【Python虚拟环境下的Pandas】:安装管理与版本控制详解
发布时间: 2024-12-07 08:53:12 阅读量: 12 订阅数: 18 

详解Python中pandas的安装操作说明(傻瓜版)
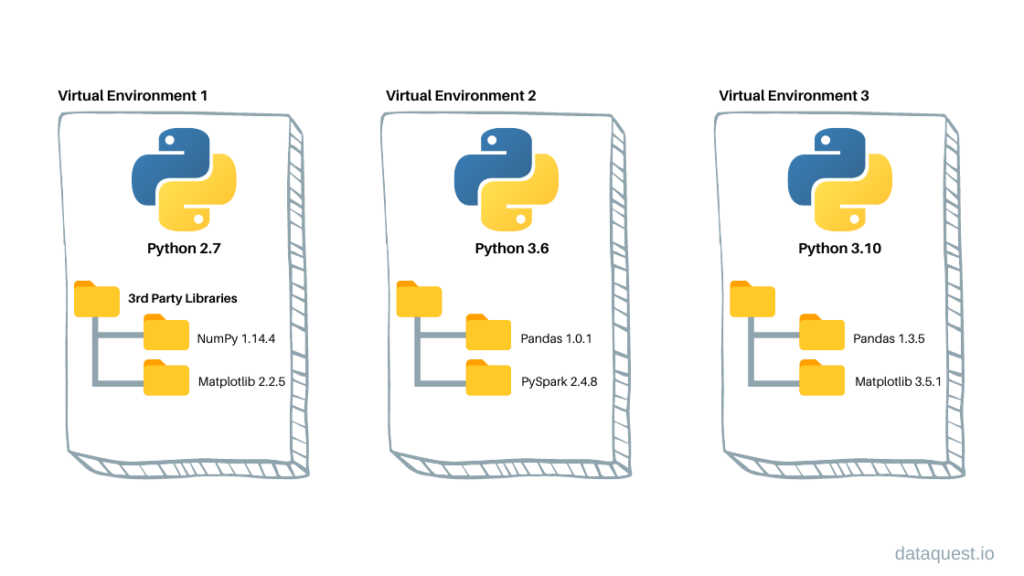
# 1. Python虚拟环境的必要性与搭建
在Python开发中,虚拟环境是不可或缺的一部分,它允许开发者在隔离的环境中工作,避免了包版本间的冲突,同时使得环境管理变得更为高效。本章节将详细探讨虚拟环境的必要性,并指导读者完成一个虚拟环境的搭建。
## 1.1 Python虚拟环境的必要性
在开发Python应用程序时,很可能需要不同版本的依赖包,或者不同的库可能有相同的依赖但版本不同,这会导致无法同时安装这些依赖。虚拟环境通过提供隔离的工作空间,解决了这一问题。此外,它也帮助开发者避免了不同项目间的依赖冲突,为项目部署提供了清晰的环境配置。
## 1.2 搭建Python虚拟环境
最常用的虚拟环境搭建工具是`venv`和`virtualenv`。以下是使用`venv`在Python 3中创建虚拟环境的步骤:
```bash
# 安装虚拟环境工具
$ pip install venv
# 创建一个名为env的虚拟环境目录
$ python -m venv env
# 激活虚拟环境(Windows)
$ env\Scripts\activate
# 激活虚拟环境(Unix或MacOS)
$ source env/bin/activate
# 退出虚拟环境
$ deactivate
```
创建虚拟环境后,您可以安装所需的包,比如Pandas,而不用担心影响系统级的Python安装。
总结来说,虚拟环境的使用不仅提高了项目的可管理性,也增强了开发过程的灵活性。接下来的章节将会详细介绍Pandas库的安装与管理,并通过实例来展示Pandas在数据处理中的强大功能。
# 2. Pandas库的安装与管理
## 2.1 Pandas库安装基础
### 2.1.1 虚拟环境下的Pandas安装
在开始安装Pandas之前,创建一个隔离的虚拟环境是推荐的实践。这可以避免系统级安装可能带来的依赖冲突和版本问题。虚拟环境的创建和管理通常使用 `venv` 或 `conda`。以下将展示使用 `conda` 创建虚拟环境并安装Pandas的步骤:
1. 安装 `conda`:
```bash
# 下载并安装Anaconda或Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
```
2. 创建一个新的conda环境:
```bash
conda create -n pandas_env python=3.8 pandas
```
3. 激活虚拟环境:
```bash
conda activate pandas_env
```
激活环境后,您可以在该环境中进行Pandas库的安装和管理。这种方法确保了Pandas及其依赖库不会与其他项目或系统级别的Python环境冲突。
### 2.1.2 环境依赖和兼容性问题
安装Pandas时,您可能需要考虑其依赖包的兼容性。Pandas库本身依赖于一些底层C库,如 `numpy`、`pytz`、`dateutil` 等。确保您的虚拟环境中安装了所有必需的依赖,并且它们彼此之间兼容,通常可以使用以下命令进行检查和安装:
```bash
# 安装Pandas及其依赖包
conda install pandas
# 或者使用pip安装
pip install pandas
```
使用 `pip` 安装Pandas时,它会尝试自动安装所有必需的依赖项,但有时仍可能遇到版本冲突。在发生冲突时,使用 `conda` 通常会更稳定,因为它会为每个包处理适当的兼容性问题。如果需要,您可以手动指定依赖包的版本,以确保兼容性:
```bash
pip install numpy==1.19.3 pandas==1.1.3
```
## 2.2 Pandas版本控制
### 2.2.1 版本控制的原理
版本控制对于管理Python包非常重要。它允许开发者在不同的版本之间切换,复原错误的更改,并与团队成员协作。在Python中,`pip` 和 `conda` 提供了版本控制的功能。
### 2.2.2 使用虚拟环境管理Pandas版本
使用虚拟环境管理不同项目的Pandas版本,可以保持每个项目所需的库版本互不影响。例如,在一个项目中,您可能需要Pandas的1.1.x版本,在另一个项目中,则可能需要1.2.x版本。这时,您可以在各自的环境中安装所需的版本:
```bash
# 在第一个虚拟环境中安装Pandas 1.1.x
conda activate env1
conda install "pandas>=1.1,<1.2"
# 在第二个虚拟环境中安装Pandas 1.2.x
conda activate env2
conda install "pandas>=1.2,<1.3"
```
使用 `conda` 环境可以更方便地在不同版本的Pandas之间切换,这对于需要遵循严格版本依赖关系的复杂项目尤其有用。
## 2.3 管理工具介绍
### 2.3.1 pip工具使用方法
`pip` 是Python的包安装程序,通常用于安装和管理Python包。使用 `pip` 安装Pandas时,可以通过以下命令:
```bash
# 安装最新版本Pandas
pip install pandas
# 安装特定版本Pandas
pip install pandas==1.1.3
```
通过 `pip list` 可以查看当前环境中安装的包及其版本信息:
```bash
pip list | grep pandas
```
若要卸载已安装的Pandas版本:
```bash
pip uninstall pandas
```
### 2.3.2 conda环境管理器简介
`conda` 不仅是一个包管理器,也是一个环境管理器,它允许您创建多个独立的环境,每个环境中可以有不同版本的包。以下是使用 `conda` 常用的一些命令:
```bash
# 创建新的conda环境
conda create -n new_env_name python=3.8 pandas
# 激活conda环境
conda activate new_env_name
# 删除conda环境
conda remove --name old_env_name --all
# 列出所有conda环境
conda env list
```
`conda` 环境不仅限于管理Pandas,它也可以用于管理其他依赖于特定Python版本的库,这对于跨平台开发尤其有用。它还支持跨多个环境复制和导出环境配置,帮助在不同的机器和用户之间复制环境。
# 3. Pandas在数据处理中的应用实践
Pandas是Python中用于数据分析和处理的重要库,广泛应用于数据清洗、准备、分析和可视化的各个阶段。本章将深入探讨Pandas的核心数据结构,介绍数据清洗与准备的方法,以及数据分析与可视化的实用技术。
## 3.1 Pandas核心数据结构
### 3.1.1 Series和DataFrame的创建与操作
在Pandas中,数据主要以两种结构形式存在:Series和DataFrame。Series是一维的标签数组,能够存储任何数据类型(整数、字符串、浮点数、Python对象等)。DataFrame则是二维的标签数据结构,可以看作是一个表格或者说是Series对象的容器。
#### 创建Series与DataFrame
创建Series和DataFrame的基本方法是使用Pandas库的构造函数。
```python
import pandas as pd
# 创建Series
s = pd.Series([1, 3, 5, np.nan, 6, 8])
# 创建DataFrame
df = pd.DataFrame({
'A': ['foo', 'bar', 'baz', 'qux'],
'B': [1, 2, 3, 4],
'C': pd.Categorical(['one', 'two', 'three', 'four'])
})
```
#### Series操作
Series的基本操作包括访问元素、切片、布尔索引等。
```python
# 访问单个元素
print(s[0]) # 输出: 1
# 切片
print(s[1:4]) # 输出: 3 5 NaN
# 布尔索引
print(s[s > 3]) # 输出: 5 NaN 6 8
```
#### DataFrame操作
DataFrame的操作更为多样,包括但不限于行与列

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了有关 Python 数据处理库 Pandas 的全面指南,涵盖从安装和配置到性能优化和企业级部署的各个方面。专栏文章包括:
* 新手友好的 Pandas 安装和配置指南
* 深入了解 Pandas 库的安装和配置选项
* 适用于 Python 开发人员的 IDE 环境配置指南
* 优化 Pandas 安装时间和配置效率的技巧
* 大规模部署 Pandas 的策略和环境配置指南
无论您是 Pandas 新手还是经验丰富的专家,本专栏都将为您提供所需的知识和见解,以有效地安装、配置和优化 Pandas,从而提升您的数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CMOS版图设计进阶】:非门与或门优化,提高设计效率
参考资源链接:[掌握CMOS与非/或非门版图设计:原理图与仿真实战](https://wenku.csdn.net/doc/4f6w6qtz7b?spm=1055.2635.3001.10343)
# 1. CMOS版图设计基础
## 1.1 概述CMOS技术
CMOS(互补金属氧化物半导体)技术作为当今集成电路设计的核心,其版图设计的优劣直接影响到芯片的性能、功耗及生产成本。
【案例分析】:如何优化H5U通讯中的MODBUS地址编码

参考资源链接:[汇川H5U MODBUS通讯协议详解:地址编码与功能码](https://wenku.csdn.net/doc/7cv6r0ddo0?spm=1055.2635.3001.10343)
# 1. MODBUS地址编码基础
MODBUS协议因其简单、开放和高效的特点,在工业通讯领域被广泛应用。本章将对MODBUS协议的地址编码进行基础性介绍,为读者构建后续章节内容的理解基
SIMCA 14核心工具掌握:10分钟快速入门教程!
参考资源链接:[SIMCA 14 用户手册:全方位数据分析指南](https://wenku.csdn.net/doc/3f5cnjutvk?spm=1055.2635.3001.10343)
# 1. SIMCA 14核心工具简介
SIMCA 14是一款由UMET
三菱PLC与台达VFD-L数据交换快速入门:RS485通信案例全解析

参考资源链接:[三菱PLC与台达VFD-L变频器RS485通讯详解及设置](https://wenku.csdn.net/doc/6451ca45ea0840391e7382a7?spm=1055.2635.3001.10343)
# 1. 三菱PLC与台达VFD-L通信概览
随着自动化技术的不断发展,工业控制系统中的设备间通信变得越来越重要。三菱PLC(可编程逻辑控制器
【PADS Router电路板设计效率提升】:最佳实践和高级技巧揭秘
参考资源链接:[PADS Router全方位教程:从布局到高速布线](https://wenku.csdn.net/doc/1w7vayrbdc?spm=1055.2635.3001.10343)
# 1. PADS Router电路板设计基础
## PADS Router简介
PADS Router是电路板设计行业中的一个常用工具,由Mentor Graphics公司开发,广泛应用于电子设计自动化(EDA)领域。它为设计工程师提供了一个强大的设计平台,用于创建多层和单层电路板的布线图。本章将为读者提供一个关于PADS Router的电路板设计基础的概览,帮助读者建立一个坚实的理解基础。
【2023版DIN 5480标准深度剖析】:渐开线花键设计与应用的最新指南
参考资源链接:[DIN 5480: 渐开线花键技术规范详解](https://wenku.csdn.net/doc/6k18cpv1qq?spm=1055.2635.3001.10343)
# 1. DIN 5480标准概述
## 1.1 标准的历史背景与重要性
DIN 5480是德国工业标准,规定了渐开线花键的几何尺寸、公差和术语。该标准自1927
高速通信背后的黑科技:Bang-Bang鉴相器在全数字锁相环中的角色(深度剖析)

参考资源链接:[全数字锁相环设计:Bang-Bang鉴相器方法](https://wenku.csdn.net/doc/4age7xu0ed?spm=1055.2635.3001.10343)
# 1. 全数字锁相环概述
## 简介
全数字锁相环(All-Digital Phase-Locked Loop, ADPLL)是现代通信系统和信号处理领域的重要组成部分。它作为一种同步技术,能够实现对输入信
【数据连接秘籍】Power BI数据连接技巧:连接各种数据源的秘密

参考资源链接:[Power BI中文教程:企业智能与数据分析实战](https://wenku.csdn.net/doc/6401abfecce7214c316ea403?spm=1055.2635.3001.10343)
# 1. Power BI数据连接概览
在数据驱动的决策时代,一个强大的数据可视化工具对于企业来
网络故障排查专家指南:MG-SOFT MIB Browser技巧与应用

参考资源链接:[MG-SOFT MIB_Browser操作指南:SNMP测试与设备管理](https://wenku.csdn.net/doc/40jsksyaub?spm=1055.2635.3001.10343)
# 1. 网络故障排查的基础知识
在信息技术的日常运维中,网络故障排查是一项至关重要的技能。故障排查不仅仅是解决当前问题的手段,更是一种对网络状态深入理解和预测潜在风险的过程。本章将介绍网络故障排查的
Jaspersoft Studio高级数据处理:计算与逻辑控制一网打尽
参考资源链接:[Jaspersoft Studio用户指南:7.1版中文详解](https://wenku.csdn.net/doc/6460a529543f84448890afd6?spm=1055.2635.3001.10343)
# 1. Jaspersoft Studio概述与环境搭建
在当今的商业智能(BI)领域,Jaspersoft Studio 作为一款流行的报表设计工具,为开发者提供了创建复杂报表的能力。本章将概述Jaspersoft Studio的基本功能,并详细介绍如何搭建开发环境,为后续深入学习和实践打下基础。
## 1.1 Jaspersoft Studio的基本功
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )