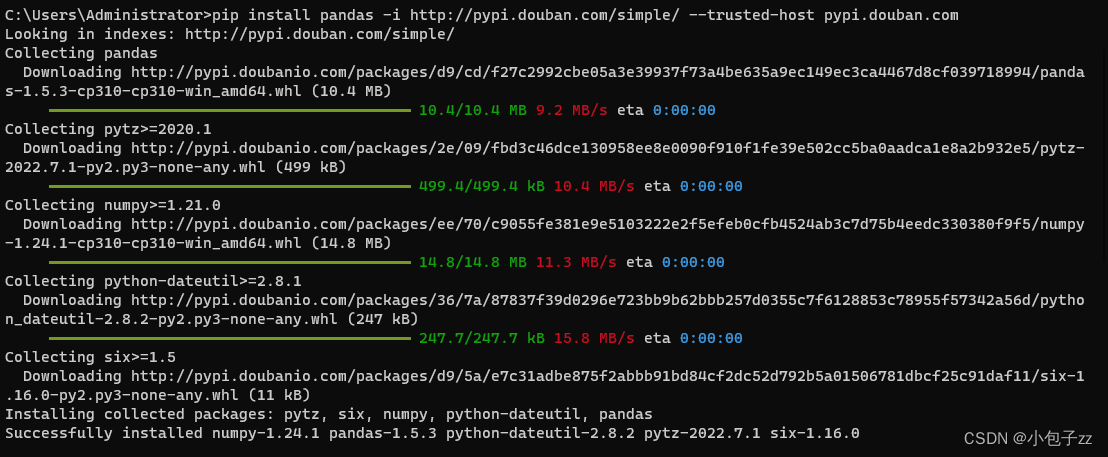
【Pandas环境兼容性】:解决安装中的兼容性问题
发布时间: 2024-12-07 09:38:35 阅读量: 11 订阅数: 18 

PANDAS环境搭建所需的环境
# 1. Pandas库的简介与功能
## 简介
Pandas是一个开源的Python数据分析库,它提供了高性能、易用的数据结构和数据分析工具。通过Pandas,数据科学家可以快速地进行数据清洗、操作、可视化和分析工作。Pandas广泛应用于数据挖掘、统计建模、金融分析和许多其他领域。
## 功能概览
Pandas的主要数据结构是DataFrame,它类似于Excel表格,能够存储结构化数据。Pandas库的核心功能包括但不限于:
- 数据导入与导出:支持多种数据格式(如CSV、Excel、JSON等)的读取和写入。
- 数据清洗:能够处理缺失数据、重复数据、数据转换、数据规范化等问题。
- 数据筛选与聚合:支持条件筛选、分组聚合、数据排序等操作。
- 数据统计与分析:包括数据描述统计、交叉表、时间序列分析等。
## 安装与基础使用
在Python环境中安装Pandas非常简单,可以通过以下命令完成安装:
```python
pip install pandas
```
一旦安装完成,可以通过创建一个简单的DataFrame来开始使用Pandas:
```python
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [24, 35, 27]
}
df = pd.DataFrame(data)
print(df)
```
通过上述简单的示例,我们可以看到Pandas强大的数据处理能力。接下来的章节我们将探讨如何在不同环境下确保Pandas库的兼容性,并深入分析如何有效管理Pandas的环境兼容性问题。
# 2. Pandas环境兼容性问题的诊断与解决
在数据科学和分析中,Pandas库由于其强大的数据处理能力,成为了Python生态中不可或缺的一部分。然而,随着Pandas的广泛应用,环境兼容性问题也逐渐显现出来。这包括不同操作系统和Python版本之间的兼容性,以及依赖包版本冲突等问题。这些问题若不及时解决,会影响到项目的顺利进行。
## 2.1 环境兼容性问题的成因分析
### 2.1.1 系统环境差异导致的问题
在Windows、Linux和macOS这三大操作系统中,Pandas及其依赖包的安装和运行可能存在差异。例如,在Windows上,编译依赖的包可能因为缺少必要的编译器而无法安装;而在Linux上,特定的系统库版本可能与Pandas或其依赖包的编译依赖不兼容。
### 2.1.2 Python版本不一致引起的问题
Pandas库对Python的版本有严格的要求,不同版本的Python可能会影响Pandas的安装和执行。例如,较早的Python版本可能不支持某些Pandas的特性,而较新的Python版本可能需要新的Pandas版本才能利用其全部特性。
### 2.1.3 依赖包版本冲突的问题
Pandas有着众多的依赖包,如NumPy、matplotlib等。这些包之间可能存在版本冲突,一个包的更新可能会破坏另一个包的功能。尤其是在使用第三方工具或库时,它们可能对Pandas及其依赖包的版本有特定要求。
## 2.2 兼容性问题的诊断方法
### 2.2.1 利用Pandas官方文档进行诊断
官方文档提供了关于不同系统和Python版本的安装指南,以及各个版本之间的兼容性说明。通过阅读官方文档,可以初步判断问题的可能来源。
### 2.2.2 使用虚拟环境进行隔离测试
通过创建虚拟环境可以隔离问题,确保在纯净的环境中安装和运行Pandas,这样可以排除系统环境因素的干扰。虚拟环境的创建和管理工具如`virtualenv`或`conda`环境。
### 2.2.3 使用工具和脚本自动化诊断
一些工具和脚本,如`pip-audit`,可以帮助检测Python包的潜在问题,包括版本冲突和安全漏洞。此外,`Pandas`本身提供的`pandas.show_versions()`方法能够输出环境和版本信息,有助于诊断问题。
## 2.3 兼容性问题的解决方案
### 2.3.1 通过conda管理环境和包
conda是一个开源的包、依赖和环境管理器,能够安装多个版本的包和Python,并在它们之间切换。使用conda创建隔离的环境,可以确保环境的干净,解决依赖冲突的问题。
#### 示例代码块
```python
# 创建一个新的conda环境
conda create -n pandas_env python=3.8 pandas=1.2
# 激活环境
conda activate pandas_env
# 验证环境中的Pandas版本
python -c "import pandas; print(pandas.__version__)"
```
通过上述命令,我们可以创建一个包含特定Pandas版本的新环境,激活并确认Pandas版本。
### 2.3.2 使用pip解决依赖冲突
在某些情况下,conda可能不满足特定的包版本需求,此时可以使用pip来安装或升级包。但要注意,使用pip可能会与conda环境中的其他包发生冲突,因此应谨慎使用。
#### 示例代码块
```bash
# 通过pip升级pandas到指定版本
pip install --upgrade pandas==1.2.3
# 查看当前环境中所有包的版本信息
pip freeze
```
在使用pip进行包管理时,`pip freeze`命令能够列出所有已安装的包及其版本信息,有助于跟踪和管理依赖。
### 2.3.3 手动调整环境和版本兼容性
当自动化的工具无法解决问题时,可能需要手动介入调整环境配置。这包括修改环境变量、手动编译安装依赖包或调整代码以适应不同版本的Pandas。
在进行手动调整时,建议记录每次更改以便追踪问题的根本原因,同时,要确保备份原有的环境配置,以防出现不可逆的问题。
在这一章节中,我们探讨了Pandas环境兼容性问题的成因、诊断方法以及解决方案。通过上述内容,读者应能更好地理解并解决在Pandas使用过程中可能遇到的环境兼容性问题,为数据分析提供一个稳定的基础。接下来的章节,我们将进一步讨论如何在不同操作系统和Python版本中创建兼容的Pandas开发环境,并分享一些实用的兼容性技巧。
# 3. Pandas实践中的兼容性管理
## 3.1 创建兼容的开发环境
### 3.1.1 配置本地开发环境的最佳实践
当着手一个数据科学项目时,创建一个稳定且与生产环境兼容的本地开发环境是至关重要的一步。为了确保Pandas等数据分析工具的兼容性和性能,我们需要遵循一些最佳实践:
- **Python版本选择**:选择一个与生产环境一致的Python版本。如果生产环境运行的是Python 3.7,那么本地开发环境也应该使用该版本。
- **虚拟环境**:利用`virtualenv`或`conda`创建隔离的开发环境。这可以避免不同项目间依赖包版本的冲突,并且能够保持系统的干净。
- **依赖管理**:使用`requirements.txt`或`environment.yml`文件来管理依赖。在文件中明确列出所有的包及其版本,以确保在不同环境中复现相同的环境。
- **环境预置**:为开发环境设置特定的环境变量,比如用于数据库连接的凭证,这样可以确保在开发和部署时行为一致。
- **代码编辑器配置**:使用代码编辑器或IDE,比如PyCharm或VSCode,并且安装相应的Pandas插件或配置linter,以提高代码质量和效率。
- **版本控制**:将代码存储在版本控制系统中,如Git。这样可以追踪代码的变更,协作开发,并利用分支管理进行兼容性测试。
### 3.1.2 利用Docker容器化技术简化环境配置
Docker容器化技术是解决环境配置问题的一个强大工具。它允许开发者在隔离的容器中运行应用程序,这些容器包含了运行应用程序所需的全部依赖。以下是使用Docker来创建兼容性环境的步骤:
1. **创建Dockerfile**:编写一个Dockerfile来定义容器环境。指定基础镜像、安装系统级别的依赖、安装Python和Pandas,以及其他任何需要的包。
```Dockerfile
# 使用Python官方镜像作为基础
FROM python:3.7-slim
# 安装依赖
RUN apt-get update && apt-get install -y \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# 设置工作目录并复
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了有关 Python 数据处理库 Pandas 的全面指南,涵盖从安装和配置到性能优化和企业级部署的各个方面。专栏文章包括:
* 新手友好的 Pandas 安装和配置指南
* 深入了解 Pandas 库的安装和配置选项
* 适用于 Python 开发人员的 IDE 环境配置指南
* 优化 Pandas 安装时间和配置效率的技巧
* 大规模部署 Pandas 的策略和环境配置指南
无论您是 Pandas 新手还是经验丰富的专家,本专栏都将为您提供所需的知识和见解,以有效地安装、配置和优化 Pandas,从而提升您的数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【故障排查必读】:快速诊断H5U通讯MODBUS地址编码问题

参考资源链接:[汇川H5U MODBUS通讯协议详解:地址编码与功能码](https://wenku.csdn.net/doc/7cv6r0ddo0?spm=1055.2635.3001.10343)
# 1. MODBUS通讯协议基础
MODBUS通讯协议是工业界广泛使用的标准协议之一,主要用于连接电子设备,如PLC(可编程逻辑控制器)、HMI(人机界面)和各种传感器。由于其简单、开放、稳定的特点,MODBUS协议在自动化领域
数字电路中的锁相环应用:Bang-Bang鉴相器实践案例全解析(实操必读)

参考资源链接:[全数字锁相环设计:Bang-Bang鉴相器方法](https://wenku.csdn.net/doc/4age7xu0ed?spm=1055.2635.3001.10343)
# 1. 锁相环技术概述
锁相环技术是现代通信和电子系统中的一项核心技术,它能够使输出信号与输入信号的频率和相位同步,从而确保信息传输的准确性和系统的稳定性。本章将简要
HiSuite Proxy 性能调优:10大策略加速你的服务响应

参考资源链接:[自建服务器救活HiSuite Proxy:华为手机固件降级教程](https://wenku.csdn.net/doc/75v5f9ufki?spm=1055.2635.3001.10343)
# 1. HiSuite Proxy 概述与性能重要性
HiSuite Proxy 是一款先进的
【大数据时代】Power BI性能优化:提升数据处理效率的秘诀

参考资源链接:[Power BI中文教程:企业智能与数据分析实战](https://wenku.csdn.net/doc/6401abfecce7214c316ea403?spm=1055.2635.3001.10343)
#
SIMCA 14核心工具掌握:10分钟快速入门教程!
参考资源链接:[SIMCA 14 用户手册:全方位数据分析指南](https://wenku.csdn.net/doc/3f5cnjutvk?spm=1055.2635.3001.10343)
# 1. SIMCA 14核心工具简介
SIMCA 14是一款由UMET
【网络监控必备】:MG-SOFT MIB Browser的SNMP配置技巧

参考资源链接:[MG-SOFT MIB_Browser操作指南:SNMP测试与设备管理](https://wenku.csdn.net/doc/40jsksyaub?spm=1055.2635.3001.10343)
# 1. SNMP协议概述与MIB Browser简介
网络管理协议简单网络管理协议(SNMP)是用于管理设备,如服务器、工作站、交换机、路由器和其他网络设备的工业
数据可视化艺术课:Jaspersoft Studio图表与图形展示技巧

参考资源链接:[Jaspersoft Studio用户指南:7.1版中文详解](https://wenku.csdn.net/doc/6460a529543f84448890afd6?spm=1055.2635.3001.10343)
# 1. 数据可视化与Jaspersoft Studio概述
数据可视化是一个将复杂数据集转换为图形表示的过程,
【Day1-AM_CONVERGE性能提升】:掌握这9个技巧,提升系统效率

参考资源链接:[CONVERGE 2.4版教程:入门指南与关键功能介绍](https://wenku.csdn.net/doc/6401aca0cce7214c316ec881?spm=1055.2635.3001.10343)
# 1. Day1-AM_CONVERGE系统概述
## 1.1 系统简介
Day1-AM_CONVERGE是为了解决现代企业复杂数据处理需求而设计的先进数据管理系统。它结合了传统数据处
无人机定点投放中的传感器应用与数据融合技术
参考资源链接:[无人机定点投放:动力学模型与优化算法研究](https://wenku.csdn.net/doc/4v125uxafr?spm=1055.2635.3001.10343)
# 1. 无人机定点投放简介
在现代社会中,无人机的应用已经越来越广泛,不仅在军事领域,在农业、救灾、摄影等多个民用领域也有着重要的作用。无人
数据交换秘籍:如何在CANape中实现与MATLAB Simulink的高效对接
参考资源链接:[CANape中Matlab Simulink模型的集成与应用](https://wenku.csd
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )