【Pandas性能优化】:减少安装时间与提升配置效率
发布时间: 2024-12-07 09:26:08 阅读量: 17 订阅数: 18 

dynamo-pandas:轻松处理熊猫数据和AWS DynamoDB
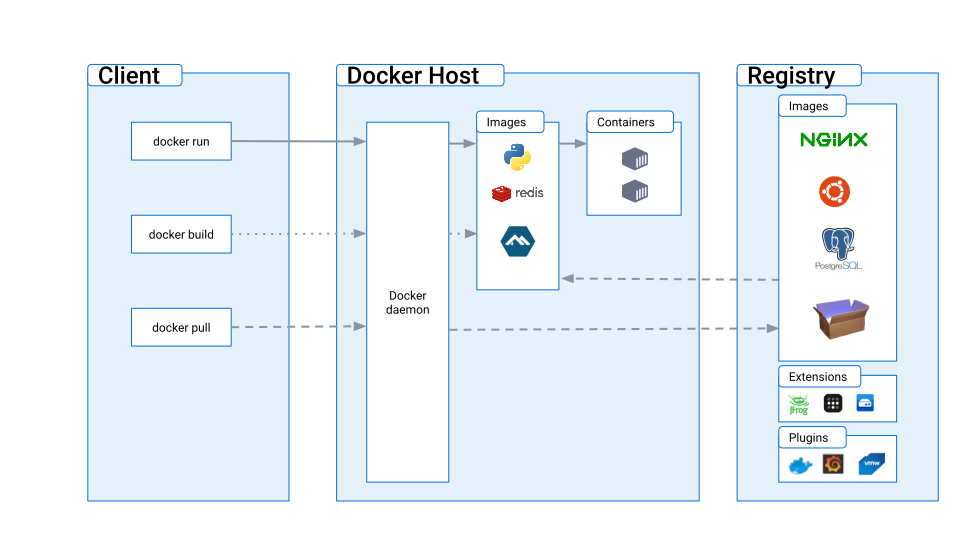
# 1. Pandas性能优化概述
Pandas是一个广泛使用的Python数据分析库,它提供了快速、灵活和表达力强的数据结构,旨在使"关系"或"标签"数据分析工作既简单又直观。然而,随着数据集的大小和复杂性增加,Pandas操作的性能可能会成为瓶颈。在本章中,我们将概述Pandas性能优化的重要性、目标和基本方法。我们将讨论性能优化对数据分析流程的影响,以及它如何帮助数据科学家、分析师和工程师更有效地处理数据。此外,本章还将为接下来的章节奠定基础,详细探讨如何在安装、数据处理、内存管理和代码实践等方面进行性能优化。
# 2. ```
# 第二章:Pandas安装过程的性能优化
在当今的数据分析领域,Pandas库已成为不可或缺的工具之一,它为Python提供了高性能、易于使用的数据结构和数据分析工具。然而,Pandas的安装过程以及后续的性能优化往往容易被忽略,但实际上,这些初期步骤对最终的数据处理性能有显著的影响。本章将深入探讨如何在Pandas安装过程中优化性能,确保数据分析工作事半功倍。
## 2.1 环境准备与依赖管理
### 2.1.1 Python环境的选择与配置
选择一个合适的Python环境对于Pandas的安装和后续性能优化至关重要。Pandas对Python版本有一定的要求,通常建议使用最新的稳定版本。安装Python时,推荐使用虚拟环境,如virtualenv或conda环境,这样可以避免系统级的包冲突,并且可以为每个项目维护一个独立的依赖环境。
例如,使用conda创建一个新的虚拟环境的命令如下:
```bash
conda create -n pandas_env python=3.8
```
### 2.1.2 系统依赖的优化处理
除了Python环境本身,Pandas安装过程中还需要许多系统依赖。在Linux系统中,可以使用包管理器来安装这些依赖。例如,在Debian或Ubuntu上,可以使用以下命令安装所需的系统依赖:
```bash
sudo apt-get install libpython3-dev libxml2-dev libxslt1-dev zlib1g-dev libcurl4-openssl-dev
```
这些依赖项包括Python的开发头文件,以及处理HTML、XML数据和网络请求所需的库。正确配置这些依赖可以保证Pandas及其依赖库如NumPy、Cython等的顺利安装。
## 2.2 Pandas安装的快速途径
### 2.2.1 使用预编译的二进制包
Pandas的安装可以使用预编译的二进制包,这是最简单也是最快的方式。在支持的平台上,这可以通过pip轻松完成:
```bash
pip install pandas
```
这种方法利用了预编译的wheel包,可以节省编译时间,并且通常能在大多数系统上正常工作。
### 2.2.2 利用conda加速安装
对于一些复杂依赖的包,或者在不支持预编译二进制包的平台(如某些Linux发行版或MacOS)上,conda提供了强大的包管理和安装功能。使用conda进行Pandas安装的一个好处是它能够解决许多复杂的依赖关系问题。
```bash
conda install pandas
```
### 2.2.3 源码安装的性能考量
在某些情况下,可能需要从源码安装Pandas,特别是在需要特定性能优化或者有定制化需求时。从源码安装的过程涉及编译过程,相比二进制安装要耗时得多,但可以进行高度定制化的配置。
```bash
git clone https://github.com/pandas-dev/pandas.git
cd pandas
python setup.py install
```
在编译过程中,可以通过设置编译选项来优化安装后的性能,例如,针对机器的CPU架构进行优化。
## 2.3 避免常见的安装陷阱
### 2.3.1 兼容性问题的诊断与解决
安装Pandas时可能会遇到版本不兼容的问题,尤其是与其他库的兼容性。此时,需要明确了解不同库之间的依赖关系。例如,某些旧版本的库可能不支持最新的Pandas版本,或者某些库可能在特定操作系统上不可用。
可以通过pip的`--upgrade`选项来更新所有已安装的包到最新版本,以解决兼容性问题:
```bash
pip install --upgrade pandas scipy
```
### 2.3.2 系统资源限制对安装的影响
系统资源限制,如内存不足,也会对Pandas的安装过程造成影响。安装大型包时,需要确保系统有足够的资源来处理编译和安装过程中的临时文件。
可以通过监控系统资源的使用情况,或在安装前清理不必要的文件和缓存,来为Pandas的安装腾出更多资源。
```bash
df -h # 查看磁盘空间使用情况
free -m # 查看内存使用情况
```
在确认资源充足后,再进行Pandas的安装,以避免中途失败导致的资源浪费。
总结本章内容,Pandas的安装过程是性能优化的第一步。选择合适的Python环境,妥善管理依赖,选择快速的安装途径,以及避免常见的安装陷阱,这些都将为后续的数据处理打下良好的基础。接下来的章节,我们将深入探讨如何在数据处理环节进一步优化Pandas的性能。
```
以上章节内容充分地覆盖了Pandas安装过程中的性能优化,从环境准备、安装途径选择到常见问题的解决策略,并且提供了详细的命令和操作步骤,以帮助读者更加高效地安装和使用Pandas。
# 3. Pandas数据处理的性能提升策略
在数据科学领域,Pandas 库是处理结构化数据的强大工具。但是,数据量的大小和复杂性可能导致性能瓶颈。本章节将深入探讨Pandas数据处理过程中的性能提升策略。我们将从数据读取与存储的优化、高效的数据操作方法,以及内存管理与优化的技巧三个方面来分析。
## 3.1 数据读取与存储的优化
### 3.1.1 快速读取数据的方法
在处理大型数据集时,读取数据的速度至关重要。Pandas 提供了几种读取数据的方法,其中`read_csv`和`read_excel`是最常用的两个函数。为了加快读取速度,我们可以采取以下策略:
- 使用`dtype`参数指定列的数据类型,可以减少数据类型的自动推断时间。
- 使用`chunksize`参数分块读取数据,这有助于避免内存溢出和加速处理。
- 利用`usecols`参数仅读取需要的列,减少数据加载的内存占用。
代码示例:
```python
import pandas as pd
# 分块读取
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# 处理每个数据块
process(chunk)
# 仅读取特定列
df = pd.read_csv('large_dataset.csv', usecols=['col1', 'col2', 'col3'])
```
- 在使用`read_csv`时,可以通过`nrows`参数来限制读取的行数,这在数据探索阶段非常有用,可以帮助我们快速理解数据结构。
### 3.1.2 数据存储格式的选择
存储数据时,选择合适的数据格式同样重要。Pandas 支持多种数据存储格式,如 CSV、HDF5、Parquet 和 Excel 等。不同的存储格式具有不同的性能优势:
- **CSV**:通用性好,但存储效率较低,适合轻量级数据交换。
- **HDF5**:适合存储和读取大型数据集,支持数据的分块和压缩,但写入速度较慢。
- **Parquet**:基于列存储,支持数据压缩和编码,读写速度快,适合大数据量的处理。
- **Excel**:适合小数据量,支持多种操作系统,但处理速度慢且占用空间大。
对于大数据集,Parquet 格式通常是最佳选择,因为它不仅读写速度快,而且可以有效地压缩数据。以下是如何使用 Parquet 格式读写数据的示例:
```python
# 将 DataFrame 写入 Parquet 文件
df.to_parquet('data.parquet')
# 从 Parquet 文件读取
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了有关 Python 数据处理库 Pandas 的全面指南,涵盖从安装和配置到性能优化和企业级部署的各个方面。专栏文章包括:
* 新手友好的 Pandas 安装和配置指南
* 深入了解 Pandas 库的安装和配置选项
* 适用于 Python 开发人员的 IDE 环境配置指南
* 优化 Pandas 安装时间和配置效率的技巧
* 大规模部署 Pandas 的策略和环境配置指南
无论您是 Pandas 新手还是经验丰富的专家,本专栏都将为您提供所需的知识和见解,以有效地安装、配置和优化 Pandas,从而提升您的数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【制造工艺升级秘籍】:DIN 5480标准下的渐开线花键加工技术详解
参考资源链接:[DIN 5480: 渐开线花键技术规范详解](https://wenku.csdn.net/doc/6k18cpv1qq?spm=1055.2635.3001.10343)
# 1. DIN 5480标准概述
在当今复杂的工程设计和制
【专家解读】:H5U通讯与MODBUS协议的100%兼容性秘籍

参考资源链接:[汇川H5U MODBUS通讯协议详解:地址编码与功能码](https://wenku.csdn.net/doc/7cv6r0ddo0?spm=1055.2635.3001.10343)
# 1. H5U通讯与MODBUS协议概述
在信息技术的不断进步中,H5U通讯技术以其高效、稳定和易于维护的特点在工业控制领域中获得了广泛的关注。与此同时,MODBUS协议作为工业通信中最为
SIMCA 14核心工具掌握:10分钟快速入门教程!
参考资源链接:[SIMCA 14 用户手册:全方位数据分析指南](https://wenku.csdn.net/doc/3f5cnjutvk?spm=1055.2635.3001.10343)
# 1. SIMCA 14核心工具简介
SIMCA 14是一款由UMET
【CMOS或门设计】:深入掌握设计方法与实现技巧
参考资源链接:[掌握CMOS与非/或非门版图设计:原理图与仿真实战](https://wenku.csdn.net/doc/4f6w6qtz7b?spm=1055.2635.3001.10343)
# 1. CMOS逻辑门基础知识
在这一章节中,我们将打下坚实的理论基础,为深入探讨CMOS或门的高级设计与优化奠定基石。首先介绍CMOS(互补金属氧化物半导体)技术的核心优势,它如何实现低功耗设计,并且拥有较高的噪声容限。接着,我们将探讨CMOS逻辑门的基本工作原理,涉及NMOS和PMOS晶体管的导电性差异及其如何协作完成逻辑运算。此外,本章还将简述CMOS技术的历史背景和它在现代集成电路中的重
【MG-SOFT MIB Browser自动化进阶】:实战高级脚本编写
参考资源链接:[MG-SOFT MIB_Browser操作指南:SNMP测试与设备管理](https://wenku.csdn.net/doc/40jsksyaub?spm=1055.2635.3001.10343)
# 1. MG-SOFT MIB Browser自动化简介
## 1.1 自动化的驱动力
在当今快速发展的信息技术领域,网络和
【PADS Router自动化设计脚本】:简化设计流程,提升工作效率

参考资源链接:[PADS Router全方位教程:从布局到高速布线](https://wenku.csdn.net/doc/1w7vayrbdc?spm=1055.2635.3001.10343)
三菱PLC通信进阶指南:台达VFD-L变频器控制指令全解析

参考资源链接:[三菱PLC与台达VFD-L变频器RS485通讯详解及设置](https://wenku.csdn.net/doc/6451ca45ea0840391e7382a7?spm=1055.2635.3001.10343)
# 1. 三菱PLC与台达VFD-L变频器通信概述
在自动化控制系统中,三菱PLC(可编程逻辑控制器)和台达VFD-L系列变频器的协同
数字信号处理入门秘籍:5个核心概念让你一学就会
参考资源链接:[数字信号处理(第三版)PPT课件](https://wenku.csdn.net/doc/645f4789543f8444888b11a3?spm=1055.2635.3001.10343)
# 1. 数字信号处理概述
数字信号处理(Digital Signal Processing,简称DSP)是信息技术领域的一个重要分支,它通过数字计算机或专用处理器,对各种信号进行采集、变换、滤波、估值和识别等处理,广泛应用于通信、音频、视频、雷达、生物医学等领域。在本章中,我们将对数字信号处理的基础概念、历史发展以及基本工作原理进行概述。
## 1.1 信号与数字信号处理
信号可以看
微信小程序分页视图组件详解:代码与最佳实践的完美结合
参考资源链接:[微信小程序滑动翻页效果实现教程](https://wenku.csdn.net/doc/6459ff3bfcc5391368262691?spm=1055.2635.3001.10343)
# 1. 微信小程序分页视图组件基础
微信小程序作为一种轻量级应用,其用户界面需要支持流畅的浏览体验。分页视图组件是实现这一目标的重要工具。在本章中,我们将首先介绍分页视图组件的基本
全数字锁相环设计挑战全解:误码率降低与Bang-Bang鉴相器的对策(通信稳定性提升策略)

参考资源链接:[全数字锁相环设计:Bang-Bang鉴相器方法](https://wenku.csdn.net/doc/4age7xu0ed?s
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )