【变分自编码器(VAE)入门指南】:从基础到精通,掌握生成式模型的利器
发布时间: 2024-08-20 16:10:13 阅读量: 54 订阅数: 33 

变分自编码器(VAE)及其条件模型介绍

# 1. 变分自编码器(VAE)简介**
变分自编码器(VAE)是一种生成模型,它通过学习数据中的潜在表示来生成新的数据。VAE 的基本思想是将数据编码为一个潜在的分布,然后从该分布中采样来生成新的数据。与传统的自编码器不同,VAE 使用变分推断来近似潜在分布,这使得它能够生成更具多样性和真实性的数据。
VAE 的模型结构通常包括一个编码器和一个解码器。编码器将输入数据编码为潜在分布的参数,而解码器则从潜在分布中采样来生成重建数据。VAE 的训练过程涉及最大化证据下界(ELBO),这是一个衡量模型拟合数据质量的度量。
# 2. VAE的理论基础
### 2.1 概率生成模型和贝叶斯推理
**概率生成模型**是一种用于生成数据的数学模型。它将数据视为从一个潜在的概率分布中随机抽取的样本。概率生成模型可以分为两类:
- **显式模型:**直接对数据分布进行建模,例如高斯混合模型或隐马尔可夫模型。
- **隐式模型:**通过引入一个潜在变量来间接建模数据分布,例如变分自编码器。
**贝叶斯推理**是一种基于贝叶斯定理的推理方法,它将不确定性量化为概率。贝叶斯定理如下:
```
P(A|B) = P(B|A) * P(A) / P(B)
```
其中:
- P(A|B) 是在已知 B 的情况下 A 的后验概率。
- P(B|A) 是在已知 A 的情况下 B 的似然度。
- P(A) 是 A 的先验概率。
- P(B) 是 B 的边缘概率。
### 2.2 变分推断和证据下界(ELBO)
**变分推断**是一种近似推理方法,它通过引入一个近似分布来近似难以计算的后验分布。变分推断的目的是找到一个近似分布,使它与后验分布尽可能接近。
**证据下界(ELBO)**是变分推断中使用的度量,它衡量近似分布与后验分布之间的差异。ELBO 定义为:
```
ELBO = E_q[log p(x, z)] - E_q[log q(z|x)]
```
其中:
- p(x, z) 是联合概率分布。
- q(z|x) 是近似后验分布。
- E_q 表示对近似后验分布的期望。
ELBO 的值越大,近似分布与后验分布之间的差异越小。
### 2.3 VAE的模型结构和训练过程
**VAE 的模型结构**由两个神经网络组成:
- **编码器网络:**将输入数据 x 编码为潜在变量 z。
- **解码器网络:**将潜在变量 z 解码为重建数据 x'。
**VAE 的训练过程**包括以下步骤:
1. **采样潜在变量:**从近似后验分布 q(z|x) 中采样潜在变量 z。
2. **重建数据:**使用解码器网络将潜在变量 z 解码为重建数据 x'。
3. **计算重建误差:**计算重建数据 x' 与输入数据 x 之间的重建误差。
4. **计算 KL 散度:**计算近似后验分布 q(z|x) 与先验分布 p(z) 之间的 KL 散度。
5. **优化 ELBO:**最小化 ELBO,即最大化重建误差和 KL 散度之间的权衡。
**代码示例:**
```python
import tensorflow as tf
# 编码器网络
encoder = tf.keras.Sequential([
tf.keras.layers.Dense(units=200, activation='relu'),
tf.keras.layers.Dense(units=100, activation='relu'),
tf.keras.layers.Dense(units=2, activation='linear')
])
# 解码器网络
decoder = tf.keras.Sequential([
tf.keras.layers.Dense(units=100, activation='relu'),
tf.keras.layers.Dense(units=200, activation='relu'),
tf.keras.layers.Dense(units=784, activation='sigmoid')
])
# 采样函数
def sample_z(mu, sigma):
epsilon = tf.random.normal(shape=tf.shape(mu))
return mu + sigma * epsilon
# 训练函数
def train_vae(x_train, y_train, epochs=10):
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
for epoch in range(epochs):
for x_batch, y_batch in zip(x_train, y_train):
with tf.GradientTape() as tape:
# 编码
mu, sigma = encoder(x_batch)
z = sample_z(mu, sigma)
# 解码
x_reconstructed = decoder(z)
# 计算重建误差
reconstruction_loss = tf.keras.losses.mean_squared_error(x_batch, x_reconstructed)
# 计算 KL 散度
kl_divergence = 0.5 * tf.reduce_sum(tf.square(mu) + tf.square(sigma) - tf.log(tf.square(sigma)) - 1, axis=1)
# 计算 ELBO
elbo = tf.reduce_mean(reconstruction_loss + kl_divergence)
# 更新权重
gradients = tape.gradient(elbo, model.trainable_weights)
optimizer.apply_gradients(zip(gradients, model.trainable_weights))
# 训练 VAE
train_vae(x_train, y_train)
```
**逻辑分析:**
* 编码器网络将输入数据编码为潜在变量 z。
* 解码器网络将潜在变量 z 解码为重建数据 x'。
* 重建误差衡量重建数据与输入数据之间的差异。
* KL 散度衡量近似后验分布与先验分布之间的差异。
* ELBO 是重建误差和 KL 散度之间的权衡。
* 训练过程通过最小化 ELBO 来更新模型权重。
# 3. VAE的实践应用
### 3.1 图像生成和降维
#### 3.1.1 图像生成模型的构建和训练
**构建图像生成模型**
图像生成模型的构建涉及以下步骤:
1. **定义编码器网络:**编码器网络将输入图像编码为潜在表示。它通常由卷积层和池化层组成。
2. **定义解码器网络:**解码器网络将潜在表示解码为重建的图像。它通常由卷积层和上采样层组成。
3. **定义损失函数:**损失函数衡量重建图像与原始图像之间的差异。常用的损失函数包括均方误差 (MSE) 和交叉熵损失。
**训练图像生成模型**
图像生成模型的训练过程如下:
1. **收集数据集:**收集一组高质量的图像数据集。
2. **预处理数据:**对图像进行预处理,例如调整大小、归一化和数据增强。
3. **初始化模型参数:**随机初始化编码器和解码器网络的参数。
4. **迭代训练:**使用优化算法(例如 Adam)迭代地更新模型参数。在每次迭代中,模型都会执行以下步骤:
- 正向传播:将图像输入编码器,生成潜在表示,然后通过解码器解码为重建图像。
- 反向传播:计算重建图像与原始图像之间的损失。
- 更新参数:使用优化算法更新编码器和解码器网络的参数,以最小化损失。
#### 3.1.2 图像降维和特征提取
VAE还可以用于图像降维和特征提取。通过学习潜在表示,VAE可以捕捉图像中的关键特征。
**图像降维**
图像降维的目标是将高维图像投影到低维空间。VAE通过学习潜在表示来实现这一点。潜在表示的维度通常比原始图像的维度低得多。
**特征提取**
VAE提取的潜在表示包含图像的关键特征。这些特征可以用于各种任务,例如图像分类、目标检测和图像检索。
### 3.2 文本生成和语言建模
#### 3.2.1 文本生成模型的构建和训练
**构建文本生成模型**
文本生成模型的构建与图像生成模型类似,但使用不同的网络结构。
1. **定义编码器网络:**编码器网络将输入文本编码为潜在表示。它通常由循环神经网络 (RNN) 或变压器网络组成。
2. **定义解码器网络:**解码器网络将潜在表示解码为生成的文本。它通常也由 RNN 或变压器网络组成。
3. **定义损失函数:**损失函数衡量生成的文本与原始文本之间的差异。常用的损失函数包括交叉熵损失和序列到序列 (Seq2Seq) 损失。
**训练文本生成模型**
文本生成模型的训练过程与图像生成模型类似,但使用文本数据集。
#### 3.2.2 语言建模和文本分类
VAE还可以用于语言建模和文本分类。通过学习潜在表示,VAE可以捕捉文本中的语言模式和语义特征。
**语言建模**
语言建模的目标是预测给定文本序列的下一个单词。VAE通过学习潜在表示来实现这一点。潜在表示包含文本序列中的语言模式。
**文本分类**
文本分类的目标是将文本文档分类到预定义的类别中。VAE通过学习潜在表示来实现这一点。潜在表示包含文本文档的语义特征。
# 4. VAE的进阶探索
### 4.1 VAE的变体和扩展
#### 4.1.1 条件VAE和变分贝叶斯推理
条件VAE(CVAE)通过引入条件变量**c**来扩展标准VAE,使生成过程能够根据特定条件进行控制。条件变量可以是图像的类别、文本的主题或任何其他相关信息。
CVAE的模型结构与标准VAE类似,但解码器网络接受条件变量**c**作为附加输入。这允许解码器根据条件生成更特定的样本。
CVAE的训练过程也类似于标准VAE,但证据下界(ELBO)公式中增加了条件变量**c**。修改后的ELBO公式为:
```
ELBO = E_{q(z|x, c)}[log p(x|z, c)] - KL(q(z|x, c)||p(z))
```
#### 4.1.2 顺序VAE和时序建模
顺序VAE(SVAE)是VAE的扩展,适用于对时序数据进行建模。时序数据具有顺序依赖性,SVAE通过引入递归神经网络(RNN)来捕获这种依赖性。
SVAE的编码器网络是一个RNN,它逐个处理时序序列中的元素,并输出一个隐藏状态**h**。隐藏状态**h**包含了序列中到目前为止的信息。
SVAE的解码器网络也是一个RNN,它使用隐藏状态**h**和一个噪声向量**z**来生成时序序列的下一个元素。
SVAE的训练过程与标准VAE类似,但ELBO公式中修改为考虑时序依赖性。修改后的ELBO公式为:
```
ELBO = \sum_{t=1}^{T} E_{q(z|h_{t-1}, x_{t})}[log p(x_{t}|z, h_{t-1})] - KL(q(z|h_{t-1}, x_{t})||p(z))
```
### 4.2 VAE在特定领域的应用
#### 4.2.1 医学图像分析和疾病诊断
VAE在医学图像分析和疾病诊断领域得到了广泛应用。VAE可以学习从医学图像中提取有用的特征,这些特征可以用于疾病分类、诊断和治疗规划。
例如,在**肺癌检测**中,VAE可以从胸部X射线图像中提取特征,这些特征可以用于区分良性和恶性肺结节。
#### 4.2.2 自然语言处理和机器翻译
VAE也在自然语言处理和机器翻译领域找到了应用。VAE可以学习从文本数据中提取有用的特征,这些特征可以用于文本分类、语言建模和机器翻译。
例如,在**机器翻译**中,VAE可以从源语言文本中提取特征,这些特征可以用于生成目标语言文本。
# 5.1 VAE的发展趋势和研究热点
近年来,VAE的研究取得了长足的进步,并涌现出许多新的发展趋势和研究热点。
* **可解释性:**研究者们正在探索提高VAE可解释性的方法,以更好地理解模型的决策过程和生成结果。
* **生成式对抗网络(GAN)与VAE的融合:**GAN和VAE的结合,称为GAN-VAE,可以提高生成图像的质量和多样性。
* **条件VAE:**条件VAE可以生成基于特定条件(如图像类别或文本描述)的样本。
* **顺序VAE:**顺序VAE可以处理时序数据,用于时序建模和预测。
* **VAE在强化学习中的应用:**VAE可以作为强化学习中的状态表示,提高学习效率和决策质量。
## 5.2 VAE在实际应用中的挑战和机遇
尽管VAE在理论和实践中取得了显著进展,但其在实际应用中仍面临一些挑战和机遇:
* **计算成本:**VAE的训练和推理过程通常需要大量的计算资源,尤其是在处理大规模数据集时。
* **模式坍缩:**VAE有时会陷入模式坍缩,即生成样本的分布过于集中,缺乏多样性。
* **生成质量:**虽然VAE可以生成高质量的样本,但其生成结果仍存在一些缺陷,例如模糊、失真或不自然。
* **实际应用场景:**VAE在实际应用中仍需要探索更多的场景,例如医学图像分析、自然语言处理和机器翻译。
未来,VAE的研究和应用将继续蓬勃发展,随着计算能力的提升、算法的改进和实际场景的深入探索,VAE有望在更多领域发挥重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《变分自编码器(VAE)技术》专栏是一份全面的指南,深入探讨了变分自编码器(VAE)的原理、应用和实践。从基础概念到高级变体,该专栏涵盖了 VAE 的各个方面,包括图像生成、自然语言处理、医学影像、异常检测和强化学习。通过深入的数学解释、架构设计技巧和训练优化方法,读者将全面了解 VAE 的工作原理和如何有效地使用它们。此外,专栏还探讨了 VAE 在推荐系统、计算机视觉、金融、生物信息学、材料科学和社交网络分析等领域的最新进展和应用,为读者提供了对 VAE 在各个行业变革性影响的深入了解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
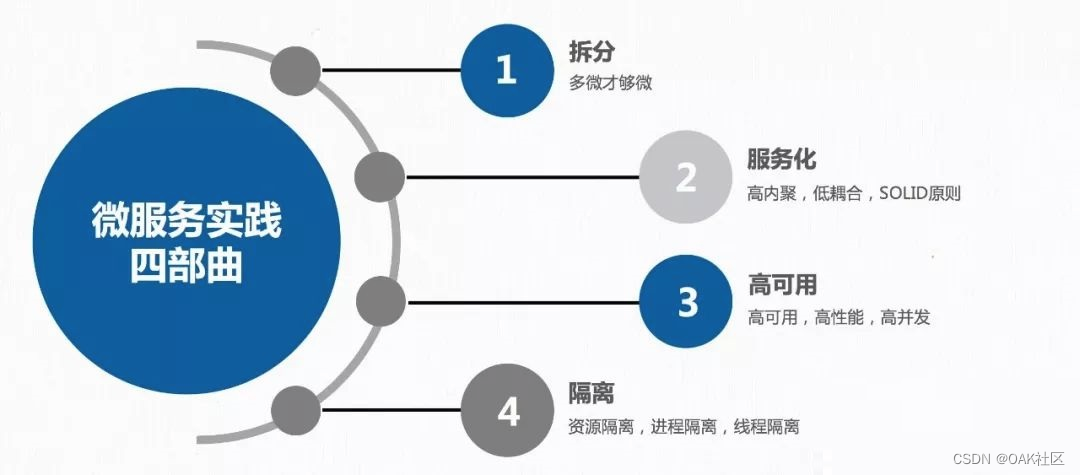
构建可扩展的微服务架构:系统架构设计从零开始的必备技巧
# 摘要
微服务架构作为一种现代化的分布式系统设计方法,已成为构建大规模软件应用的主流选择。本文首先概述了微服务架构的基本概念及其设计原则,随后探讨了微服务的典型设计模式和部署策略,包括服务发现、通信模式、熔断容错机制、容器化技术、CI/CD流程以及蓝绿部署等。在技术栈选择与实践方面,重点讨论了不同编程语言和框架下的微服务实现,以及关系型和NoSQL数据库在微服务环境中的应用。此外,本文还着重于微服务监控、日志记录和故障处理的最佳实践,并对微服
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
ICCAP调优初探:提效IC分析的六大技巧

# 摘要
ICCAP(Image Correlation for Camera Pose)是一种用于估计相机位姿和场景结构的先进算法,广泛应用于计算机视觉领域。本文首先概述了ICCAP的基础知识和分析挑战,深入探讨了ICCAP调优理论,包括其分析框架的工作原理、主要组件、性能瓶颈分析,以及有效的调优策略。随后,本文介绍了ICCAP调优实践中的代码优化、系统资源管理优化和数据处理与存储优化
LinkHome APP与iMaster NCE-FAN V100R022C10协同工作原理:深度解析与实践

# 摘要
本文首先介绍了LinkHome APP与iMaster NCE-FAN V100R022C10的基本概念及其核心功能和原理,强调了协同工作在云边协同架构中的作用,包括网络自动化与设备发现机制。接下来,本文通过实践案例探讨了LinkHome APP与iMaster NCE-FAN V100R022C1
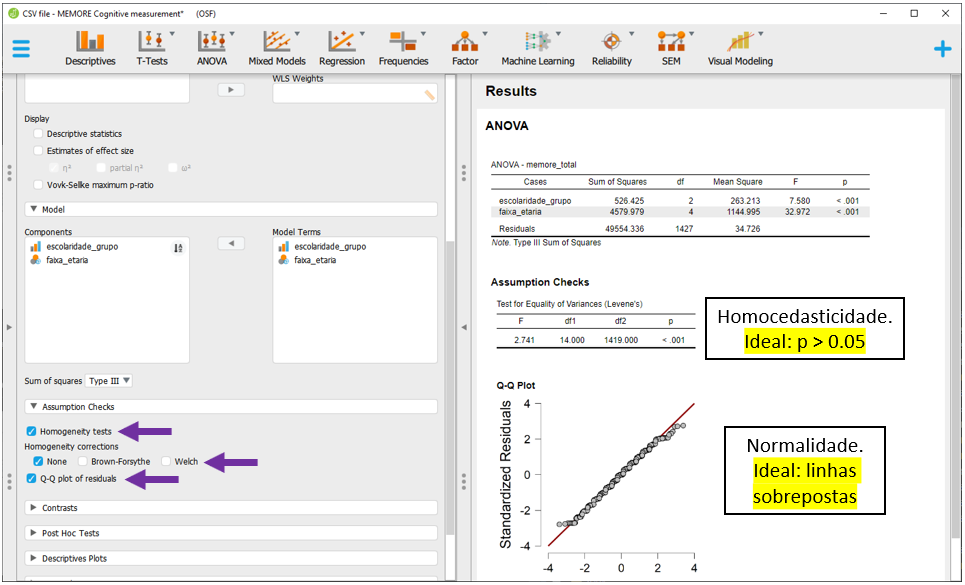
紧急掌握:单因子方差分析在Minitab中的高级应用及案例分析
# 摘要
本文详细介绍了单因子方差分析的理论基础、在Minitab软件中的操作流程以及实际案例应用。首先概述了单因子方差分析的概念和原理,并探讨了F检验及其统计假设。随后,文章转向Minitab界面的基础操作,包括数据导入、管理和描述性统计分析。第三章深入解释了方差分析表的解读,包括平方和的计算和平均值差异的多重比较。第四章和第五章分别讲述了如何在Minitab中执行单因子方
全球定位系统(GPS)精确原理与应用:专家级指南

# 摘要
本文对全球定位系统(GPS)的历史、技术原理、应用领域以及挑战和发展方向进行了全面综述。从GPS的历史和技术概述开始,详细探讨了其工作原理,包括卫星信号构成、定位的数学模型、信号增强技术等。文章进一步分析了GPS在航海导航、航空运输、军事应用以及民用技术等不同领域的具体应用,并讨论了当前面临的信号干扰、安全问题及新技术融合的挑战。最后,文
AutoCAD VBA交互设计秘籍:5个技巧打造极致用户体验
# 摘要
本论文系统介绍了AutoCAD VBA交互设计的入门知识、界面定制技巧、自动化操作以及高级实践案例,旨在帮助设计者和开发者提升工作效率与交互体验。文章从基本的VBA用户界面设置出发,深入探讨了表单和控件的应用,强调了优化用户交互体验的重要性。随后,文章转向自动化操作,阐述了对象模型的理解和自动化脚本的编写。第三部分展示了如何应用ActiveX Automation进行高级交互设计,以及如何定制更复杂的用户界面元素,以及解决方案设计过程中的用户反馈收集和应用。最后一章重点介绍了VBA在AutoCAD中的性能优化、调试方法和交互设计的维护更新策略。通过这些内容,论文提供了全面的指南,以应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )