【Hadoop查询性能优化】:LZO压缩技术的影响分析
发布时间: 2024-10-27 06:26:06 阅读量: 5 订阅数: 7 

# 1. Hadoop查询性能优化概述
Hadoop作为大数据存储与计算的骨干技术,其查询性能是系统效率的关键。优化Hadoop查询性能通常涉及硬件优化、查询算法调整以及数据存储格式选择等多个方面。LZO压缩技术作为一种高效的压缩算法,在提升Hadoop查询性能上扮演着重要角色。本文将探索LZO压缩在Hadoop环境中的应用,旨在通过压缩优化来减少数据存储空间,加速数据读写过程,从而达到提升Hadoop查询效率的目的。随着技术的发展,我们也将探讨未来可能出现的优化策略和新兴压缩技术的影响。
# 2. LZO压缩技术基础
### 2.1 LZO压缩算法原理
LZO(Lempel-Ziv-Oberhumer)是一种无损数据压缩算法,它由 Markus Oberhumer 在 1994 年开发。LZO 算法着重于压缩和解压速度,尤其适用于实时数据压缩场景,例如在 Hadoop 环境中快速处理大量数据。
#### 2.1.1 LZO压缩的内部工作机制
LZO 压缩基于 LZ77 压缩家族的技术原理,它不依赖于文件的内容或者文件类型,能够对任何类型的数据进行有效的压缩。在实现压缩时,LZO 会查找数据中的重复字符串,并通过引用先前出现过的字符串来替代重复字符串,从而达到压缩数据的目的。
LZO 的压缩过程主要分为以下几个步骤:
1. **寻找重复字符串:** 通过滑动窗口的方式,LZO 查找当前需要压缩的数据段中重复的字符串。
2. **构造压缩字典:** 在找到重复字符串后,LZO 构造一个字典(通常是压缩头的一部分),这个字典记录了匹配字符串的位置和长度。
3. **输出压缩数据:** LZO 输出压缩后的数据流,其中包含了指向字典的引用和未匹配的数据。
解压过程则相对简单。LZO 解压缩器读取压缩数据流,识别出引用和未压缩的数据,并根据字典中的信息还原出原始数据。由于 LZO 的解压过程不需要额外的字典,所以解压速度非常快。
```c
// LZO压缩的简化伪代码示例
function compress(inputData):
dictionary = buildDictionary(inputData)
compressedData = []
for chunk in inputData:
if isMatch(dictionary, chunk):
compressedData.append(makeReference(dictionary, chunk))
else:
compressedData.append(chunk)
return compressedData
function decompress(compressedData):
for chunk in compressedData:
if isReference(chunk):
originalData = retrieveOriginal(dictionary, chunk)
else:
originalData = chunk
yield originalData
```
LZO 压缩的这种设计确保了其压缩速度和解压速度的平衡,使其成为了一个良好的实时压缩候选算法。
#### 2.1.2 LZO与其他压缩技术的比较
与其他压缩技术相比,LZO 在速度和压缩比之间取得了很好的平衡。以 Gzip(使用 DEFLATE 算法)为例,Gzip 通常提供较高的压缩比,但其压缩和解压速度较慢,适合于存储密集型的场景。而 Bzip2 使用 Burrows-Wheeler 变换和霍夫曼编码技术,在压缩比上表现更佳,但其解压速度较慢。
LZO 的优势在于:
- **压缩速度:** 相比 Gzip 和 Bzip2,LZO 的压缩速度更快,可以在几乎不牺牲性能的情况下进行实时压缩。
- **解压速度:** LZO 的解压速度极快,几乎可以达到原生数据的读取速度。
这使得 LZO 成为需要频繁读写操作的 Hadoop 应用中理想的压缩技术。
### 2.2 Hadoop对压缩技术的支持
Apache Hadoop 是一个开源框架,它允许使用简单的编程模型在分布式环境中进行存储和处理大规模数据集。在 Hadoop 中支持压缩技术是至关重要的,它能有效减少存储空间需求,并提高数据处理速度。
#### 2.2.1 Hadoop压缩框架的组成
Hadoop 压缩框架提供了多种压缩编码器,使得用户可以根据需求选择合适的压缩算法。框架本身不直接提供压缩和解压的实现,而是通过插件的方式支持不同的压缩算法。这包括了著名的 Gzip、Deflate、Bzip2 和 LZO 等压缩编码器。
Hadoop 压缩框架主要由以下几个关键组件组成:
1. ** CompressionCodec:** 这是 Hadoop 压缩框架中的基础接口,定义了压缩和解压数据所需的方法。
2. ** CompressionOutputStream 和 CompressionInputStream:** 这两个流类提供了压缩和解压数据的接口,可以被更深层次的数据处理流所包装使用。
3. ** CompressionCodecFactory:** 该工厂类负责根据文件的扩展名或者指定的编码器名称来创建相应的 CompressionCodec 实例。
```java
// Hadoop CompressionCodec 接口的简化示例
public interface CompressionCodec {
CompressionOutputStream createOutputStream(OutputStream out) throws IOException;
CompressionInputStream createInputStream(InputStream in) throws IOException;
// 其他方法略...
}
// LZO CompressionCodec 实现的简化示例
public class LZOCodec extends CompressionCodec {
@Override
public CompressionOutputStream createOutputStream(OutputStream out) {
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【最新技术探索】:MapReduce数据压缩新趋势分析

# 1. MapReduce框架概述
MapReduce 是一种用于大规模数据处理的编程模型。其核心思想是将计算任务分解为两个阶段:Map(映射)和Reduce(归约)。Map阶段将输入数据转化为一系列中间的键值对,而Reduce阶段则将这些中间键值对合并,以得到最终结果。
MapReduce模型特别适用于大数据处理领域,尤其是那些可以并行
YARN作业性能调优:深入了解参数配置的艺术

# 1. YARN作业性能调优概述
## 简介
随着大数据处理需求的爆炸性增长,YARN(Yet Another Resource Negotiator)作为Hadoop生态中的资源管理层,已经成为处理大规模分布式计算的基础设施。在实际应用中,如何优化YARN以提升作业性能成为了大数据工程师必须面对的课题。
## YARN性能调优的重要
【Hadoop Combiner终极指南】:7大技巧提升MapReduce作业效率
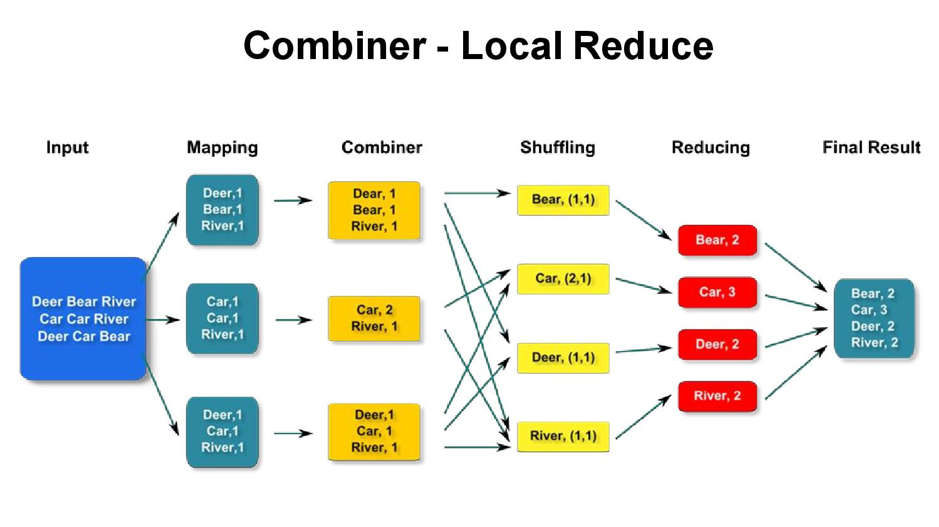
# 1. Hadoop Combiner概念解析
## 1.1 Combiner的定义和作用
Hadoop Combiner是一种优化技术,它在MapReduce框架中起到了重要的作用。它主要用于对Map阶段输出的中间数据进行局部聚合,以减少数据在网络中的传输量,从而提高MapReduce作业的执行效率。
## 1.2 Combine
Bzip2压缩技术进阶:Hadoop大数据处理中的高级应用
# 1. Bzip2压缩技术概述
## 1.1 Bzip2的起源与功能
Bzip2是一种广泛应用于数据压缩的开源软件工具,最初由Julian Seward开发,其独特的压缩算法基于Burrows-Wheeler变换(BWT)和霍夫曼编码。该技术能够将文件和数据流压缩到较小的体积,便于存储和传输。
## 1.2 Bzip2的特点解析
Bzip2最显著的特点是其压缩率较高,通常能够比传统的ZIP和GZIP格式提供更好的压缩效果。尽管压缩和解压缩速度较慢,但在存储空间宝贵和网络传输成本较高的场合,Bzip2显示了其不可替代的优势。
## 1.3 Bzip2的应用场景
在多种场景中,Bzip2都
【Hadoop集群集成】:LZO压缩技术的集成与最佳实践

# 1. Hadoop集群集成LZO压缩技术概述
随着大数据量的不断增长,对存储和计算资源的需求日益增加,压缩技术在数据处理流程中扮演着越来越重要的角色。LZO(Lempel-Ziv-Oberhumer)压缩技术以其高压缩比、快速压缩与解压的特性,在Hadoop集群中得到广泛应用。本章将概述Hadoop集群集成LZO压缩技术的背景、意义以及
Hadoop中Snappy压缩的深度剖析:提升实时数据处理的算法优化

# 1. Hadoop中的数据压缩技术概述
在大数据环境下,数据压缩技术是优化存储和提升数据处理效率的关键环节。Hadoop,作为一个广泛使用的分布式存储和处理框架,为数据压缩提供了多种支持。在本章中,我们将探讨Hadoop中的数据压缩技术,解释它们如何提高存储效率、降低带宽使用、加快数据传输速度,并减少I/O操作。此外,我们将概述Hadoop内建的压缩编码器以及它们的优缺点,为后续章节深入探讨特定压缩算法
【Hadoop数据压缩】:Gzip算法的局限性与改进方向
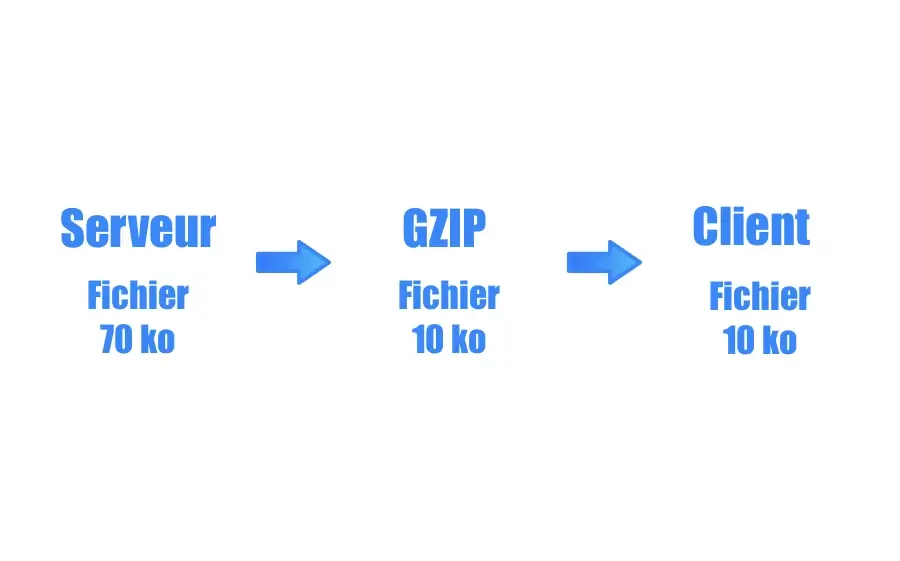
# 1. Hadoop数据压缩概述
随着大数据量的不断增长,数据压缩已成为提升存储效率和传输速度的关键技术之一。Hadoop作为一个分布式系统,其数据压缩功能尤为重要。本章我们将对Hadoop数据压缩进行概述,深入探讨压缩技术在Hadoop中的应用,并简要分析其重要性与影响。
## 1.1 Hadoop数据压缩的必要性
Hadoop集群处理的数据量巨大,有效的数据压缩可以减少存储成本,加快网络传输速度,
Hadoop分块存储读写性能优化:调优与最佳实践指南
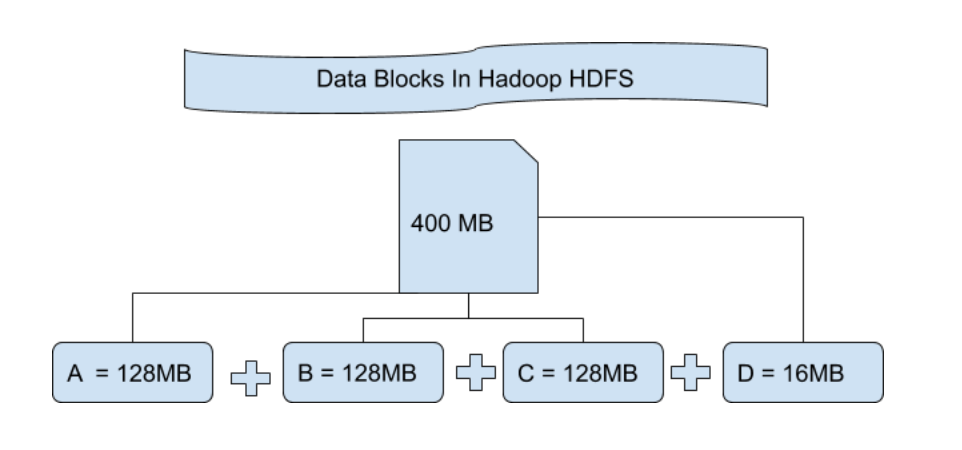
# 1. Hadoop分块存储基础
## 1.1 Hadoop存储结构概述
Hadoop采用分布式存储架构,其中数据被划分为称为“块”的固定大小片段。这种分块存储机制不仅有利于数据的并行处理,也增强了系统的容错能力。块的大小是可以配置的,常见的有64MB和128MB,这直接影响着存储空间的使用效率以及计算任务的分布。
## 1.2 分块存储的工作原理
每个块被复制存储在不同的数
Hadoop压缩技术在大数据分析中的角色:作用解析与影响评估
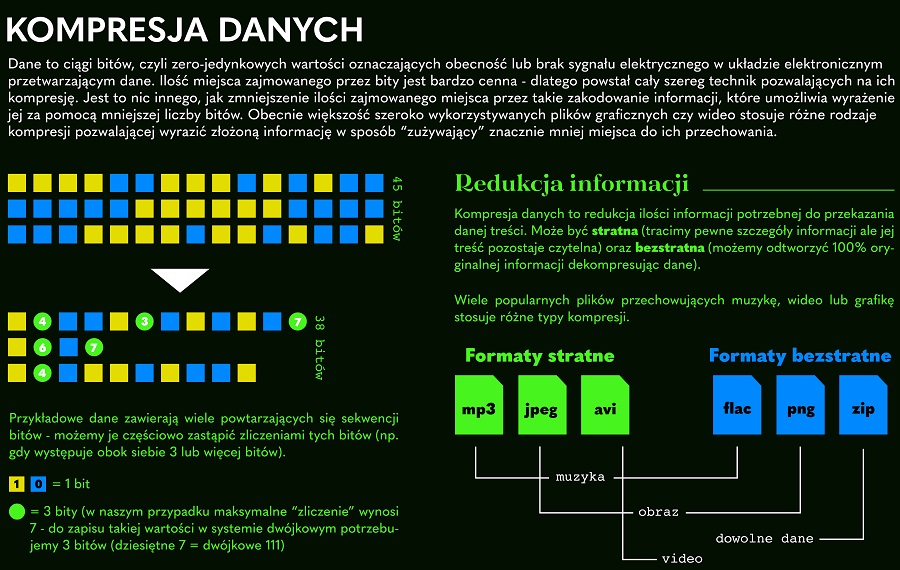
# 1. Hadoop压缩技术概述
在大数据的处理与存储中,压缩技术扮演着至关重要的角色。Hadoop作为一个分布式存储和处理的框架,它能够高效地处理大量数据,而这背后离不开压缩技术的支持。在本章中,我们将简要介绍Hadoop中的压缩技术,并探讨它如何通过减少数据的存储体积和网络
Hadoop块大小与数据本地化:提升MapReduce作业效率的关键

# 1. Hadoop块大小与数据本地化概述
在本章中,我们将揭开Hadoop中块大小设置和数据本地化的神秘面纱。我们会介绍Hadoop如何将文件拆分为固定大小的块以方便管理和计算,以及这些块如何在分布式环境中进行存储。我们将概述块大小如何影响Hadoop集群的性能,并强调数据本地化的重要性——即如何将计算任务尽量调度到包含数据副本的节点上执行,以减少网络传输开销
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )