




实体识别实战:SpaCy从入门到精通,快速提升自然语言处理能力


深入spaCy:用Python进行高效自然语言处理
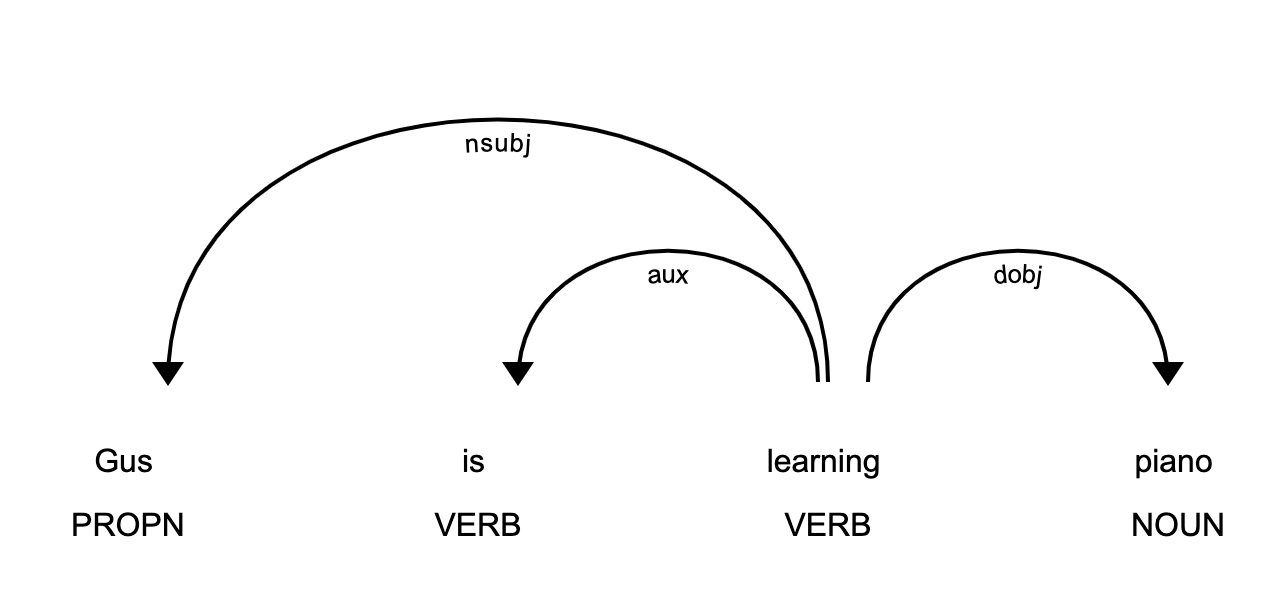
1. 实体识别与自然语言处理概述
自然语言处理(NLP)是计算机科学和人工智能领域的一个重要分支,旨在使计算机能够理解、解释和操纵人类语言。实体识别作为NLP的核心任务之一,专注于从文本中自动识别出具有特定意义的实体,如人名、地名、组织机构名等。本章将概述NLP的基本概念和实体识别的重要性,为后续章节中详细介绍SpaCy框架下的实体识别技术打下基础。
实体识别对于信息提取、知识图谱构建、问答系统等应用至关重要。借助先进的算法和模型,实体识别技术能够将非结构化的文本数据转化为结构化的信息资源,极大提高了文本分析的效率和准确度。在自然语言处理的进化过程中,实体识别的应用领域不断扩大,从传统的搜索引擎优化到现代的语音助手,都离不开这一关键技术的支持。
本章内容不仅对实体识别与自然语言处理的理论基础进行梳理,还将展望实体识别技术的发展趋势,为读者提供对整个NLP领域的宏观认识。
2. SpaCy快速入门
在深度学习和自然语言处理(NLP)领域,SpaCy已成为一个不可或缺的工具。由于其高效的性能和丰富的功能,SpaCy特别适合用于文本处理任务,尤其是实体识别。本章旨在指导读者快速掌握SpaCy的基础知识,并通过实践示例来演示如何使用SpaCy进行文本分析。
2.1 SpaCy的基本安装与配置
2.1.1 安装SpaCy及其依赖项
为了充分利用SpaCy的功能,您需要安装SpaCy库以及下载相应的语言模型。推荐使用pip进行安装:
- pip install spacy
在安装SpaCy后,需要下载一个预训练的语言模型。比如,如果您需要使用英文模型,可以执行以下命令:
- python -m spacy download en_core_web_sm
2.1.2 环境配置和验证
安装完成后,我们建议创建一个新的Python环境,并在其中安装SpaCy。这样做可以避免潜在的版本冲突和依赖问题。接下来,我们将通过一个简单的脚本来验证SpaCy是否正确安装并可正常工作。
- import spacy
- # 加载英文小模型
- nlp = spacy.load('en_core_web_sm')
- # 创建一个文档对象
- doc = nlp("Hello world!")
- # 打印文档
- print([(token.text, token.pos_) for token in doc])
执行上述脚本后,如果一切顺利,您应该在控制台看到输出的文本及它们对应的部分。
2.2 SpaCy的词汇表和文档处理
2.2.1 词汇表的结构和特性
SpaCy的词汇表(Vocab)存储了模型中所有词汇的信息,这些信息包括词形(lemma)、词性(POS)标签、依存关系标签等。词汇表的特性包括:
- 词汇项(
Lexeme):词汇表中每个单词的条目。 - 意义不变性:词汇表通过词汇项和特征来维护单词的不同意义。
2.2.2 文档创建和预处理
文档(Doc)是SpaCy处理文本的基本单位。它由一系列令牌(Token)组成,并保持了文本的原始顺序。在创建文档时,SpaCy会自动进行多种预处理,比如分词(tokenization)、词形还原(lemmatization)和句法分析等。
以下是一个创建文档并进行预处理的示例:
- # 创建一个文档
- doc = nlp("SpaCy processes entire documents as a sequence of tokens.")
- # 遍历文档中的每个令牌
- for token in doc:
- print(f"{token.text:{10}} {token.pos_:{6}}")
这段代码创建了一个包含预处理令牌的文档,并打印出每个令牌的文本及其词性标签。
2.3 初识SpaCy的实体识别功能
2.3.1 实体识别的原理
实体识别(Named Entity Recognition, NER)是NLP中一项识别文本中具有特定意义实体(人名、地点、组织名等)的任务。SpaCy的实体识别功能主要依赖于其内置的预训练模型,这些模型使用了深度学习技术来预测文本中实体的类别和边界。
2.3.2 实体识别的基本操作示例
下面我们将通过一个示例来展示如何使用SpaCy进行实体识别。
- import spacy
- # 加载英文小模型
- nlp = spacy.load('en_core_web_sm')
- # 创建一个文档
- doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
- # 遍历文档中的实体,并打印实体文本和标签
- for ent in doc.ents:
- print(f"{ent.text:{15}} {ent.label_:{5}}")
这个脚本将打印出每个检测到的实体的文本和它们的类别标签,例如:
- Apple ORG
- U.K. GPE
- $1 billion MONEY
本章节介绍了SpaCy的基础安装、词汇表和文档处理,以及如何执行实体识别等核心操作。接下来的章节,我们将深入探讨SpaCy的更多高级功能和应用案例。
3. SpaCy的深入学习与实践
3.1 SpaCy的命名实体识别模型
3.1.1 命名实体识别的原理和方法
命名实体识别(Named Entity Recognition, NER)是自然语言处理中的一个核心任务,旨在从文本中识别出具有特定意义的实体,如人名、地名、机构名、日期、时

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
Cygwin系统监控指南:性能监控与资源管理的7大要点
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【T-Box能源管理】:智能化节电解决方案详解
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【精准测试】:确保分层数据流图准确性的完整测试方法
【内存分配调试术】:使用malloc钩子追踪与解决内存问题


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















