数据封装与解析的规则和方法。第四章提供了一个实践案例,详述了开发环境的搭建、握手协议的完整实现,以及在实现过程中可能遇到的问题和解决方案。第五章进一步讨论了握手协议的高级应用,包括加密、安全握手、多设备通信等
电脑微信"附近的人"功能全解析:网络通信机制与安全隐私策略
# 摘要
本文综述了电脑微信"附近的人"功能的架构和隐私安全问题。首先,概述了"附近的人"功能的基本工作原理及其网络通信机制,包括数据交互模式和安全传输协议。随后,详细分析了该功能的网络定位机制以及如何处理和保护定位数据。第三部分聚焦于隐私保护策略和安全漏洞,探讨了隐私设置、安全防护措施及用户反馈。第四章通过实际应用案例展示了"附近的人"功能在商业、社会和
Geomagic Studio逆向工程:扫描到模型的全攻略
# 摘要
本文系统地介绍了Geomagic Studio在逆向工程领域的应用。从扫描数据的获取、预处理开始,详细阐述了如何进行扫描设备的选择、数据质量控制以及预处理技巧,强调了数据分辨率优化和噪声移除的重要性。随后,文章深入讨论了在Geomagic Studio中点云数据和网格模型的编辑、优化以及曲面模型的重建与质量改进。此外,逆向工程模型在不同行业中的应用实践和案例分析被详细探讨,包括模型分析、改进方法论以及逆向工程的实际应用。最后,本文探
大数据处理:使用Apache Spark进行分布式计算

# 摘要
Apache Spark是一个为高效数据处理而设计的开源分布式计算系统。本文首先介绍了Spark的基本概念及分布式计算的基础知识,然后深入探讨了Spark的架构和关键组件,包括核心功能、SQL数据处理能力以及运行模式。接着,本文通过实践导向的方式展示了Spark编程模型、高级特性以及流处理应用的实际操作。进一步,文章阐述了Spark MLlib机器学习库和Gr
【FPGA时序管理秘籍】:时钟与延迟控制保证系统稳定运行

# 摘要
随着数字电路设计的复杂性增加,FPGA时序管理成为保证系统性能和稳定性的关键技术。本文首先介绍了FPGA时序管理的基础知识,深入探讨了时钟域交叉问题及其对系统稳定性的潜在影响,并且分析了多种时钟域交叉处理技术,包括同步器、握手协议以及双触发器和时钟门控技术。在延迟控制策略方面,本文阐述了延
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )