变分自编码器(VAE)与生成对抗网络(GAN):深度对比与协同应用,揭秘生成式模型的协同力量
发布时间: 2024-08-20 16:23:24 阅读量: 45 订阅数: 33 

人工智能-项目实践-生成对抗网络-在 PyTorch 和 Tensorflow 中实现的多生成对抗网络 (GAN)

# 1. 生成式模型概述
生成式模型是一种机器学习模型,它能够从数据中学习并生成新的数据。它们通常用于生成图像、文本或其他类型的媒体。生成式模型可以分为两大类:变分自编码器(VAE)和生成对抗网络(GAN)。
VAE 是一种生成式模型,它使用贝叶斯推断来学习数据的分布。它通过学习数据中潜在的特征来生成新的数据。GAN 是一种生成式模型,它使用博弈论来学习数据的分布。它通过训练一个生成器网络和一个判别器网络来生成新的数据。
# 2. 变分自编码器(VAE)
### 2.1 VAE的理论基础
#### 2.1.1 贝叶斯推断与变分推断
**贝叶斯推断**是一种统计推断方法,它通过已知的先验分布和似然函数来计算后验分布。在贝叶斯推断中,我们假设模型参数服从先验分布,并根据观测数据更新先验分布得到后验分布。
**变分推断**是一种近似贝叶斯推断的方法。在变分推断中,我们引入一个近似后验分布,并最小化近似后验分布和真实后验分布之间的差异。通过最小化差异,我们可以得到一个接近真实后验分布的近似后验分布。
#### 2.1.2 VAE的生成过程
VAE是一个生成模型,它通过学习数据分布来生成新的数据。VAE的生成过程如下:
1. **编码:**将输入数据编码为一个潜在变量z。潜在变量z通常是一个低维向量,它包含了输入数据的重要特征。
2. **采样:**从潜在变量z的分布中采样一个样本z。
3. **解码:**将采样得到的样本z解码为一个生成数据x。
### 2.2 VAE的实践应用
#### 2.2.1 图像生成
VAE可以用于生成图像。下图展示了VAE生成的一组人脸图像。
[图片:VAE生成的人脸图像]
**代码块:**
```python
import tensorflow as tf
# 定义编码器
encoder = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu')
])
# 定义解码器
decoder = tf.keras.Sequential([
tf.keras.layers.Dense(7 * 7 * 2),
tf.keras.layers.Reshape((7, 7, 2)),
tf.keras.layers.Conv2DTranspose(64, (3, 3), activation='relu'),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2DTranspose(32, (3, 3), activation='relu'),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2D(1, (3, 3), activation='sigmoid')
])
# 定义VAE模型
vae = tf.keras.Model(encoder.input, decoder.output)
# 训练VAE模型
vae.compile(optimizer='adam', loss='mse')
vae.fit(x_train, y_train, epochs=10)
# 生成图像
generated_images = vae.predict(x_test)
```
**代码逻辑分析:**
* 编码器使用卷积神经网

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《变分自编码器(VAE)技术》专栏是一份全面的指南,深入探讨了变分自编码器(VAE)的原理、应用和实践。从基础概念到高级变体,该专栏涵盖了 VAE 的各个方面,包括图像生成、自然语言处理、医学影像、异常检测和强化学习。通过深入的数学解释、架构设计技巧和训练优化方法,读者将全面了解 VAE 的工作原理和如何有效地使用它们。此外,专栏还探讨了 VAE 在推荐系统、计算机视觉、金融、生物信息学、材料科学和社交网络分析等领域的最新进展和应用,为读者提供了对 VAE 在各个行业变革性影响的深入了解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析深度解析】:15个关键技巧让你成为数据预测大师

# 摘要
时间序列分析是处理和预测按时间顺序排列的数据点的技术。本文
【Word文档处理技巧】:代码高亮与行号排版的终极完美结合指南
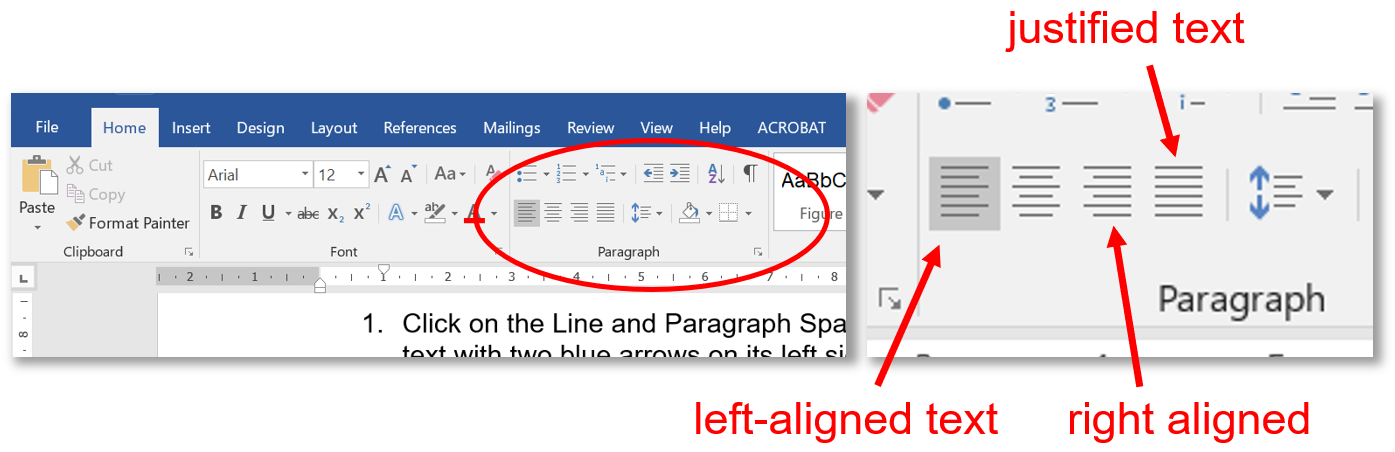
# 摘要
本文旨在为技术人员提供关于Word文档处理的深入指导,涵盖了从基础技巧到高级应用的一系列主题。首先介绍了Word文档处理的基本入门知识,然后着重讲解了代码高亮的实现方法,包括使用内置功能、自定义样式及第三方插件和宏。接着,文中详细探讨了行号排版的策略,涉及基础理解、在Word中的插入方法以及高级定制技巧。第四章讲述了如何将代码高亮与行号完美结
LabVIEW性能优化大师:图片按钮内存管理的黄金法则
# 摘要
本文围绕LabVIEW软件平台的内存管理进行深入探讨,特别关注图片按钮对象在内存中的使用原理、优化实践以及管理工具的使用。首先介绍LabVIEW内存管理的基础知识,然后详细分析图片按钮在LabVIEW中的内存使用原理,包括其数据结构、内存分配与释放机制、以及内存泄漏的诊断与预防。第三章着重于实践中的内存优化策略,包括图片按钮对象的复用、图片按钮数组与簇的内存管理技巧,以及在事件结构和循环结构中的内存控制。接着,本文讨论了LabVIEW内存分析工具的使用方法和性能测试的实施,最后提出了内存管理的最佳实践和未来发展趋势。通过本文的分析与讨论,开发者可以更好地理解LabVIEW内存管理,并
【CListCtrl行高设置深度解析】:算法调整与响应式设计的完美融合
# 摘要
CListCtrl是广泛使用的MFC组件,用于在应用程序中创建具有复杂数据的列表视图。本文首先概述了CListCtrl组件的基本使用方法,随后深入探讨了行高设置的理论基础,包括算法原理、性能影响和响应式设计等方面。接着,文章介绍了行高设置的实践技巧,包括编程实现自适应调整、性能优化以及实际应用案例分析。文章还探讨了行高设置的高级主题,如视觉辅助、动态效果实现和创新应用。最后,通过分享最佳实践与案例,本文为构建高效和响应式的列表界面提供了实用的指导和建议。本文为开发者提供了全面的CListCtrl行高设置知识,旨在提高界面的可用性和用户体验。
# 关键字
CListCtrl;行高设置
邮件排序与筛选秘籍:SMAIL背后逻辑大公开
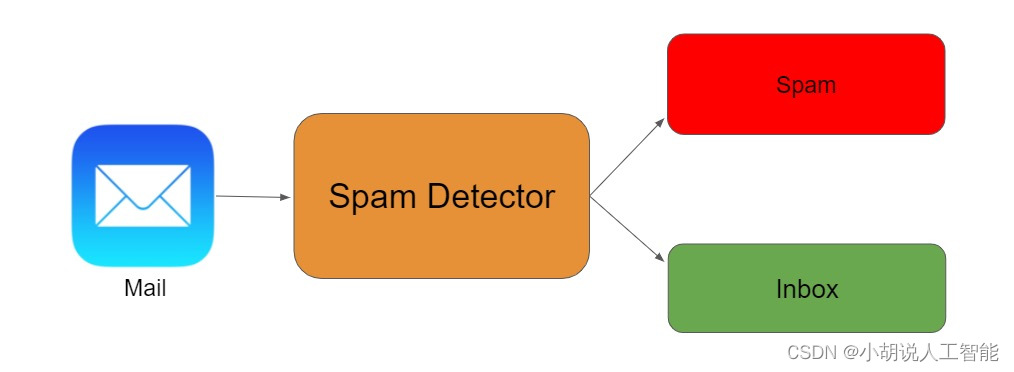
# 摘要
本文全面探讨了邮件系统的功能挑战和排序筛选技术。首先介绍了邮件系统的功能与面临的挑战,重点分析了SMAIL的排序算法,包括基本原理、核心机制和性能优化策略。随后,转向邮件筛选技术的深入讨论,包括筛选逻辑的基础构建、高级技巧和效率提升方法。文中还通过实际案例分析,展示了邮件排序与筛选在不同环境中的应用,以及个人和企业级的邮件管理策略。文章最后展望了SMAIL的未来发展趋势,包括新技术的融入和应对挑战的策
AXI-APB桥在SoC设计中的关键角色:微架构视角分析

# 摘要
本文对AXI-APB桥的技术背景、设计原则、微架构设计以及在SoC设计中的应用进行了全面的分析与探讨。首先介绍了AXI与APB协议的对比以及桥接技术的必要性和优势,随后详细解析了AXI-APB桥的微架构组件及其功能,并探讨了设计过程中面临的挑战和解决方案。在实践应用方面,本文阐述了AXI-APB桥在SoC集成、性能优化及复杂系统中的具体应用实例。此外,本文还展望了AXI-APB桥的高级功能扩展及其
CAPL脚本高级解读:技巧、最佳实践及案例应用
# 摘要
CAPL(CAN Access Programming Language)是一种专用于Vector CAN网络接口设备的编程语言,广泛应用于汽车电子、工业控制和测试领域。本文首先介绍了CAPL脚本的基础知识,然后详细探讨了其高级特性,包括数据类型、变量管理、脚本结构、错误处理和调试技巧。在实践应用方面,本文深入分析了如何通过CAPL脚本进行消息处理、状态机设计以
【适航审定的六大价值】:揭秘软件安全与可靠性对IT的深远影响
# 摘要
适航审定作为确保软件和IT系统符合特定安全和可靠性标准的过程,在IT行业中扮演着至关重要的角色。本文首先概述了适航审定的六大价值,随后深入探讨了软件安全性与可靠性的理论基础及其实践策略,通过案例分析,揭示了软件安全性与可靠性提升的成功要素和失败的教训。接着,本文分析了适航审定对软件开发和IT项目管理的影响,以及在遵循IT行业标准方面的作用。最后,展望了适航审定在
CCU6定时器功能详解:定时与计数操作的精确控制

# 摘要
CCU6定时器是工业自动化和嵌入式系统中常见的定时器组件,本文系统地介绍了CCU6定时器的基础理论、编程实践以及在实际项目中的应用。首先概述了CCU
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )