【Python树结构扩展】:多叉树在JSON数据转换中的巧妙应用
发布时间: 2024-09-12 05:57:52 阅读量: 144 订阅数: 42 

树状数据(多叉树)在数据库中存储的示例源码
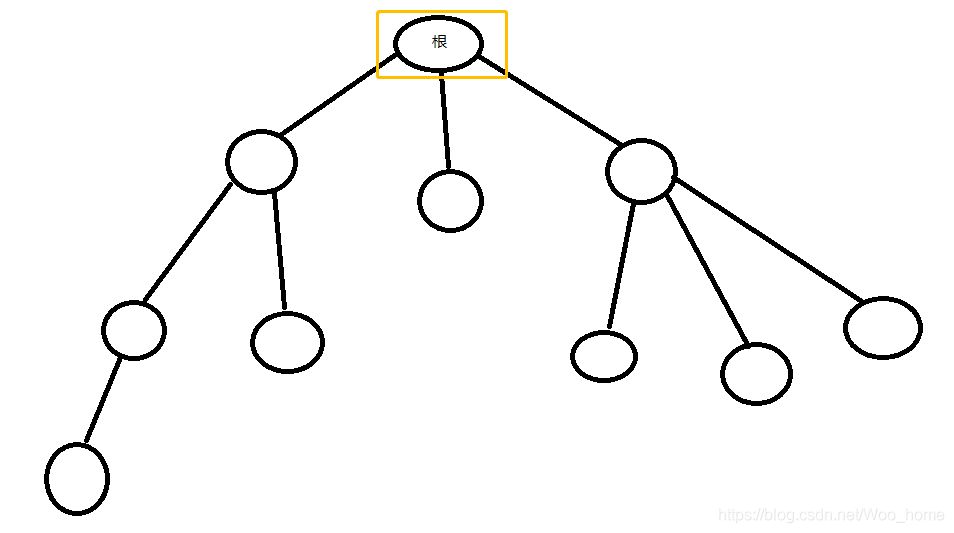
# 1. 多叉树数据结构概述
多叉树是一种非线性数据结构,与二叉树类似,但是每个节点可以有无限数量的子节点。它被广泛应用于计算机科学中,用于表示具有层次结构的数据。多叉树的每个节点通常包含一些数据和指向其子节点的指针。这种结构非常适合表示具有多对多关系的数据,如文件系统的目录结构,以及用于解析和生成JSON数据。
多叉树在操作和查询方面提供了灵活性,允许更高效的插入和删除操作,以及更复杂的数据遍历算法。在本章中,我们将初步介绍多叉树的基本概念和重要性,并为后续章节中深入探讨其理论和应用打下基础。
# 2. 多叉树的基本理论和操作
### 2.1 多叉树的定义和特性
#### 2.1.1 多叉树的定义
多叉树(M-ary Tree)是树结构的一种扩展,与二叉树类似,但它每个节点的子节点数量不限于两个。在多叉树中,一个父节点可以有零个或多个子节点。当多叉树中的所有节点最多只有m个子节点时,这样的树被称为m叉树。多叉树广泛应用于计算机科学中,尤其是人工智能领域,如决策树、XML文档结构等。
在多叉树的定义中,我们需要考虑以下几点:
- **节点(Node)**:树中的每一个数据单元。
- **边(Edge)**:连接父节点和子节点的线段。
- **根节点(Root)**:多叉树中的最顶层节点,不存在父节点。
- **叶子节点(Leaf)**:没有子节点的节点。
- **子树(Subtree)**:任何节点及其后代构成的树。
- **深度(Depth)**:从根节点到某一节点的路径长度。
- **高度(Height)**:从某一节点到其最远叶子节点的路径长度。
#### 2.1.2 多叉树的特性与分类
多叉树的特性包括:
- **非线性结构**:多叉树不是线性结构,因为它允许节点有更多的连接。
- **层次性**:节点之间具有明确的层次关系,每一层的节点是同级的。
- **分支性**:每个节点都可能有多个子节点,形成分支结构。
- **递归性质**:多叉树可以通过递归方式定义和处理。
根据结构的不同,多叉树可以分为以下几种类型:
- **完全多叉树(Complete M-ary Tree)**:除最后一层外,每一层都被完全填满,且最后一层的所有节点都尽可能地靠左。
- **完美多叉树(Perfect M-ary Tree)**:所有叶子节点都在同一层级上,每个非叶子节点都有m个子节点。
- **平衡多叉树(Balanced M-ary Tree)**:任何两个叶子节点之间的高度差不超过1。
- **非平衡多叉树(Unbalanced M-ary Tree)**:树的任何两个叶子节点之间的高度差大于1。
### 2.2 多叉树的基本操作
#### 2.2.1 节点的添加与删除
在多叉树中,节点的添加和删除是基本操作,但与二叉树相比,操作更为复杂,需要考虑子节点的数目和树的平衡问题。
**节点的添加**:
1. 确定添加位置,通常是叶子节点的子节点位置。
2. 创建新节点,并将其作为目标父节点的子节点。
3. 根据需要调整树的结构,如进行树的平衡处理。
```python
class MTreeNode:
def __init__(self, value):
self.value = value
self.children = []
def add_child(self, child_node):
self.children.append(child_node)
# 示例:向多叉树添加节点
root = MTreeNode('root') # 创建根节点
child = MTreeNode('child') # 创建子节点
root.add_child(child) # 将子节点添加到根节点
```
**节点的删除**:
1. 查找要删除的节点。
2. 如果删除的是非叶子节点,需要确定如何处理其子节点(如删除子节点或重新分配)。
3. 删除节点,并保持树的其他属性不变。
```python
def remove_node(node_to_remove):
parent = find_parent(node_to_remove)
if parent is not None:
parent.children.remove(node_to_remove)
# 如果删除的是根节点,需要特别处理
if node_to_remove is root:
root = None
# 注意:这个示例中的find_parent函数需要自己实现,用于查找父节点。
```
#### 2.2.2 树的遍历算法
多叉树的遍历算法可以分为三类:前序遍历、中序遍历、后序遍历。这些遍历方式与二叉树类似,但适用于多个子节点的情况。
**前序遍历**:先访问根节点,然后访问所有子节点。
```python
def preorder_traversal(node):
if node is None:
return
# 访问根节点
print(node.value)
# 前序遍历子节点
for child in node.children:
preorder_traversal(child)
```
**中序遍历**:先访问子节点,然后访问根节点。
```python
def inorder_traversal(node):
if node is None:
return
# 中序遍历子节点
for child in node.children:
inorder_traversal(child)
# 访问根节点
print(node.value)
```
**后序遍历**:先访问所有子节点,最后访问根节点。
```python
def postorder_traversal(node):
if node is None:
return
# 后序遍历子节点
for child in node.children:
postorder_traversal(child)
# 访问根节点
print(node.value)
```
#### 2.2.3 树的平衡与优化
多叉树的平衡与优化是维持树性能的关键。对于多叉树,我们通常关注的是树的高度平衡,以保证操作的时间复杂度不会因为树的倾斜而变得过高。
**平衡树的概念**:
平衡树指的是一棵树,其中任何两个叶子节点之间的高度差都不超过一个给定的常数。在二叉树中,这个概念与AVL树和红黑树紧密相关。对于多叉树,概念可以类推。
**平衡多叉树的实现**:
实现平衡多叉树通常需要自定义一个平衡操作,比如在节点添加或删除后进行平衡检查,并执行旋转等操作以维持树的平衡。
```python
def balance_tree(node):
# 这里需要实现树平衡的逻辑,包括检查树是否不平衡
# 以及执行旋转等平衡操作。
pass
```
平衡操作通常涉及到树的旋转,需要在添加或删除节点后调整子树的位置。对于多叉树,旋转操作较为复杂,需要考虑多个子节点的情况。
通过上述基本理论和操作的讨论,我们已经构建了对多叉树的初步认识,接下来的章节,我们将深入探讨多叉树与JSON数据结构的转换实践,以及多叉树在数据处理中的高级应用。
# 3. JSON数据格式解析
在现代网络应用中,数据传输是不可或缺的一部分。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。尽管它源于JavaScript,但JSON是一种独立于语言的数据格式。本章节将详细介绍JSON数据格式,包括其基本的数据类型、组织方式,以及在Python中的处理方法。
## 3.1 JSON数据结构简介
### 3.1.1 JSON数据类型
JSON数据类型主要包括基本数据类型和复合数据类型。基本数据类型包括字符串(string)、数值(number)、布尔值(true或false)、null。复合数据类型则包括对象(object)和数组(array)。对象由一系列的“键值对”组成,格式为`{"key": "value"}`;数组则是值的有序列表,格式为`["value1", "value2", ...]`。
### 3.1.2 JSON数据的组织方式
在JSON中,数据的组织方式非常灵活,可以嵌套使用各种类型。例如,对象可以包含多个键值对,每个键值对的值可以是基本数据类型、数组、甚至另一个对象。这种嵌套的数据结构可以构建复杂的数据关系模型。
```json
{
"name": "John Doe",
"age": 30,
"isEmployed": true,
"address": {
"street": "123 Main St",
"city": "Anytown",
"zipcode": "12345"
},
"phoneNumbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "office",
"number": "646 555-4567"
}
]
}
```
在上述JSON示例中,`address`是一个对象,而`phoneNumbers`是一个数组,数组中的每个元素都是一个包含`type`和`number`的对象。
## 3.2 JSON与Python的数据交换
JSON和Python之间的数据交换是通过Python标准库中的`json`模块实现的。Python中处理JSON数据的主要方法包括将Python数据结构转换为JSON格式,以及从JSON格式解析数据到Python对象。
### 3.2.1 Python中的JSON库
Python的`json`模块提供了编码(序列化)和解码(反序列化)JSON数据的功能。它可以处理Python中的基本数据类型和复合数据类型,包括列表、字典、元组、整数、浮点数、字符串等。
### 3.2.2 将Python数据结构转换为JSON
要将Python数据结构转换为JSON,可以使用`json.dumps()`方法。该方法接受一个Python对象并返回一个JSON格式的字符串。
```python
import json
python_data = {
"name": "John Doe",
"age": 30,
"isEmployed": True,
"addre
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中树形数据结构的各个方面,从基础知识到高级技巧。专栏包含多个子主题,涵盖了树形数据结构的创建、遍历、搜索、序列化、反序列化、内存管理和可视化。它还提供了有关递归、列表推导式和生成器在树形数据结构处理中的应用的深入见解。此外,专栏还提供了将树形数据结构与 JSON 数据格式交互的实用指南,包括编码、解码和数据转换。通过本专栏,初学者和经验丰富的 Python 开发人员都可以全面了解树形数据结构,并掌握在各种应用程序中有效使用它们的技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )