数据清洗实例:使用R语言处理缺失值与异常值
发布时间: 2024-04-07 18:22:02 阅读量: 172 订阅数: 29 
# 1. 介绍数据清洗的重要性
数据在现代社会中扮演着至关重要的角色,它们被广泛应用于商业决策、科学研究、政府政策制定等各个领域。然而,原始数据往往并不完美,可能存在各种问题,如缺失值、异常值等,这就需要进行数据清洗来提高数据质量和准确性。
### 1.1 数据清洗在数据分析中的作用
数据清洗是数据分析过程中不可或缺的一环。通过数据清洗,我们可以去除数据中的噪声和错误,使数据更加准确、一致,从而确保后续分析的结果可靠有效。数据清洗能够帮助我们发现数据集中的问题,进而更好地利用数据进行洞察和决策。
### 1.2 数据清洗对模型准确性的影响
在机器学习和数据建模中,数据质量直接影响模型的准确性和泛化能力。如果数据中存在缺失值或异常值,模型可能会受到干扰而产生偏差。因此,通过数据清洗处理这些问题,可以提高模型的准确性,使其更好地反映数据的真实情况,从而提升模型的预测能力和可解释性。
# 2. 数据清洗基础知识
数据清洗是数据分析过程中至关重要的一步,它涉及清除数据中的错误、不完整、重复或不必要的部分,以确保数据质量高,为后续分析建模提供可靠的基础。在本章中,我们将介绍数据清洗的基础知识,包括数据清洗的定义与流程、常见的数据质量问题以及数据清洗的方法和工具。
#### 2.1 数据清洗的定义与流程
数据清洗是指对数据进行识别、纠正或删除错误、不完整或不准确的部分,以保证数据质量的过程。数据清洗的主要步骤包括数据审查、数据纠正、数据标准化和数据完整化等。
#### 2.2 常见的数据质量问题
在实际数据分析过程中,经常会遇到数据质量问题,例如:缺失值、重复数据、异常值、不一致数据格式等。这些问题会影响数据分析的结果准确性,因此在数据清洗过程中需要认真处理这些问题。
#### 2.3 数据清洗的方法和工具
数据清洗可以通过一系列方法和工具来实现,常用的技术包括数据填充、数据转换、数据过滤、数据去重等。在实际操作中,可以使用各种数据处理工具如Python中的pandas库、R语言中的tidyverse包以及SQL等进行数据清洗操作。
通过本章的介绍,读者可以了解数据清洗的基础知识,为后续的数据清洗实践打下基础。在接下来的章节中,我们将进一步探讨数据清洗中的具体问题和解决方法。
# 3. 缺失值处理
在数据清洗过程中,处理缺失值是至关重要的一步。缺失值可能会对数据分析和建模产生不良影响,因此我们需要采取合适的方法来处理这些缺失值。本章将介绍缺失值的定义和影响,以及在数据清洗中识别和填充缺失值的方法。
- **3.1 缺失值的定义和影响**
缺失值是指数据集中某些字段或观测值缺少数值或信息的情况。缺失值可能会导致数据分析结果不准确,影响模型的准确性和可靠性。因此,及时有效地处理缺失值对保障数据质量至关重要。
- **3.2 缺失值的识别与填充方法**
识别缺失值的常用方法包括统计描述、可视化观察和特定领域知识。而填充缺失值的方法则包括均值、中位数、众数填充、插值法等多种方式,在具体应用中需要根据数据特点和业务需求来选择合适的填充方式。
- **3.3 在R语言中使用工具处理缺失值的示例**
在R语言中,我们可以使用相关包如`dplyr`和`tidyverse`来处理缺失值。以下是一个简单示例:
```r
# 导入相关包
library(dplyr)
library(tidyr)
# 创建包含缺失值的数据框
data <- data.frame(
A = c(1, 2, NA, 4, 5),
B = c("a", "b", "c", NA, "e")
)
# 查看缺失值
is.na(data)
# 使用均值填充缺失值
data_filled <- data %>%
mutate(A = ifelse(is.na(A), mean(A, na.rm = TRUE), A),
B = ifelse(is.na(B), "unknown", B))
# 输出处理后的数据
print(data_filled)
```
通过使用R语言中的相关包,我们可以方便地识别和填充数据中的缺失值,提高数据质量和分析结果的准确性。
# 4. 异常值检测与处理
在数据清洗的过程中,异常值是一个常见的问题,它可能会对数据分析和建模产生不良影响。因此,在处理数据时,我们需要引入异常值检测与处理的步骤,以保证数据的质量和准确性。
#### 4.1 异常值的定义和种类
异常值(Outlier)是指在数据集中与其他观测值明显不同的数据点。异常值可以分为三种类型:
- **点异常值(Point Anomalies)**:单个数据点是异常的,比如输入错误、测量误差等。
- **上下文异常值(Contextual Anomalies)**:在特定上下文条件下是异常的,但在其他情况下可能是正常的。
- **集体异常值(Collective Anomalies)**:组合观测值一起形成异常,如时间序列数据中的突发事件。
#### 4.2 异常值检测方法介绍
常用的异常值检测方法包括:
- **基于统计的方法**:如Z分数、箱线图等,通过数学统计分析识别异常值。
- **基于距离的方法**:如K近邻算法、孤立森林等,通过数据点之间的距离来判断异常值。
- **基于密度的方法**:如LOF(局部异常因子)算法,通过评估数据点周围密度来检测异常值。
- **基于聚类的方法**:如DBSCAN算法,通过聚类分析来识别异常值。
#### 4.3 在R语言中使用技术检测和处理异常值的示例
以下是一个使用R语言实现异常值检测的示例代码:
```R
# 导入异常值检测库
library(dplyr)
library(outliers)
# 创建一个包含异常值的数据集
data <- c(10, 15, 12, 14, 18, 5, 100)
# 使用Z分数方法检测异常值
outliers <- boxplot(data, plot = FALSE)$out
cat("异常值:", outliers, "\n")
# 将异常值替换为NA
data_clean <- data %>% replace(., . %in% outliers, NA)
cat("处理后的数据集:", data_clean, "\n")
```
在上述代码中,我们使用了Z分数方法检测异常值,并将异常值替换为NA进行处理。这样就可以通过异常值检测方法对数据进行清洗和预处理。
# 5. 实践案例:数据清洗与处理
在这一章中,我们将通过一个实际的数据集来演示数据清洗与处理的过程。首先我们将介绍数据集的背景,然后展示如何处理其中的缺失值和异常值。
#### 5.1 数据集介绍
我们选取了一个包含学生信息的数据集,其中包括学生的姓名、年龄、成绩等信息。这个数据集是一个CSV文件,我们将使用Python语言来进行数据清洗和处理。
#### 5.2 缺失值处理实例
首先,我们需要加载数据集并查看其中是否存在缺失值。
```python
import pandas as pd
# 读取数据集
data = pd.read_csv('student_info.csv')
# 查看缺失值情况
missing_values = data.isnull().sum()
print("缺失值数量:")
print(missing_values)
```
通过上述代码我们可以查看到数据集中存在的缺失值数量,接下来我们将介绍如何填充这些缺失值。
```python
# 填充缺失值
mean_age = data['age'].mean()
data['age'].fillna(mean_age, inplace=True)
median_score = data['score'].median()
data['score'].fillna(median_score, inplace=True)
# 检查填充结果
print("缺失值填充后:")
print(data.isnull().sum())
```
通过上述代码,我们使用均值填充了年龄列的缺失值,使用中位数填充了成绩列的缺失值,并输出了填充后的结果。
#### 5.3 异常值检测与处理实例
接下来,我们将展示如何检测并处理数据集中的异常值。
```python
# 异常值检测
Q1 = data['score'].quantile(0.25)
Q3 = data['score'].quantile(0.75)
IQR = Q3 - Q1
upper_bound = Q3 + 1.5 * IQR
lower_bound = Q1 - 1.5 * IQR
outliers = data[(data['score'] < lower_bound) | (data['score'] > upper_bound)]
print("异常值数量:")
print(len(outliers))
# 处理异常值
data = data[(data['score'] >= lower_bound) & (data['score'] <= upper_bound)]
print("处理异常值后数据集大小:")
print(data.shape)
```
上述代码中,我们使用了IQR方法来检测异常值,并进行了处理,最后输出了处理异常值后的数据集大小。
通过本章的实践案例,我们展示了如何处理实际数据中的缺失值和异常值,为数据清洗工作提供了具体的操作步骤和方法。
# 6. 总结与展望
数据清洗在数据分析中扮演着至关重要的角色。通过本文的介绍,我们了解到数据清洗不仅可以帮助我们解决数据质量问题,提高模型准确性,还可以有效优化数据分析的流程,确保数据分析的结果更加准确可靠。在实际应用中,数据清洗需要综合考虑缺失值处理和异常值检测两个重要环节,以确保数据的完整性和准确性。
在未来,随着大数据技术的快速发展,数据清洗领域也将持续关注和发展。我们可以期待机器学习和人工智能算法在数据清洗中的应用,以及更智能化、自动化的数据清洗工具的出现。同时,随着数据量的增加和数据来源的多样化,数据清洗的挑战也将不断增加,需要我们不断学习和更新技术,以应对日益复杂的数据清洗需求。
综上所述,数据清洗作为数据分析中不可或缺的重要环节,将继续发挥着重要作用,促进数据驱动决策的发展。让我们继续关注数据清洗领域的最新动态,不断提升自身技能,为数据分析的未来发展贡献自己的力量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 R 语言为基础,提供了一系列数据分析案例。从入门到高级主题,涵盖数据导入、清洗、统计分析、可视化、数据挖掘、机器学习和自然语言处理等方面。专栏中的文章详细介绍了 R 语言的安装、基本数据结构、缺失值处理、描述性统计、图表绘制、关联规则挖掘、线性回归、逻辑回归、聚类分析、时间序列分析、因子分析、决策树、支持向量机、主成分分析、贝叶斯网络、集成学习、神经网络和文本挖掘等技术。通过这些案例,读者可以深入了解 R 语言在数据分析中的强大功能和应用场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
高级概率分布分析:偏态分布与峰度的实战应用

# 1. 概率分布基础知识回顾
概率分布是统计学中的核心概念之一,它描述了一个随机变量在各种可能取值下的概率。本章将带你回顾概率分布的基础知识,为理解后续章节的偏态分布和峰度概念打下坚实的基础。
## 1.1 随机变量与概率分布
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
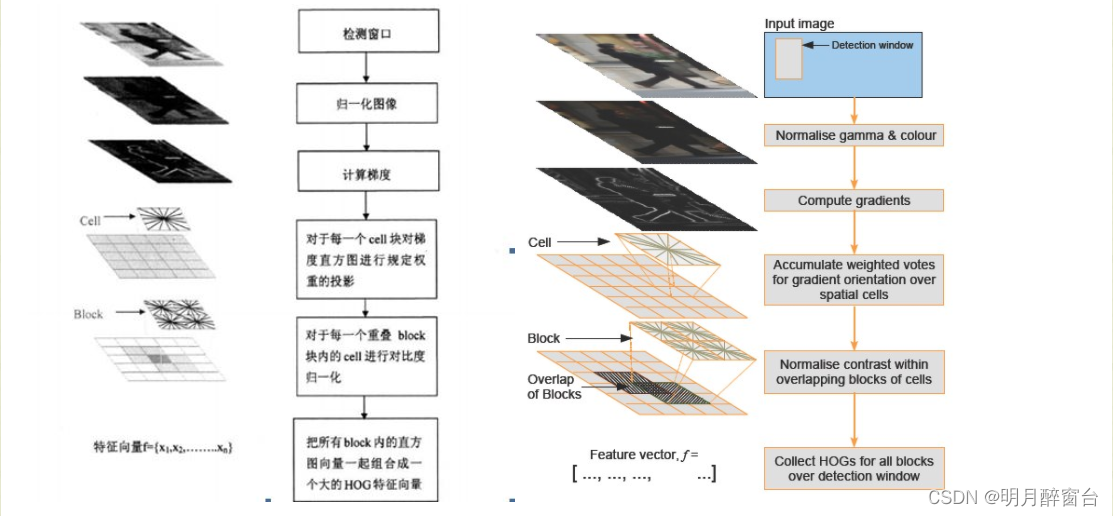
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )