Hadoop中Snappy压缩的深度剖析:提升实时数据处理的算法优化
发布时间: 2024-10-27 07:24:01 阅读量: 4 订阅数: 5 

# 1. Hadoop中的数据压缩技术概述
在大数据环境下,数据压缩技术是优化存储和提升数据处理效率的关键环节。Hadoop,作为一个广泛使用的分布式存储和处理框架,为数据压缩提供了多种支持。在本章中,我们将探讨Hadoop中的数据压缩技术,解释它们如何提高存储效率、降低带宽使用、加快数据传输速度,并减少I/O操作。此外,我们将概述Hadoop内建的压缩编码器以及它们的优缺点,为后续章节深入探讨特定压缩算法奠定基础。Hadoop的压缩技术不仅包括传统的压缩方法,也不断融入先进的压缩算法以适应大数据时代的需求。
# 2. Snappy压缩算法详解
### 2.1 Snappy压缩算法的工作原理
#### 2.1.1 压缩流程
Snappy是由Google开发的一种压缩算法,主要用于对速度要求极高的场景,尤其是实时数据处理。它不会进行块压缩或字典压缩,而是依赖于简单的启发式方法来快速压缩数据流,其压缩流程如下:
1. **字节级压缩**:Snappy对输入的字节流进行处理,其中某些短的重复字节序列会直接被替换为短的引用。
2. **LZ77风格的压缩**:对于较长的重复字节序列,Snappy采用一种类似于LZ77算法的方式进行处理,通过查找和替换重复的字节序列来减少数据的大小。
3. **哈夫曼编码**:对剩余的数据进行哈夫曼编码,这是一种熵编码方法,可以进一步减小数据体积。
由于Snappy算法的高效性,它在大数据处理和存储中尤其受到重视,特别是在那些需要快速读写操作的应用场合。
#### 2.1.2 压缩与解压的算法细节
Snappy的压缩和解压算法是不对称的。压缩过程旨在尽可能快速地完成,而解压过程相对较慢,但总体来说都维持在较高的性能水平。以下是算法的详细解析:
- **压缩**:Snappy压缩过程的伪代码大致如下:
```python
def snappy_compress(input_data):
compressed_data = []
while len(input_data) > 0:
best_match = find_best_match(input_data)
if best_match:
compressed_data.append(best_match.reference)
input_data = skip_repeated_data(input_data, best_match.length)
else:
compressed_data.append(input_data.pop(1))
return compressed_data
```
在这段代码中,`find_best_match`和`skip_repeated_data`是启发式函数,用于找到最佳匹配并跳过重复数据。实际的Snappy实现会有更多细节,例如处理不同长度的匹配序列和处理特殊序列。
- **解压**:Snappy解压过程则根据压缩数据中的指令进行逆操作,还原原始数据。
### 2.2 Snappy压缩效率与性能分析
#### 2.2.1 压缩比和压缩速度
Snappy旨在以牺牲一定程度的压缩比来换取更快的压缩和解压速度。通常,Snappy可以提供大约25%到50%的压缩比,虽然不如一些块压缩算法如DEFLATE(用于ZIP和GZIP)那么高效,但它在压缩速度上通常快很多倍。
在性能测试中,Snappy通常能够在现代硬件上实现接近内存速度的压缩和解压性能,这是它在大数据应用中极为受欢迎的原因。
#### 2.2.2 与其他压缩算法的比较
与像GZIP这样的传统压缩算法相比,Snappy的性能优势明显。例如,在处理大量实时数据流时,Snappy的快速压缩和解压能力能够显著减少延迟,这是实时数据处理中一个非常重要的考虑因素。
为了更形象地展示Snappy与其他算法的比较,我们可以参考下面的表格:
| 压缩算法 | 压缩速度 | 解压速度 | 压缩比 |
|----------|----------|----------|--------|
| Snappy | 非常快 | 快 | 中等 |
| GZIP | 中等 | 中等 | 高 |
| LZMA | 慢 | 较慢 | 很高 |
需要注意的是,这些数据会根据具体的使用场景和硬件环境有所不同,但总体趋势是相似的。
### 2.3 Snappy在Hadoop中的集成
#### 2.3.1 Hadoop生态系统中的Snappy
Snappy作为Hadoop生态系统中的一种可选压缩格式,被广泛集成到了Hadoop的多个组件中,如HBase、MapReduce和Hive。这允许用户在进行大数据处理时,可以享受到Snappy所带来的快速压缩和解压的能力。
#### 2.3.2 Snappy在不同Hadoop组件中的应用
Hadoop的生态系统组件通过内置对Snappy的支持,使得用户能够轻松地通过配置文件启用Snappy压缩,从而优化数据处理性能。例如,在HBase中启用Snappy压缩可以减少磁盘I/O操作,而MapReduce作业在处理大量数据时,也可以通过启用Snappy压缩来减少任务的磁盘占用和网络传输数据量。
这里展示了Hadoop组件集成Snappy的配置代码块示例:
```xml
<property>
<name>***pression.c
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【最新技术探索】:MapReduce数据压缩新趋势分析

# 1. MapReduce框架概述
MapReduce 是一种用于大规模数据处理的编程模型。其核心思想是将计算任务分解为两个阶段:Map(映射)和Reduce(归约)。Map阶段将输入数据转化为一系列中间的键值对,而Reduce阶段则将这些中间键值对合并,以得到最终结果。
MapReduce模型特别适用于大数据处理领域,尤其是那些可以并行
YARN作业性能调优:深入了解参数配置的艺术

# 1. YARN作业性能调优概述
## 简介
随着大数据处理需求的爆炸性增长,YARN(Yet Another Resource Negotiator)作为Hadoop生态中的资源管理层,已经成为处理大规模分布式计算的基础设施。在实际应用中,如何优化YARN以提升作业性能成为了大数据工程师必须面对的课题。
## YARN性能调优的重要
【Hadoop Combiner终极指南】:7大技巧提升MapReduce作业效率
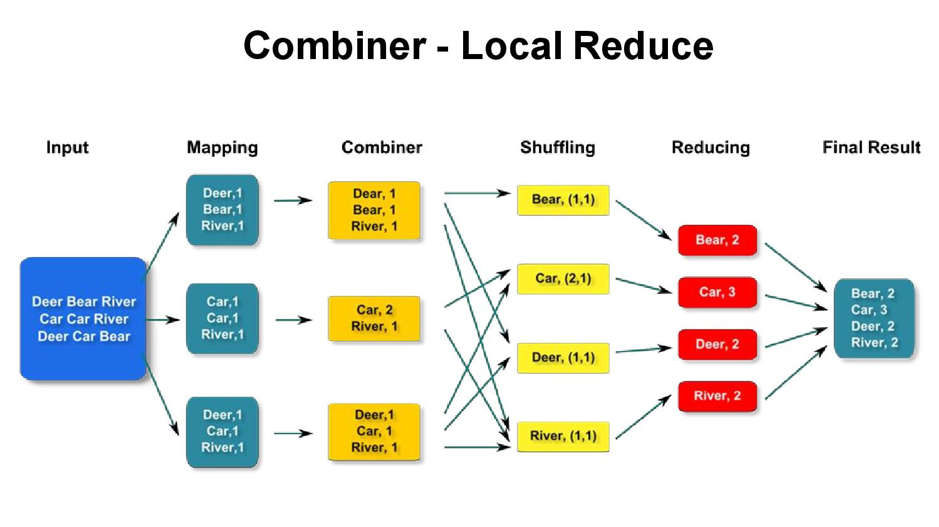
# 1. Hadoop Combiner概念解析
## 1.1 Combiner的定义和作用
Hadoop Combiner是一种优化技术,它在MapReduce框架中起到了重要的作用。它主要用于对Map阶段输出的中间数据进行局部聚合,以减少数据在网络中的传输量,从而提高MapReduce作业的执行效率。
## 1.2 Combine
Bzip2压缩技术进阶:Hadoop大数据处理中的高级应用
# 1. Bzip2压缩技术概述
## 1.1 Bzip2的起源与功能
Bzip2是一种广泛应用于数据压缩的开源软件工具,最初由Julian Seward开发,其独特的压缩算法基于Burrows-Wheeler变换(BWT)和霍夫曼编码。该技术能够将文件和数据流压缩到较小的体积,便于存储和传输。
## 1.2 Bzip2的特点解析
Bzip2最显著的特点是其压缩率较高,通常能够比传统的ZIP和GZIP格式提供更好的压缩效果。尽管压缩和解压缩速度较慢,但在存储空间宝贵和网络传输成本较高的场合,Bzip2显示了其不可替代的优势。
## 1.3 Bzip2的应用场景
在多种场景中,Bzip2都
【Hadoop集群集成】:LZO压缩技术的集成与最佳实践

# 1. Hadoop集群集成LZO压缩技术概述
随着大数据量的不断增长,对存储和计算资源的需求日益增加,压缩技术在数据处理流程中扮演着越来越重要的角色。LZO(Lempel-Ziv-Oberhumer)压缩技术以其高压缩比、快速压缩与解压的特性,在Hadoop集群中得到广泛应用。本章将概述Hadoop集群集成LZO压缩技术的背景、意义以及
Hadoop中Snappy压缩的深度剖析:提升实时数据处理的算法优化

# 1. Hadoop中的数据压缩技术概述
在大数据环境下,数据压缩技术是优化存储和提升数据处理效率的关键环节。Hadoop,作为一个广泛使用的分布式存储和处理框架,为数据压缩提供了多种支持。在本章中,我们将探讨Hadoop中的数据压缩技术,解释它们如何提高存储效率、降低带宽使用、加快数据传输速度,并减少I/O操作。此外,我们将概述Hadoop内建的压缩编码器以及它们的优缺点,为后续章节深入探讨特定压缩算法
【Hadoop数据压缩】:Gzip算法的局限性与改进方向
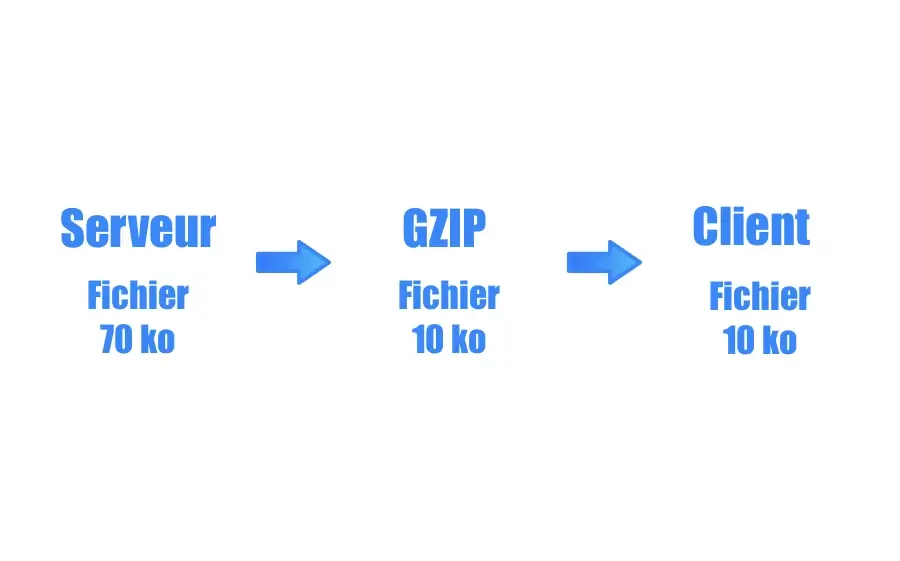
# 1. Hadoop数据压缩概述
随着大数据量的不断增长,数据压缩已成为提升存储效率和传输速度的关键技术之一。Hadoop作为一个分布式系统,其数据压缩功能尤为重要。本章我们将对Hadoop数据压缩进行概述,深入探讨压缩技术在Hadoop中的应用,并简要分析其重要性与影响。
## 1.1 Hadoop数据压缩的必要性
Hadoop集群处理的数据量巨大,有效的数据压缩可以减少存储成本,加快网络传输速度,
Hadoop分块存储读写性能优化:调优与最佳实践指南
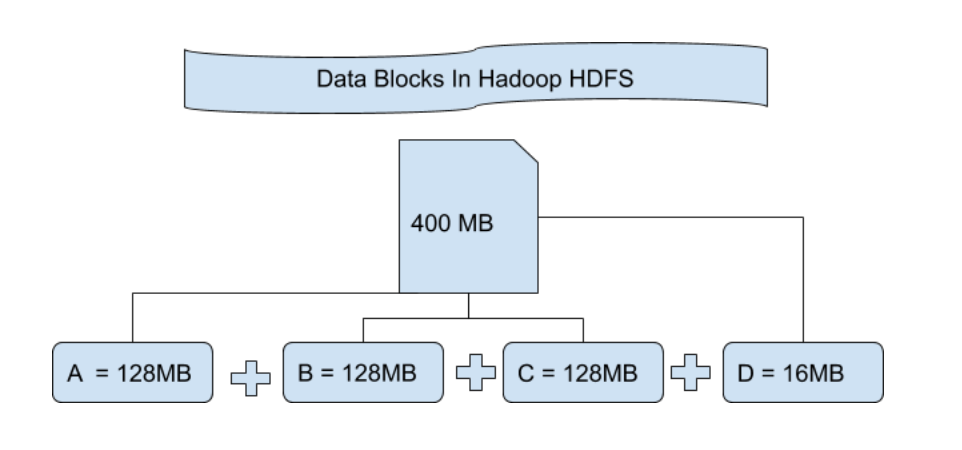
# 1. Hadoop分块存储基础
## 1.1 Hadoop存储结构概述
Hadoop采用分布式存储架构,其中数据被划分为称为“块”的固定大小片段。这种分块存储机制不仅有利于数据的并行处理,也增强了系统的容错能力。块的大小是可以配置的,常见的有64MB和128MB,这直接影响着存储空间的使用效率以及计算任务的分布。
## 1.2 分块存储的工作原理
每个块被复制存储在不同的数
Hadoop压缩技术在大数据分析中的角色:作用解析与影响评估
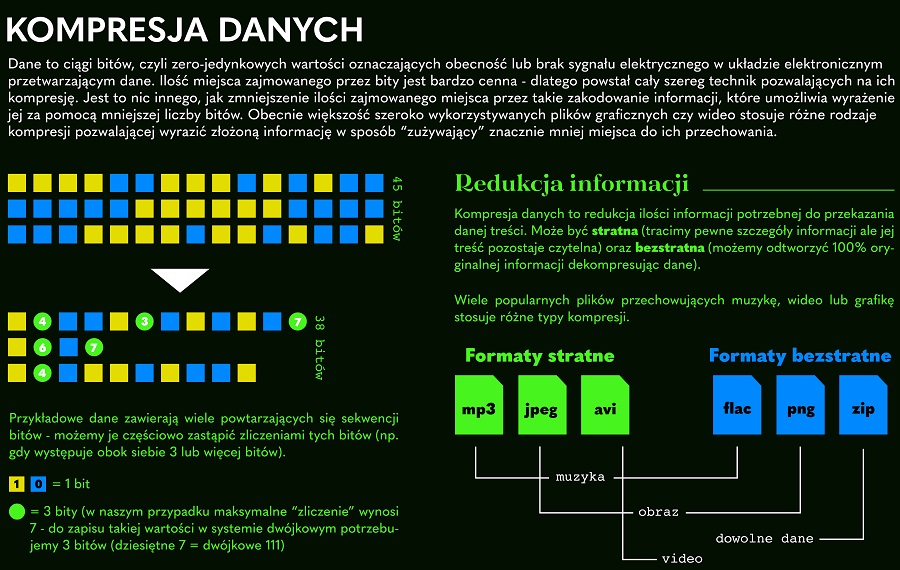
# 1. Hadoop压缩技术概述
在大数据的处理与存储中,压缩技术扮演着至关重要的角色。Hadoop作为一个分布式存储和处理的框架,它能够高效地处理大量数据,而这背后离不开压缩技术的支持。在本章中,我们将简要介绍Hadoop中的压缩技术,并探讨它如何通过减少数据的存储体积和网络
Hadoop块大小与数据本地化:提升MapReduce作业效率的关键

# 1. Hadoop块大小与数据本地化概述
在本章中,我们将揭开Hadoop中块大小设置和数据本地化的神秘面纱。我们会介绍Hadoop如何将文件拆分为固定大小的块以方便管理和计算,以及这些块如何在分布式环境中进行存储。我们将概述块大小如何影响Hadoop集群的性能,并强调数据本地化的重要性——即如何将计算任务尽量调度到包含数据副本的节点上执行,以减少网络传输开销
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )