【交叉验证的艺术】:超参数调优实验设计精讲
发布时间: 2024-09-05 16:22:47 阅读量: 75 订阅数: 36 

软考架构精讲:数据库设计与关键技术详解

# 1. 交叉验证在超参数调优中的重要性
## 1.1 超参数调优的必要性
在机器学习模型训练过程中,超参数是决定学习过程和模型性能的关键因素。超参数包括学习率、批次大小、正则化参数等,它们在学习算法运行前设定,不通过训练数据直接学习。正确地调整这些超参数对于防止模型过拟合或欠拟合至关重要。
## 1.2 交叉验证的作用
交叉验证是一种统计方法,用于评估并提升机器学习模型对未知数据的泛化能力。它通过将数据集分割成几个小组,并用其中一部分进行模型训练,另一部分进行验证,以此来减少模型评估的方差,确保模型在不同子集上的一致性和可靠性。
## 1.3 为什么选择交叉验证
交叉验证通过多轮的训练和验证过程,有效提升了超参数调优的准确性。相比单一的训练集-验证集划分,交叉验证能够更好地利用有限的数据,提高模型的稳健性。因此,在面对不同的机器学习任务时,交叉验证已成为超参数调优不可或缺的一环。
# 2. 理论基础与交叉验证方法
### 2.1 机器学习与超参数概述
#### 2.1.1 超参数定义及其与模型训练的关系
在机器学习中,超参数是指那些在训练算法之前设定的参数,而不是通过学习过程得到的参数。它们决定了模型的结构和学习过程的细节,如学习率、批次大小、网络层数等。这些参数通常不能直接从数据中学习得到,而是根据经验和验证结果进行调整。超参数的选择对于模型的性能有极大的影响,它们能够决定学习算法的学习速度、收敛性,以及是否能够找到问题的全局最优解。
模型训练时,超参数是影响模型复杂度的重要因素。比如,在决策树模型中,树的深度就是一个超参数。如果深度设置太浅,模型可能无法捕捉数据中的复杂关系;如果深度太深,模型可能会过拟合,学习到训练数据中的噪声而非潜在的分布规律。
#### 2.1.2 超参数对模型性能的影响
超参数的设定直接关系到模型的泛化能力。泛化能力是指模型对未知数据的预测能力。如果超参数设置得当,模型将拥有较好的泛化能力;反之,如果超参数选择不当,可能会导致模型泛化能力差,甚至无法学习到有效的特征表示。
例如,在神经网络中,学习率是最重要的超参数之一。如果学习率设置得太低,训练过程会非常缓慢,且容易陷入局部最小值;如果设置得太高,则可能导致训练无法收敛。此外,正则化参数(如L1/L2惩罚项系数)也对模型的泛化能力有显著影响。合适的正则化可以帮助模型避免过拟合,但过高的正则化会导致欠拟合。
### 2.2 交叉验证的理论依据
#### 2.2.1 泛化能力的概念
泛化能力是指模型在新、未见过的数据上预测的能力。在统计学习理论中,泛化能力是衡量模型质量的关键指标。好的机器学习模型不仅能在训练集上获得低误差,更重要的是能在验证集和测试集上也能有较好的表现。泛化能力的核心概念是模型复杂度与数据量之间的平衡,这是交叉验证方法的理论基础。
交叉验证作为一种统计方法,通过将原始数据分成多个小组(称为“折”),从而用这些小组作为验证集和训练集,循环地进行训练与评估,最终得到模型性能的稳定估计。这种方法旨在减小模型评价的方差,提供对泛化误差的更加可靠的估计。
#### 2.2.2 验证集和测试集的作用
在机器学习模型的训练过程中,验证集和测试集起着关键的作用。验证集主要用于模型调优,即选择模型的超参数和结构。模型在训练集上进行学习,在验证集上进行评估和选择,以此来防止过拟合和提高泛化能力。
测试集则是用来最终评价模型性能的,它应该在模型的所有调优和选择过程之后使用一次。测试集不应被用来调整模型,以避免由于测试结果反馈到模型训练中而带来的数据泄露问题。通过独立的测试集,我们可以获得一个相对客观的性能指标,对模型的泛化能力作出评估。
### 2.3 常见交叉验证技术
#### 2.3.1 留一交叉验证(LOOCV)
留一交叉验证(Leave-One-Out Cross Validation,LOOCV)是一种特殊的K折交叉验证,其中K等于样本总数。对于每次迭代,模型在一个单独的数据点上进行验证,而剩余的所有数据点都用于训练。这种技术的优点是能够最大限度地利用有限的数据集,得到更可靠的性能估计。然而,其缺点也非常明显,计算成本很高,特别是对于大数据集,因为需要训练模型N次(N为样本总数)。
在LOOCV中,每次迭代只用到一个样本作为验证集,因此不会出现数据子集划分的问题,可以为数据集提供一个稳定的性能估计。但需要注意的是,由于验证集和训练集的差异非常小,可能无法完全反映模型在全新数据上的泛化能力。
```python
# 示例代码展示如何在Python中实现LOOCV
from sklearn.model_selection import LeaveOneOut
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
X, y = load_iris(return_X_y=True)
loo = LeaveOneOut()
model = RandomForestClassifier(n_estimators=10, random_state=0)
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# 在这里可以添加代码评价模型性能
```
#### 2.3.2 K折交叉验证
K折交叉验证是最常用的交叉验证技术之一。在这种方法中,数据集被随机分割成K个大小相等的子集。在每次迭代中,一个不同的子集被保留作为验证集,其余的K-1个子集作为训练集。该过程重复K次,每次用不同的子集作为验证集,其余作为训练集,最后将K次迭代的性能结果进行平均,作为模型性能的最终估计。
K折交叉验证的一个关键参数是K的大小。较大的K值意味着模型会用较少的数据进行训练,可能会导致模型欠拟合;较小的K值则意味着模型会用较多的数据进行训练,但交叉验证的次数减少,可能会导致模型过拟合。通常,K取值为5或10,能够提供一个不错的折中。
```mermaid
flowchart LR
A[开始交叉验证] --> B[将数据分割为K=10份]
B --> C{遍历10次}
C --> D[每次选取一份作为验证集]
D --> E[剩余九份作为训练集]
E --> F[训练模型并验证]
F --> G[记录结果]
C --> H[计算平均性能]
H --> I[完成交叉验证]
```
#### 2.3.3 分层K折交叉验证
分层K折交叉验证是针对有类别不平衡问题的数据集的一种优化交叉验证技术。在这种方法中,首先根据每个类别在数据集中的比例将数据集分成K个部分,以确保每一折中各类别比例大致相同。然后,与普通K折交叉验证类似,每次迭代中保留一个部分作为验证集,其余部分作为训练集。
这种方法的优势在于能够更好地保持数据集中各类别之间的比例关系,从而确保在交叉验证过程中每个类别都被充分地评估。这在处理如疾病诊断、欺诈检测等类别分布不均的问题时尤为重要。
```python
# 示例代码展示如何在Python中实现分层K折交叉验证
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
X, y = load_iris(return_X_y=True)
skf = StratifiedKFold(n_splits=5)
model = RandomForestClassifier(n_estimators=10, random_state=0)
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# 在这里可以添加代码评价模型性能
```
通过本章节的介绍,我们理解了交叉验证在机器学习中的重要性,以及超参数与模型训练的关系。接着,我们进一步探索了交叉验证的理论依据,包括泛化能力的概念以及验证集和测试集的作用。最后,我们深入了解了几种常见的交叉验证技术,包括留一交叉验证、K折交叉验证和分层K折交叉验证。这些方法能够帮助我们更有效地评估模型的性能,并为超参数的选择提供科学的依据。
# 3. 交叉验证实践策略
在理解了交叉验证的理论基础和常见方法后,本章将深入探讨在实际应用中如何有效运用交叉验证策略,以及如何在模型的超参数优化过程中实施这些策略。我们将从选择交叉验证策略开始,进一步分析如何在交叉验证过程中进行有效的超参数搜索,并评估优化过

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了神经网络超参数调优的方方面面,为读者提供了全面的指南。从基础知识和技巧到高级技术,专栏涵盖了各种主题,包括:避免过拟合、自动化调优、交叉验证设计、案例分析、探索与利用的平衡、统计方法的应用、遗传算法、可视化调优、禁忌搜索法、粒子群优化、强化学习优化、早停法和自适应方法。通过深入的理论讲解和实用的实战技巧,本专栏旨在帮助读者掌握神经网络超参数调优的艺术,最大限度地提高模型性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
供应链革新:EPC C1G2协议在管理中的实际应用案例
# 摘要
EPC C1G2协议作为一项在射频识别技术中广泛采用的标准,在供应链管理和物联网领域发挥着关键作用。本文首先介绍了EPC C1G2协议的基础知识,包括其结构、工作原理及关键技术。接着,通过分析制造业、物流和零售业中的应用案例,展示了该协议如何提升效率、优化操作和增强用户体验。文章还探讨了实施EPC C1G2协议时面临的技术挑战,并提出了一系列解决方案及优化策略。最后,本文提供了一份最佳实践指南,旨在指导读者顺利完成EPC C1G2协议的实施,并评估其效果。本文为EPC C1G2协议的深入理解和有效应用提供了全面的视角。
# 关键字
EPC C1G2协议;射频识别技术;物联网;供应链管
【数据结构与算法实战】

# 摘要
数据结构与算法是计算机科学的基础,对于软件开发和系统设计至关重要。本文详细探讨了数据结构与算法的核心概念,对常见数据结构如数组、链表、栈、队列和树等进行了深入分析,同
【Ansys参数设置实操教程】:7个案例带你精通模拟分析
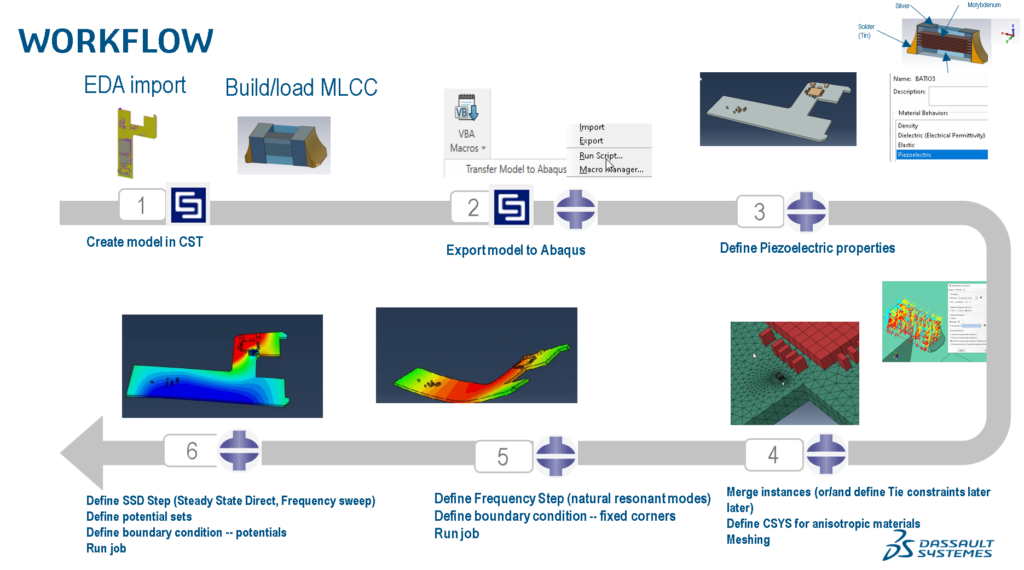
# 摘要
本文系统地介绍了Ansys软件中参数设置的基础知识与高级技巧,涵盖了结构分析、热分析和流体动力学等多方面应用。通过理论与实际案例的结合,文章首先强调了Ansys参数设置的重要性,并详细阐述了各种参数类型、数据结构和设置方法。进一步地,本文展示了如何在不同类型的工程分析中应用这些参数,并通过实例分析,提供了参数设置的实战经验,包括参数化建模、耦合分析以及参数优化等方面。最后,文章展望
【离散时间信号与系统】:第三版习题解密,实用技巧大公开

# 摘要
离散时间信号与系统的分析和处理是数字信号处理领域中的核心内容。本文全面系统地介绍了离散时间信号的基本概念、离散时间系统的分类及特性、Z变换的理论与实践应用、以及离散时间信号处理的高级主题。通过对Z变换定义、性质和在信号处理中的具体应用进行深入探讨,本文不仅涵盖了系统函数的Z域表示和稳定性分析,还包括了Z变换的计算方法,如部分分式展开法、留数法及逆Z变换的数值计算方法。同时,本文还对离散时间系
立体声分离度:测试重要性与提升收音机性能的技巧

# 摘要
立体声分离度是评估音质和声场表现的重要参数,它直接关联到用户的听觉体验和音频设备的性能。本文全面探讨了立体声分离度的基础概念、测试重要性、影响因素以及硬件和软件层面的提升措施。文章不仅分析了麦克风布局、信号处理技术、音频电路设计等硬件因素,还探讨了音频编辑软件、编码传输优化以及后期处理等软件策略对分离度的正面影响。通过实战应用案例分析,本文展示了在收音机和音频产品开
【热分析高级技巧】:活化能数据解读的专家指南
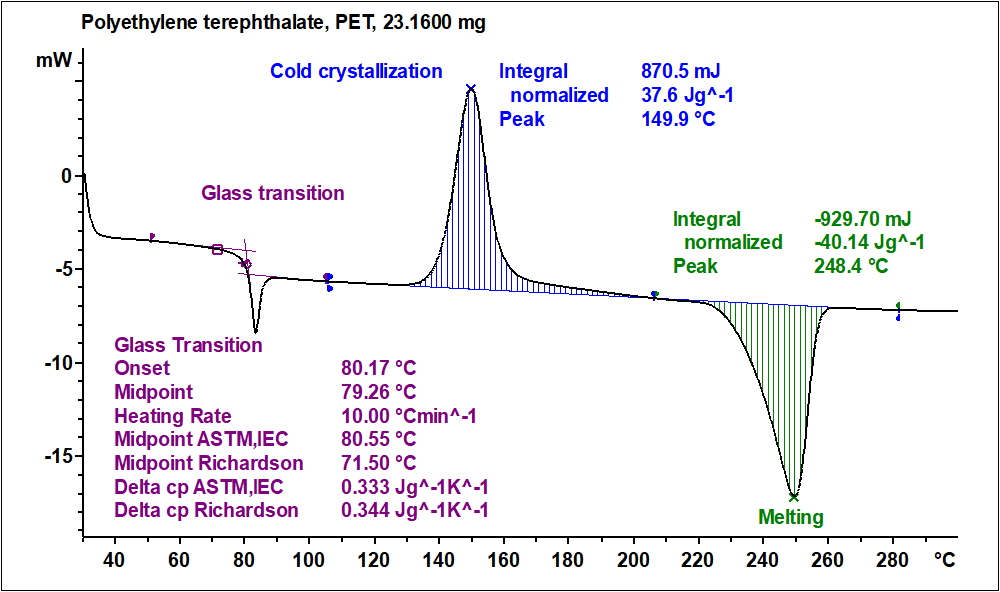
# 摘要
热分析技术作为物质特性研究的重要方法,涉及到对材料在温度变化下的物理和化学行为进行监测。本论文全面概述了热分析技术的基础知识,重点阐述了活化能理论,探讨了活化能的定义、重要性以及其与化学反应速率的关系。文章详细介绍了活化能的多种计算方法,包括阿伦尼乌斯方程及其他模型,并讨论了活化能数据分析技术,如热动力学分析法和微分扫描量热法(DSC)。同时,本文还提供了活化能实验操作技巧,包括实验设计、样品准备、仪器使用
ETA6884移动电源温度管理:如何实现最佳冷却效果

# 摘要
本论文旨在探讨ETA6884移动电源的温度管理问题。首先,文章概述了温度管理在移动电源中的重要性,并介绍了相关的热力学基础理论。接着,详细分析了移动电源内部温度分布特性及其对充放电过程的影响。第三章阐述了温度管理系统的设计原则和传感器技术,以及主动与被动冷却系统的具体实施。第四章通过实验设计和测试方法评估了冷却系统的性能,并提出了改进策略。最后,
【PCM测试高级解读】:精通参数调整与测试结果分析
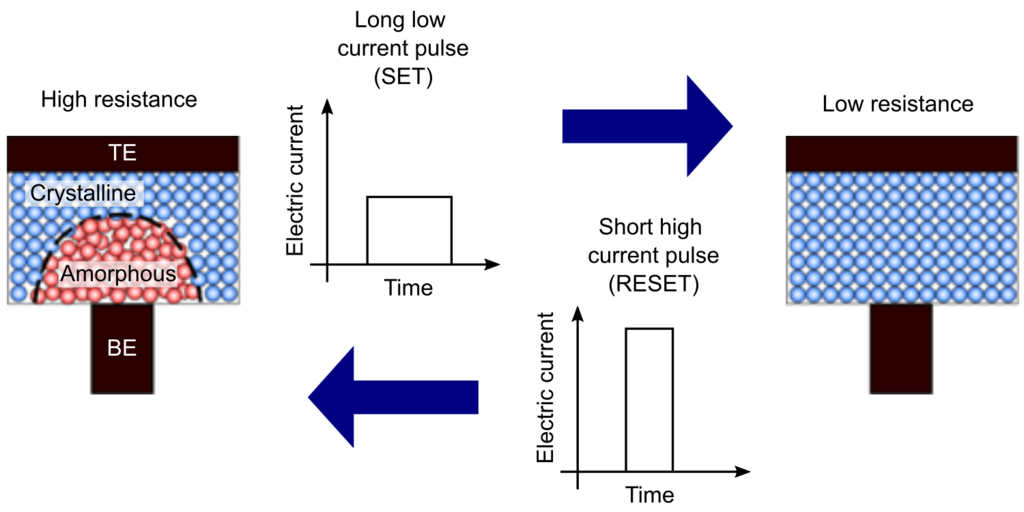
# 摘要
PCM测试作为衡量系统性能的重要手段,在硬件配置、软件环境搭建以及参数调整等多个方面起着关键作用。本文首先介绍PCM测试的基础概念和关键参数,包括它们的定义、作用及其相互影响。随后,文章深入分析了测试结果的数据分析、可视化处理和性能评估方法。在应用实践方面,本文探讨了PCM测试在系统优化、故障排除和性能监控中的实际应用案例。此外,文章还分享了PCM测试的高级技巧与最佳实践,并对测试技术未来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )