Celery任务定义与配置秘籍:编写高效任务代码的6大策略
发布时间: 2024-10-16 03:32:32 阅读量: 32 订阅数: 21 

PyPI 官网下载 | celery-director-0.2.2.tar.gz
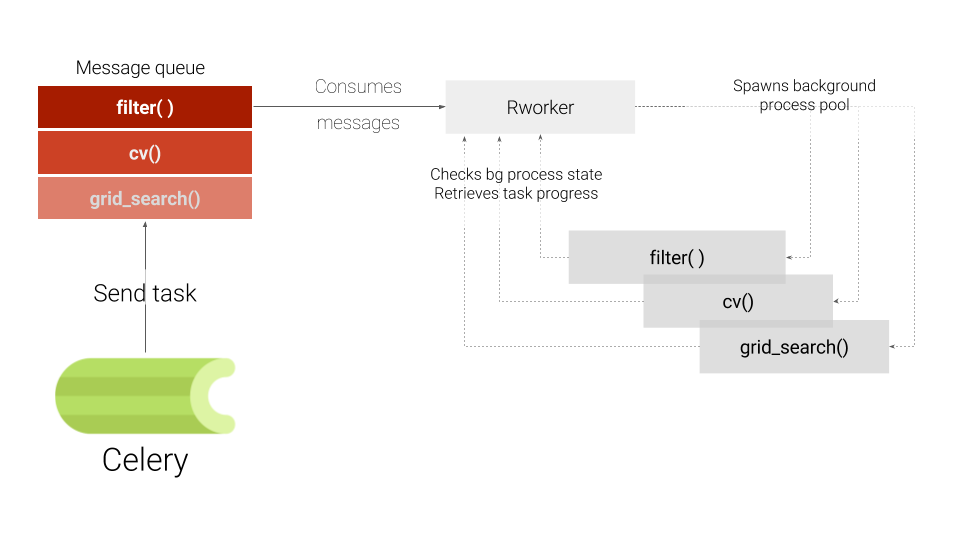
# 1. Celery任务的基础概念与架构
## 1.1 Celery简介
Celery是一个强大的异步任务队列/作业队列,基于分布式消息传递。它专注于实时操作,但也支持定时任务。Celery的使用场景广泛,从简单的后台任务到复杂的分布式系统任务调度,都能提供高效的支持。
## 1.2 核心组件
Celery系统主要由以下几个核心组件构成:
- **Broker(消息代理)**: 负责接收任务并将它们分派给工作节点。常用的代理包括RabbitMQ和Redis。
- **Worker(工作节点)**: 执行任务的进程。一个或多个Worker可以从Broker中获取任务并执行。
- **Task(任务)**: 任务是Celery执行的基本单元,可以是任何Python函数。
- **Result Backend(结果后端)**: 用于存储任务执行的结果。它可以是一个简单的内存结构,也可以是一个数据库。
## 1.3 工作流程
Celery的工作流程相对简单:
1. 定义任务:创建一个Python函数,使用Celery提供的装饰器进行装饰。
2. 配置Broker和Result Backend。
3. 启动Worker:通过命令行启动一个或多个Worker进程。
4. 触发任务:从客户端应用程序或脚本中触发任务执行。
```python
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task
def add(x, y):
return x + y
# 启动Worker
# celery -A tasks worker --loglevel=info
```
## 1.4 为什么选择Celery
Celery支持多种消息代理,具有高度的可扩展性,可以轻松地与Web框架和缓存系统集成。此外,它提供了强大的任务调度和监控功能,使其成为处理异步任务的理想选择。对于大型分布式系统,Celery能够有效地管理负载和提升系统的稳定性。
# 2. Celery任务的定义与编写
Celery 是一个强大的异步任务队列/作业队列,基于分布式消息传递。它被设计用来执行大量的任务,而这些任务不需要立即执行,甚至可以被延迟到将来某个时间点执行。本章节将深入探讨如何定义和编写Celery任务,包括创建简单和复杂的任务,处理任务参数,以及错误处理和重试机制。
### 2.1 任务的创建和组织
#### 2.1.1 定义简单任务
在Celery中,任务可以通过装饰器来定义。最简单的方式是使用`@app.task`装饰器。下面是一个定义了一个简单任务的例子:
```python
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task
def add(x, y):
return x + y
```
在这个例子中,我们首先导入了`Celery`类,并创建了一个Celery应用实例。然后,我们定义了一个`add`函数,并用`@app.task`装饰器将其注册为一个任务。
**代码逻辑解读分析**:
- `app = Celery('tasks', broker='pyamqp://guest@localhost//')`:创建Celery应用实例,并指定消息代理(Broker)。
- `@app.task`:装饰器用于将函数注册为Celery任务。
- `def add(x, y)`:定义了一个简单的加法函数。
#### 2.1.2 创建复杂任务和任务链
有时候,任务可能需要执行多个步骤,这时候可以创建复杂的任务。Celery提供了链式任务(Chaining)和组任务(Groups)来组织复杂任务。
```python
from celery import chain
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
# 创建一个任务链
chained = chain(add.s(3, 4) | mul.s(2))
result = chained()
print(result.get())
```
在这个例子中,我们定义了两个任务`add`和`mul`,然后使用`chain`函数将它们组织成一个任务链。`add`的结果会作为`mul`的输入参数。
**代码逻辑解读分析**:
- `chain(add.s(3, 4) | mul.s(2))`:创建了一个任务链,其中`add`的结果会传递给`mul`。
### 2.2 任务的参数和返回值
#### 2.2.1 任务参数的传递和处理
任务参数的传递可以通过位置参数和关键字参数来完成。Celery还支持使用签名(signatures)来封装参数,这使得参数可以在任务链中传递。
```python
@app.task
def greet(first_name, last_name):
return f"Hello {first_name} {last_name}"
# 使用签名封装参数
signature_task = greet.signature(('John', 'Doe'))
result = signature_task.apply_async()
print(result.get())
```
在这个例子中,我们定义了一个`greet`任务,然后使用`signature`方法创建了一个包含参数的签名。`apply_async`方法用于异步执行任务。
**代码逻辑解读分析**:
- `greet.signature(('John', 'Doe'))`:创建了一个带有特定参数的签名。
- `result = signature_task.apply_async()`:异步执行签名任务。
#### 2.2.2 返回值的收集和使用
Celery任务的返回值可以是任何可序列化的对象。返回值可以被存储和检索,这对于任务链和任务重试非常有用。
```python
from celery import group
@app.task
def add(x, y):
return x + y
# 创建一个任务组,并收集返回值
group_task = group([add.s(i, i) for i in range(10)])
result = group_task.apply_async()
results = result.get()
print(results)
```
在这个例子中,我们定义了一个`add`任务,然后创建了一个任务组,其中包含了一系列的`add`任务。`apply_async`方法用于异步执行任务组,返回值被收集并存储在一个列表中。
**代码逻辑解读分析**:
- `group([add.s(i, i) for i in range(10)])`:创建了一个任务组,包含10个加法任务。
- `result = group_task.apply_async()`:异步执行任务组。
- `results = result.get()`:获取所有任务的返回值。
### 2.3 任务的错误处理和重试机制
#### 2.3.1 错误处理策略
Celery提供了多种错误处理策略,包括重试、忽略、回退等。默认情况下,Celery会重试失败的任务。
```python
@app.task(bind=True, autoretry_for=(Exception,), retry_backoff=True)
def error_task(self):
raise Exception("Error occurred")
```
在这个例子中,我们定义了一个`error_task`任务,它会抛出一个异常。通过设置`autoretry_for`和`retry_backoff`参数,我们指定了错误处理策略,即自动重试。
**代码逻辑解读分析**:
- `@app.task(bind=True, autoretry_for=(Exception,), retry_backoff=True)`:装饰器定义了任务和错误处理策略。
- `raise Exception("Error occurred")`:任务抛出异常以触发重试机制。
#### 2.3.2 重试机制的配置和优化
Celery的重试机制可以通过配置参数进行优化,例如设置最大重试次数、重试延迟等。
```python
from celery import current_app
@current_app.task(bind=True, max_retries=3, default_retry_delay=5)
def retry_task(self, exc, interval=5):
raise exc
```
在这个例子中,我们定义了一个`retry_task`任务,它会根据传入的异常信息进行重试。通过设置`max_retries`和`default_retry_delay`参数,我们配置了最大重试次数和默认重试延迟。
**代码逻辑解读分析**:
- `@current_app.task(bind=True, max_retries=3, default_retry_delay=5)`:装饰器定义了任务和重试配置。
- `raise exc`:任务抛出异常以触发重试机制。
通过本章节的介绍,我们了解了如何定义和编写Celery任务,包括创建简单和复杂的任务,处理任务参数,以及错误处理和重试机制。这些基础知识是使用Celery进行任务编排和管理的关键。在本章节中,我们通过具体的代码示例和逻辑分析,展示了如何使用Celery的装饰器、签名和错误处理机制来创建强大的任务。总结来说,Celery提供了一种灵活的方式来处理复杂的异步任务,使得开发和维护大规模的异步任务变得更加容易。
# 3. Celery任务的配置与优化
在本章节中,我们将深入探讨Celery任务的配置与优化,这是提升Celery应用性能和可靠性的关键步骤。我们将从基本配置参数的详细解释开始,逐步深入到高级配置选项和用途,以及如何优化任务执行性能和管理任务调度。本章节的目标是为读者提供一套完整的Celery配置和优化指南,帮助他们在实际项目中更好地应用Celery。
## 3.1 配置Celery应用
### 3.1.1 基本配置参数详解
Celery的配置相对直观,但是要理解每个参数的作用和如何正确设置它们,需要一定的实践经验和理论知识。下面是一些基本配置参数的详细解释:
#### broker_url
这是指定消息代理的URL。Celery使用消息代理来接收和发送消息,这是任务分发的核心。例如:
```python
broker_url = 'redis://localhost:6379/0'
```
这里我们使用了Redis作为消息代理,并指定了本地主机和默认端口。
#### result_backend
这是指定结果后端的URL,用于存储任务执行的结果。例如:
```python
result_backend = 'db+sqlite:///results.db'
```
这里我们使用了SQLite数据库来存储任务结果。
#### task_serializer
这是指定任务序列化方式的参数,常见的有json、pickle等。例如:
```python
task_serializer = 'json'
```
这里我们使用了json作为任务的序列化方式。
#### accept_content
这个参数用于指定内容类型,Celery可以接受哪些类型的消息。例如:
```python
accept_content = ['json', 'msgpack', 'yaml']
```
这里我们指定了支持json、msgpack和yaml三种内容类型。
### 3.1.2 高级配置选项和用途
除了基本配置参数外,Celery还提供了一系列高级配置选项,这些选项可以帮助我们更好地控制任务的执行和行为。
#### task_routes
这个参数用于路由特定的任务到指定的队列。例如:
```python
task_routes = {
'myapp.tasks.my_task': {'queue': 'lowpri'},
}
```
这里我们将`myapp.tasks.my_task`任务路由到了`lowpri`队列。
#### worker_concurrency
这是指定工作进程并发数的参数。例如:
```python
worker_concurrency = 4
```
这里我们将工作进程的并发数设置为4。
#### prefetch_multiplier
这个参数用于控制工作进程预取任务的数量。例如:
```python
prefetch_multiplier = 4
```
这里我们将预取任务的数量设置为4倍。
## 3.2 优化任务执行性能
### 3.2.1 任务批处理和优先级设置
任务批处理是将多个任务打包成一批进行处理,这可以减少消息代理的负载和提高效率。在Celery中,我们可以使用`group`或`chord`来实现任务批处理。
#### 使用group进行任务批处理
```python
from celery import group
tasks = group([
myapp.tasks.my_task.s(i) for i in range(10)
])
result = tasks.apply_async()
```
这里我们创建了一个任务组,包含了10个`my_task`任务。
#### 优先级设置
Celery允许我们为任务设置优先级,优先级较高的任务会被优先处理。
```python
from celery import current_app
current_app.control.inspect().prioritize(
'***', 9, ['task_id_1', 'task_id_2']
)
```
这里我们将`task_id_1`和`task_id_2`这两个任务的优先级设置为9。
### 3.2.2 工作进程和并发性的管理
正确管理工作进程和并发性对于提高任务执行性能至关重要。
#### 控制工作进程数量
```python
celery --concurrency=10 worker --loglevel=info
```
这里我们启动了10个工作进程。
#### 动态调整工作进程
Celery提供了一些命令来动态调整工作进程的数量。
```python
from celery.control import inspect
i = inspect()
i.pool_grow(5)
```
这里我们将工作进程的数量动态增加了5个。
## 3.3 任务调度和定时执行
### 3.3.1 使用Crontab进行定时任务
Crontab是Unix系统中的定时任务工具,Celery提供了Crontab调度器,可以让我们按照Crontab的格式来设置定时任务。
#### 设置定时任务
```python
from celery.schedules import crontab
app.conf.beat_schedule = {
'add-every-minute': {
'task': 'tasks.add',
'schedule': crontab(minute='*/1'),
'args': (16, 16)
},
}
```
这里我们设置了一个每分钟执行一次的定时任务。
### 3.3.2 周期性任务的配置和管理
周期性任务是指那些需要在固定时间间隔内重复执行的任务。
#### 配置周期性任务
```python
from celery.schedules import crontab
app.conf.beat_schedule = {
'add-every-hour': {
'task': 'tasks.add',
'schedule': crontab(hour=17),
'args': (16, 16)
},
}
```
这里我们设置了一个每小时执行一次的周期性任务。
#### 管理周期性任务
Celery提供了一些命令来管理和维护周期性任务。
```python
celery beat -f celerybeat.pid --loglevel=info
```
这里我们启动了Celery的beat服务,并指定了日志级别和输出pid文件。
通过本章节的介绍,我们了解了Celery任务的配置与优化的基本概念和方法。在实际应用中,我们需要根据项目的具体需求和环境来调整这些配置参数,以达到最佳的性能和效果。在下一章中,我们将通过实践案例来分析Celery任务在不同场景下的应用和优化策略。
# 4. Celery任务实践案例分析
在本章节中,我们将深入探讨Celery任务在实际项目中的应用,并通过案例分析来展示如何实现RESTful API中的Celery任务,以及如何在大型项目中进行任务分布与负载均衡。我们还将讨论如何在分布式系统中进行任务追踪与监控,以及如何使用Celerybeat进行任务调度监控。此外,我们还将探索如何集成第三方监控工具,以及一些高级任务管理技巧和Celery任务的扩展与最佳实践。
### 4.1 实现RESTful API中的Celery任务
#### 4.1.1 集成Celery与Web框架
在实现RESTful API时,使用Celery可以有效地将耗时的后台任务异步化,从而提高API的响应速度和系统的整体性能。本节将介绍如何将Celery与Web框架(如Django、Flask等)集成,以及如何创建异步任务处理流程。
Celery与Web框架的集成通常涉及到以下几个步骤:
1. **安装Celery和消息代理**:确保Celery和消息代理(如RabbitMQ或Redis)已经安装并运行。
2. **配置Celery实例**:在Web框架的项目设置中配置Celery实例,包括指定消息代理的地址和端口。
3. **创建Celery应用**:在Web应用中创建一个Celery应用,并定义任务。
4. **启动Celery Worker**:在命令行中启动Celery Worker来执行后台任务。
下面是一个简单的Flask应用集成Celery的例子:
```python
from flask import Flask
from celery import Celery
app = Flask(__name__)
celery = Celery(app.name, broker='redis://localhost:6379/0')
@celery.task
def add(a, b):
return a + b
@app.route('/add/<int:a>/<int:b>')
def add_api(a, b):
result = add.delay(a, b)
return 'Task submitted. Result ID: {}'.format(result.id)
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们创建了一个简单的Flask应用,并定义了一个Celery应用。我们还定义了一个名为`add`的任务,它将两个数字相加。通过`add_api`视图函数,我们提交了一个异步任务,并返回了一个包含任务ID的响应。
#### 4.1.2 创建异步任务处理流程
在Web应用中创建异步任务处理流程涉及到几个关键步骤:
1. **定义任务**:在Celery应用中定义需要异步执行的任务。
2. **提交任务**:通过调用任务的`.delay()`方法来异步提交任务。
3. **处理任务结果**:可以使用Celery提供的工具来处理任务的结果,例如使用`apply_async`的`link`和`link_error`回调。
以下是一个简单的例子,展示了如何提交任务并处理结果:
```python
from celery import Celery
celery = Celery(broker='redis://localhost:6379/0')
@celery.task
def add(a, b):
return a + b
def on_success(result):
print('Task completed successfully:', result)
def on_failure(task_id, exception, traceback):
print('Task failed:', task_id, exception)
add.apply_async(args=(2, 3), link=on_success, link_error=on_failure)
```
在这个例子中,我们定义了一个`add`任务,并在提交任务时指定了成功和失败的回调函数。
### 4.2 大型项目中的任务分布与负载均衡
#### 4.2.1 任务分布策略
在大型项目中,任务分布是提高效率和扩展性的关键。Celery提供了多种任务分布策略,例如轮询、随机、负载均衡等。通过合理配置,可以根据不同的需求选择合适的任务分布策略。
下面是一个使用轮询策略的Celery配置示例:
```python
from celery import Celery
celery = Celery('myproj', broker='redis://localhost:6379/0')
class Config(object):
CELERYD_WORKER领会ATEGY = 'round-robin'
celery.config_from_object(Config)
```
在这个配置中,我们设置了`CELERYD_WORKER领会ATEGY`为`round-robin`,这意味着任务将按照轮询的方式分配给不同的工作进程。
#### 4.2.2 负载均衡的实现和优化
负载均衡是确保系统稳定运行的重要手段。Celery支持多种负载均衡算法,可以通过调整配置来实现。
以下是一个配置负载均衡的例子:
```python
from celery import Celery
celery = Celery('myproj', broker='redis://localhost:6379/0')
class Config(object):
CELERYD_PREFETCH_MULTIPLIER = 4
CELERYD_MAX_TASKS_PER_CHILD = 1000
celery.config_from_object(Config)
```
在这个配置中,我们设置了`CELERYD_PREFETCH_MULTIPLIER`为`4`,这意味着每个工作进程将预取的任务数量是它的并发数乘以4。`CELERYD_MAX_TASKS_PER_CHILD`设置为`1000`,意味着每个工作进程将处理1000个任务后重启。
### 4.3 分布式系统的任务追踪与监控
#### 4.3.1 使用Celerybeat进行任务调度监控
Celerybeat是一个内置的定时任务调度器,它可以在分布式系统中用于监控和调度定时任务。通过Celerybeat,可以定期执行任务,例如定时发送邮件、执行数据备份等。
以下是一个使用Celerybeat的例子:
```python
from celery import Celery
from celery.schedules import crontab
celery = Celery('myproj', broker='redis://localhost:6379/0')
@celery.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# 每天执行任务
sender.add_periodic_task(10.0, myperiodic_task.s('hello', 'world'))
@celery.task
def myperiodic_task(arg1, arg2):
print('Hello World:', arg1, arg2)
if __name__ == '__main__':
celery.start()
```
在这个例子中,我们定义了一个名为`myperiodic_task`的周期性任务,并设置了每天执行一次。
#### 4.3.2 集成第三方监控工具
为了更好地监控Celery任务的执行情况,可以集成第三方监控工具,例如Prometheus、Grafana等。这些工具可以帮助你收集和展示任务的性能指标,例如任务执行时间、错误率等。
以下是一个集成Prometheus的例子:
1. **安装Prometheus和Grafana**:首先安装Prometheus和Grafana。
2. **配置Celery导出器**:安装并配置Celery导出器,它会将Celery任务的性能指标导出到Prometheus。
3. **配置Grafana数据源和仪表板**:在Grafana中添加Prometheus作为数据源,并创建一个仪表板来展示Celery任务的性能指标。
通过上述步骤,你可以使用Grafana来监控Celery任务的性能,并根据需要进行优化。
通过本章节的介绍,我们展示了Celery任务在RESTful API、大型项目和分布式系统中的实践案例。我们讨论了如何集成Celery与Web框架、如何创建异步任务处理流程、如何在大型项目中进行任务分布与负载均衡,以及如何使用Celerybeat进行任务调度监控。此外,我们还探讨了如何集成第三方监控工具来提升系统的监控能力。这些实践案例为Celery任务的实际应用提供了有价值的参考和指导。
# 5. Celery任务的进阶应用
## 5.1 使用Celery与其他系统集成
Celery作为一个强大的分布式任务队列系统,它的设计初衷就是为了与各种系统进行集成,从而实现更加复杂和灵活的任务处理流程。在这一节中,我们将探讨Celery如何与消息队列服务、缓存系统和数据库进行集成。
### 5.1.1 与消息队列服务的集成
Celery本身就是基于消息队列的,它可以与RabbitMQ、Redis等多种消息队列服务集成。这种集成可以帮助我们实现系统之间的解耦,提高系统的可扩展性和可靠性。
#### 集成RabbitMQ
要将Celery与RabbitMQ集成,你需要在Celery的配置文件中指定消息代理的URL:
```python
broker_url = 'amqp://username:password@host:port/vhost'
```
这里是一个简单的例子,演示了如何在Celery中配置RabbitMQ作为消息代理:
```python
# celery_config.py
from kombu import Queue, Exchange
BROKER_URL = 'amqp://guest:guest@localhost:5672//'
CELERY_QUEUES = (
Queue('default', Exchange('default'), routing_key='default'),
Queue('high_priority', Exchange('high_priority'), routing_key='high_priority', queue_arguments={'x-max-priority': '10'}),
)
CELERY_DEFAULT_QUEUE = 'default'
CELERY_DEFAULT_EXCHANGE = 'default'
CELERY_DEFAULT_ROUTING_KEY = 'default'
```
然后,在你的Celery应用中加载这个配置:
```python
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest:guest@localhost//')
app.config_from_object('celery_config')
```
#### 集成Redis
如果你更喜欢使用Redis作为消息代理,那么配置起来也非常简单。这里是一个例子:
```python
# celery_config.py
BROKER_URL = 'redis://localhost:6379/0'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
```
加载配置的代码与上面相同,只需要确保你已经安装了`redis`和`kombu`库。
### 5.1.2 与缓存系统和数据库的交互
Celery不仅可以处理后台任务,还可以与缓存系统和数据库进行交互,这对于需要持久化存储任务结果或状态的应用来说非常有用。
#### 使用缓存
假设我们使用Redis作为缓存,可以将任务结果缓存起来,以便后续快速访问:
```python
from celery import Celery
from redis import Redis
from myapp.cache import get_redis_connection
app = Celery('tasks', broker='pyamqp://guest:guest@localhost//')
@app.task
def compute_data(x):
# 假设这是一些计算密集型任务
result = some_complex_computation(x)
# 将结果存储到缓存中
redis_conn = get_redis_connection()
redis_conn.set(f'result_{x}', result)
return result
```
#### 使用数据库
对于数据库交互,Celery提供了数据库ORM的支持,可以直接在任务中进行数据库操作:
```python
from celery import Celery
from myapp.models import DataRecord
app = Celery('tasks', broker='pyamqp://guest:guest@localhost//')
@app.task
def save_data(x, value):
record = DataRecord(x=x, value=value)
record.save()
return record.id
```
在这个例子中,我们定义了一个任务`save_data`,它创建并保存了一个`DataRecord`对象。
## 5.2 高级任务管理技巧
随着应用的发展,我们可能需要更多的控制来管理Celery任务,例如动态调度和取消任务,或者自定义任务分发策略。这一节将介绍这些高级任务管理技巧。
### 5.2.1 任务的动态调度和取消
Celery提供了强大的动态调度和取消任务的能力,这对于处理可变的任务需求非常有用。
#### 动态调度任务
可以使用`apply_async`方法动态地将任务添加到队列中:
```python
from myapp.tasks import compute_data
# 假设x是我们动态计算的参数
x = 42
result = compute_data.apply_async(args=[x], countdown=10)
```
在这个例子中,我们使用`countdown`参数设置了任务延迟10秒执行。
#### 取消任务
要取消一个已经调度的任务,我们可以使用任务的`revoke`方法:
```python
result = compute_data.apply_async(args=[x], countdown=10)
# 假设在某些条件下我们决定取消这个任务
result.revoke(terminate=True)
```
这里,我们通过`terminate=True`参数强制终止任务。
### 5.2.2 自定义任务分发策略
Celery默认使用轮询调度策略来分发任务。如果你需要更复杂的分发逻辑,比如基于地理位置的任务分发,你可以自定义分发策略。
#### 定义自定义分发策略
下面是一个自定义分发策略的例子,它将任务分发到特定的队列:
```python
from celery import Celery
from celery.task import Task
app = Celery('tasks', broker='pyamqp://guest:guest@localhost//')
class GeoTask(Task):
def __call__(self, *args, **kwargs):
if self.request.is_eager:
return super().__call__(*args, **kwargs)
location = get_location_from_request(*args, **kwargs)
queue_name = f'geo_{location}'
self.request.delivery_info['routing_key'] = queue_name
return super().__call__(*args, **kwargs)
@app.task(base=GeoTask)
def process_data(data):
# 处理数据的逻辑
pass
```
在这个例子中,我们定义了一个`GeoTask`类,它根据请求的位置信息选择不同的队列来执行任务。
## 5.3 Celery任务的扩展和最佳实践
Celery提供了强大的扩展机制,允许我们开发自定义的任务类,并且遵循最佳实践来优化我们的任务代码。
### 5.3.1 开发自定义Celery任务类
自定义任务类可以帮助我们封装通用的逻辑,使得任务更加模块化和可重用。
#### 定义自定义任务类
下面是一个自定义任务类的例子,它封装了日志记录的逻辑:
```python
import logging
from celery import Task
logger = logging.getLogger(__name__)
class CustomTask(Task):
abstract = True
def __call__(self, *args, **kwargs):
try:
***(f'Starting task {self.name}')
result = super().__call__(*args, **kwargs)
***(f'Task {self.name} completed successfully')
return result
except Exception as e:
logger.exception(f'Error in task {self.name}: {e}')
raise
@app.task(base=CustomTask)
def my_task():
# 任务的实现逻辑
pass
```
在这个例子中,我们定义了一个`CustomTask`类,它在任务执行前后记录日志。
### 5.3.2 遵循Celery任务开发的最佳实践
遵循最佳实践可以帮助我们编写更高效、更可靠的Celery任务代码。
#### 最佳实践
1. **避免在任务中进行阻塞调用**:这可以防止阻塞工作进程,提高系统的吞吐量。
2. **合理配置任务优先级**:通过设置不同的优先级,可以控制任务的执行顺序。
3. **使用消息代理的持久化特性**:确保即使在系统崩溃后,任务也能被重新调度和执行。
4. **编写幂等性任务**:幂等性任务即使被多次执行也不会改变系统的最终状态。
通过遵循这些最佳实践,我们可以确保我们的Celery任务既高效又可靠。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Celery,一个强大的 Python 分布式任务队列。它涵盖了 Celery 的方方面面,从基础概念到高级特性。读者将了解 Celery 的架构、任务定义、消息代理、调度策略、异常处理、性能优化、负载均衡、监控、安全机制、高级特性、集成指南、工作流编排、事务管理、大数据处理、优先级管理和依赖管理。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者掌握 Celery 的核心原理和最佳实践,从而构建高效、可靠和可扩展的任务处理系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Desigo CC 系统概述】:楼宇自动化的新视界

参考资源链接:[Desigo CC 培训资料.pdf](https://wenku.csdn.net/doc/6412b739be7fbd1778d49876?spm=1055.2635.3001.10343)
# 1. Desigo CC系统概念与架构
## Desigo CC系统简介
Desigo CC,作为楼宇自动化和智能建
【后端地图数据集成】:无缝融入Web应用的中国地图JSON数据包

参考资源链接:[中国省级行政区Json数据包](https://wenku.csdn.net/doc/3h7d7rsva2?spm=1055.2635.3001.10343)
# 1. 后端地图数据集成概述
在当今数字化的世界中,地图数据已成为后端服务不可或
PELCO-D协议入门指南:掌握基本概念与安装步骤(新手必看:一文读懂视频监控基础)
参考资源链接:[PELCO-D协议中文.docx](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e68?spm=1055.2635.3001.10343)
# 1. PELCO-D协议概述
PELCO-D协议,一种广泛应用于闭路电视(CCTV)监控摄像机的控制协议,其核心优势在于实现了远程控制云台和镜头的动作。本章将简要介绍PELCO-D协议的定义、用途以及它的应用范围。
## 1.1 PELCO-D协议定义
PELCO-D协议是由美国PELCO公司开发的,用于控制PTZ(Pan, Tilt, Zoom)摄像机的行业标准协议。它使得用户能
【KEPServer EX Modbus性能调优】:实现最佳通讯效率的5个策略
参考资源链接:[KEPServer配置Modibus从站通讯](https://wenku.csdn.net/doc/6412b74cbe7fbd1778d49caf?spm=1055.2635.3001.10343)
# 1. KEPServer EX Modbus的通讯基础
KEPServer EX是一种广泛使用的工业通讯服务器,它支持多种通讯协议,其中Modbu
进销存系统需求分析:揭示业务需求核心的终极指南

参考资源链接:[进销存管理系统详细设计:流程、类图与页面解析](https://wenku.csdn.net/doc/6412b5b2be7fbd1778d44129?spm=1055.2635.3001.10343)
# 1. 进销存系统需求概述
进销存系统是现代企业管理中不可或缺的组成部分,它涉及到企业的核心业务——采购、销售以及库存管理。正确理解并明确这些需求对于提高企业的运营效
自动化工程中的PIDE指令:最佳应用实践
参考资源链接:[RSLogix5000中的PIDE指令详解:高级PID控制与操作模式](https://wenku.csdn.net/doc/6412b5febe7fbd1778d45211?spm=1055.2635.3001.10343)
# 1. PIDE指令概念解析
PIDE(Programmable Industrial Digital Executor)指令,是一种专为工业自动化设计的高效指令集,它通过可编程接口使得工业设备能够实现精确、灵活的控制。在这一章中,我们将深入探讨PIDE指令的基本概念,包括它的应用场景、基本功能以及如何在实际工作中使用这一指令集。
## 1.1 P
产品规划与设计:IPD阶段三,确保愿景与技术方案的无缝对接

参考资源链接:[IPD产品开发评审要素详解与模板](https://wenku.csdn.net/doc/644b7797fcc5391368e5ed70?spm=1055.2635.3001.10343)
# 1. 产品规划与设计的IPD阶段三概述
在产品开发的旅程中,集成产品开发
深度剖析iTek相机技术:揭秘其工作原理与应用场景
参考资源链接:[Vulcan-CL采集卡与国产线扫相机设置指南](https://wenku.csdn.net/doc/4d2ufe0152?spm=1055.2635.3001.10343)
# 1. iTek相机技术概述
随着技术的不断进步,iTek相机已经成为图像捕捉领域中的佼佼者。其突破性的技术不仅仅依赖于先进的硬件配置,还涵盖了一系列智能软件的应用,从而在专业摄影、视频制作以及消费电子产品中取得了广泛的应用和好评。
## 1.1 iTek相机的核心价值
iTek相机的核心价值体现在其创新性的设计理念与独特的用户体验上。这一理念贯穿于相机的每一个细节,从硬件的选材、制作工艺,到软件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )