【Pandas高效安装指南】:专家级配置与性能优化
发布时间: 2024-12-07 08:41:11 阅读量: 10 订阅数: 18 

Pandas实战指南:数据分析的Python利器
# 1. Pandas简介与安装基础
## 1.1 Pandas概述
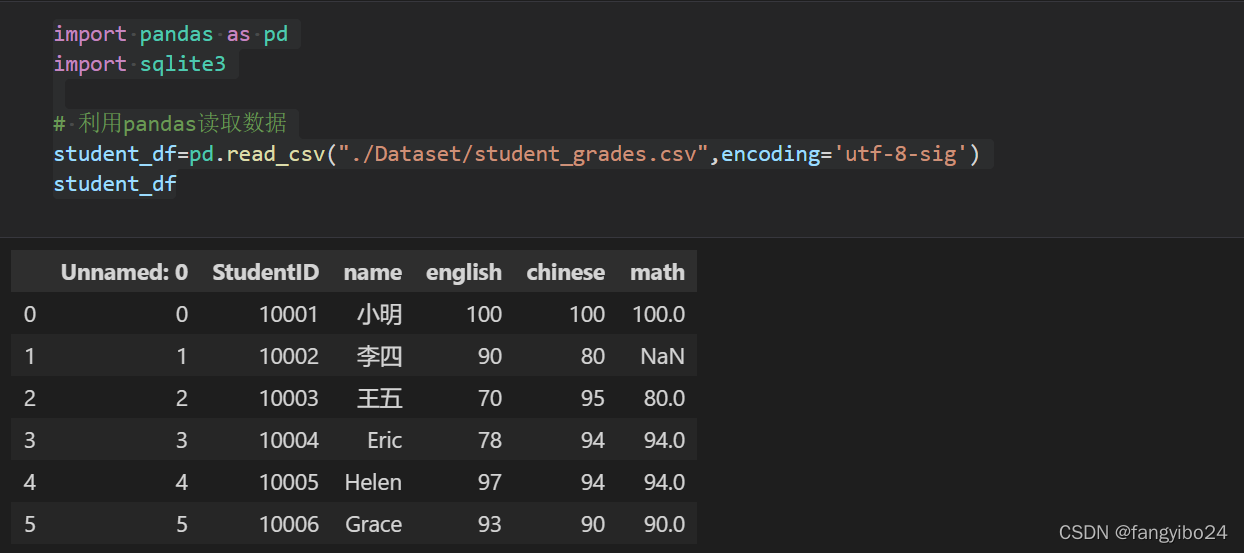
Pandas是一个开源的Python数据分析库,它提供了高性能、易用的数据结构和数据分析工具。在数据处理、清洗、分析和可视化等方面拥有广泛的应用。Pandas的主要数据结构包括Series和DataFrame,前者是一维数组结构,后者是二维表格结构。Pandas之所以受到数据分析从业者的青睐,是因为它的强大功能和简洁的API设计,使得处理复杂的数据集变得轻而易举。
## 1.2 Pandas的安装
要开始使用Pandas,首先需要在你的系统上安装Python。接下来,可以通过Python包管理工具pip或conda来安装Pandas。对于大部分用户来说,使用pip或conda安装Pandas是非常直接的。
### 1.2.1 pip安装Pandas
打开命令行工具,并输入以下命令:
```shell
pip install pandas
```
这个命令会从Python包索引(PyPI)下载并安装最新版本的Pandas。
### 1.2.2 conda安装Pandas
如果你使用的是Anaconda或者Miniconda,推荐使用conda来安装Pandas,因为它能自动处理依赖关系,并为Windows用户提供预编译的二进制文件。在conda环境中,安装Pandas的命令如下:
```shell
conda install pandas
```
以上两个方法都提供了基础安装Pandas的方式,之后章节会深入探讨更多高级和优化的安装技巧。在安装完成后,我们便可以开始着手进行数据的初步探索和分析工作。
# 2. Pandas的高效安装方法
## 2.1 官方安装渠道分析
### 2.1.1 pip安装Pandas
Pip 是 Python 的官方包管理工具,其简化了 Python 包的安装过程。Pandas 可以通过 pip 直接安装,不过在此之前,确保你已经安装了 pip,并且环境中的 Python 版本是符合安装 Pandas 的版本要求。以下是一个使用 pip 安装 Pandas 的基本步骤:
```bash
pip install pandas
```
该命令会连接到 Python 包索引(PyPI)并下载最新的 Pandas 版本。需要注意的是,不同的 Python 版本可能支持的 Pandas 版本不同。安装完成后,可以通过 Python 解释器检查是否安装成功:
```python
import pandas as pd
print(pd.__version__)
```
如果输出了版本号,则表示安装成功。通过 pip 安装是最简单的方式,它默认会安装所需的依赖包,如 NumPy 等,但有时可能因为网络问题或包的依赖冲突导致安装失败。
### 2.1.2 conda安装Pandas
Conda 是一个开源的包、依赖和环境管理系统,主要用于科学计算,广泛应用于 Python 程序的包管理中。与 pip 不同,conda 不仅管理 Python 包,还管理 Python 的环境。这为安装和管理多个版本的 Python 和其包提供了极大的便利。以下是使用 conda 安装 Pandas 的步骤:
```bash
conda install pandas
```
Conda 会将 Pandas 及其依赖自动安装到当前的环境。如果安装过程中遇到包版本冲突,Conda 会尝试解决依赖关系,并且可能会安装不同版本的包以避免冲突。Conda 还允许用户创建多个环境,这对于需要在不同项目之间切换不同版本库的情况十分有用。
## 2.2 优化安装过程
### 2.2.1 使用虚拟环境
虚拟环境是 Python 项目中的一种环境隔离技术,它允许项目在不同版本的依赖之间进行独立管理。虚拟环境使用起来非常方便,尤其是在需要安装多个版本的包或是在进行多个项目的开发时。安装 Pandas 之前,我们可以使用 virtualenv 或 venv 创建一个隔离的环境:
```bash
# 使用 virtualenv 创建虚拟环境
virtualenv myenv
# 激活虚拟环境(Linux/MacOS)
source myenv/bin/activate
# 激活虚拟环境(Windows)
myenv\Scripts\activate
```
安装完虚拟环境并激活后,再使用 pip 或 conda 安装 Pandas,这样可以避免对系统 Python 环境造成影响。
### 2.2.2 依赖项管理和冲突解决
安装 Pandas 时,Pip 或 Conda 会自动处理依赖关系。但在一些特殊情况下,依赖项可能会发生冲突,导致安装失败。解决依赖冲突的方法通常有:
- 使用特定版本的包,例如 `pip install package==version`
- 修复或更新依赖包,以解决不兼容问题
- 使用 `--ignore-installed` 参数来忽略已安装包的版本,强制安装新的版本
- 手动管理依赖包,先确定冲突的包,然后逐个解决
在处理依赖项时,合理的管理策略和工具(如 conda 的 `conda env export` 和 `conda env create` 命令)会提供很大的帮助。
## 2.3 高级安装技术
### 2.3.1 使用Docker容器化部署
Docker 是一种容器化平台,可以轻松地创建、部署和运行应用程序。容器是应用程序及其依赖项的可移植包,它可以确保在任何系统中运行时的一致性。使用 Docker 安装 Pandas,首先需要创建一个 Dockerfile,定义好所需的基础镜像和安装步骤:
```Dockerfile
# 使用 Python 官方镜像作为基础镜像
FROM python:3.8-slim
# 安装 Pandas 和其他依赖
RUN pip install pandas matplotlib scipy
# 设置工作目录
WORKDIR /app
# 复制应用源代码到容器内
COPY . /app
# 运行命令
CMD ["python", "./your_script.py"]
```
之后,使用 `docker build` 命令构建 Docker 镜像,再通过 `docker run` 运行容器:
```bash
docker build -t pandas-env .
docker run -it pandas-env
```
这种方法适合于需要构建一致开发和生产环境的场景,尤其是团队协作中环境配置不一致的问题。
### 2.3.2 编译安装源码包
如果你需要最新版本的 Pandas,或者你有特别的安装需求(如性能优化),你可能需要从源码编译安装。首先,从 GitHub 下载 Pandas 的源码包:
```bash
git clone https://github.com/pandas-dev/pandas.git
cd pandas
```
然后,根据官方文档中的说明进行编译安装。通常情况下,你需要先编译安装依赖项,例如 Cython、NumPy 和其他依赖库,然后才能编译安装 Pandas 本身。
```bash
python setup.py build_ext --inplace
python setup.py build
python setup.py install
```
源码安装比较复杂,需要开发者对构建过程有一定的了解,并能够解决可能出现的问题,如编译错误等。但这种方式提供了最大的灵活性,允许开发者对最终的安装包进行优化和定制。
# 3. Pandas环境配置与性能优化
## 3.1 环境变量配置
### 3.1.1 Python路径配置
配置环境变量中Python的路径对于Pandas的安装与运行至关重要。在多数操作系统中,系统需要知道在哪里可以找到Python解释器和相关的库。例如,在Unix或类Unix系统中,你可以通过编辑`~/.bash_profile`或`~/.bashrc`文件(取决于你的shell环境)来设置环境变量。而在Windows系统中,你可以通过控制面板中的“系统”设置来配置。
以在Unix系统下配置环境变量为例,可以使用以下命令:
```bash
export PATH=/path/to/python/bin:$PATH
```
请将`/path/to/python/bin`替换为实际Python解释器的安装路径。这样做之后,可以在命令行中直接调用Python和Pandas。
### 3.1.2 库依赖路径配置
除了Python解释器的路径外,如果Pandas及其依赖的库安装在非标准路径,同样需要配置环境变量。特别是在使用虚拟环境时,每个虚拟环境的库路径通常是独立的,需要单独配置。
```bash
export PYTHONPATH=/path/to/pip/lib/pythonX.X/site-packages:$PYTHONPATH
```
将`/path/to/pip/lib/pythonX.X/site-packages`替换为实际的site-packages路径。对于虚拟环境,通常位于虚拟环境目录下,比如`/home/user/venv/lib/python3.8/site-packages`。
## 3.2 性能基准测试
### 3.2.1 测试环境搭建
进行性能基准测试前,需要搭建一个稳定的测试环境,这个环境应当模拟生产环境的硬件、软件配置。首先,创建一个干净的虚拟环境以确保测试不受其他库的影响:
```bash
python -m venv test_env
source test_env/bin/activate
```
在虚拟环境中,安装Pandas以及用于基准测试的库如`timeit`,然后可以开始准备你的测试脚本。
### 3.2.2 性能指标与评估方法
性能基准测试通常关注两个主要指标:执行时间和内存消耗。执行时间可以通过Python内置的`timeit`模块来测量,而内存消耗则可以借助`memory_profiler`模块进行评估。
以下是一个简单的例子来展示如何使用`timeit`模块:
```python
import timeit
# 假设我们有一个简单的Pandas操作
setup = '''
import pandas as pd
df = pd.DataFrame({'a': range(1000), 'b': range(1000)})
# 测量特定操作的执行时间
time = timeit.timeit('df.head()', setup=setup, number=1000)
print(f'执行时间: {time} 秒')
```
`memory_profiler`模块可以提供更加详细的内存消耗情况:
```python
# 需要安装memory_profiler模块
%load_ext memory_profiler
# 使用 @profile 装饰器来标记需要分析内存消耗的函数
from memory_profiler import profile
@profile
def tes
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了有关 Python 数据处理库 Pandas 的全面指南,涵盖从安装和配置到性能优化和企业级部署的各个方面。专栏文章包括:
* 新手友好的 Pandas 安装和配置指南
* 深入了解 Pandas 库的安装和配置选项
* 适用于 Python 开发人员的 IDE 环境配置指南
* 优化 Pandas 安装时间和配置效率的技巧
* 大规模部署 Pandas 的策略和环境配置指南
无论您是 Pandas 新手还是经验丰富的专家,本专栏都将为您提供所需的知识和见解,以有效地安装、配置和优化 Pandas,从而提升您的数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【制造工艺升级秘籍】:DIN 5480标准下的渐开线花键加工技术详解
参考资源链接:[DIN 5480: 渐开线花键技术规范详解](https://wenku.csdn.net/doc/6k18cpv1qq?spm=1055.2635.3001.10343)
# 1. DIN 5480标准概述
在当今复杂的工程设计和制
【专家解读】:H5U通讯与MODBUS协议的100%兼容性秘籍

参考资源链接:[汇川H5U MODBUS通讯协议详解:地址编码与功能码](https://wenku.csdn.net/doc/7cv6r0ddo0?spm=1055.2635.3001.10343)
# 1. H5U通讯与MODBUS协议概述
在信息技术的不断进步中,H5U通讯技术以其高效、稳定和易于维护的特点在工业控制领域中获得了广泛的关注。与此同时,MODBUS协议作为工业通信中最为
SIMCA 14核心工具掌握:10分钟快速入门教程!
参考资源链接:[SIMCA 14 用户手册:全方位数据分析指南](https://wenku.csdn.net/doc/3f5cnjutvk?spm=1055.2635.3001.10343)
# 1. SIMCA 14核心工具简介
SIMCA 14是一款由UMET
【CMOS或门设计】:深入掌握设计方法与实现技巧
参考资源链接:[掌握CMOS与非/或非门版图设计:原理图与仿真实战](https://wenku.csdn.net/doc/4f6w6qtz7b?spm=1055.2635.3001.10343)
# 1. CMOS逻辑门基础知识
在这一章节中,我们将打下坚实的理论基础,为深入探讨CMOS或门的高级设计与优化奠定基石。首先介绍CMOS(互补金属氧化物半导体)技术的核心优势,它如何实现低功耗设计,并且拥有较高的噪声容限。接着,我们将探讨CMOS逻辑门的基本工作原理,涉及NMOS和PMOS晶体管的导电性差异及其如何协作完成逻辑运算。此外,本章还将简述CMOS技术的历史背景和它在现代集成电路中的重
【MG-SOFT MIB Browser自动化进阶】:实战高级脚本编写
参考资源链接:[MG-SOFT MIB_Browser操作指南:SNMP测试与设备管理](https://wenku.csdn.net/doc/40jsksyaub?spm=1055.2635.3001.10343)
# 1. MG-SOFT MIB Browser自动化简介
## 1.1 自动化的驱动力
在当今快速发展的信息技术领域,网络和
【PADS Router自动化设计脚本】:简化设计流程,提升工作效率

参考资源链接:[PADS Router全方位教程:从布局到高速布线](https://wenku.csdn.net/doc/1w7vayrbdc?spm=1055.2635.3001.10343)
三菱PLC通信进阶指南:台达VFD-L变频器控制指令全解析

参考资源链接:[三菱PLC与台达VFD-L变频器RS485通讯详解及设置](https://wenku.csdn.net/doc/6451ca45ea0840391e7382a7?spm=1055.2635.3001.10343)
# 1. 三菱PLC与台达VFD-L变频器通信概述
在自动化控制系统中,三菱PLC(可编程逻辑控制器)和台达VFD-L系列变频器的协同
数字信号处理入门秘籍:5个核心概念让你一学就会
参考资源链接:[数字信号处理(第三版)PPT课件](https://wenku.csdn.net/doc/645f4789543f8444888b11a3?spm=1055.2635.3001.10343)
# 1. 数字信号处理概述
数字信号处理(Digital Signal Processing,简称DSP)是信息技术领域的一个重要分支,它通过数字计算机或专用处理器,对各种信号进行采集、变换、滤波、估值和识别等处理,广泛应用于通信、音频、视频、雷达、生物医学等领域。在本章中,我们将对数字信号处理的基础概念、历史发展以及基本工作原理进行概述。
## 1.1 信号与数字信号处理
信号可以看
微信小程序分页视图组件详解:代码与最佳实践的完美结合
参考资源链接:[微信小程序滑动翻页效果实现教程](https://wenku.csdn.net/doc/6459ff3bfcc5391368262691?spm=1055.2635.3001.10343)
# 1. 微信小程序分页视图组件基础
微信小程序作为一种轻量级应用,其用户界面需要支持流畅的浏览体验。分页视图组件是实现这一目标的重要工具。在本章中,我们将首先介绍分页视图组件的基本
全数字锁相环设计挑战全解:误码率降低与Bang-Bang鉴相器的对策(通信稳定性提升策略)

参考资源链接:[全数字锁相环设计:Bang-Bang鉴相器方法](https://wenku.csdn.net/doc/4age7xu0ed?s
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )