堆的基本概念和操作原理
发布时间: 2024-05-02 06:08:28 阅读量: 69 订阅数: 29 
# 1. 堆的基本概念**
堆是一种特殊的完全二叉树数据结构,具有以下特性:
* **完全二叉树:**除最后一层外,所有层都完全填充,最后一层节点尽可能地靠左对齐。
* **最大堆:**每个节点的值都大于或等于其子节点的值。
* **最小堆:**每个节点的值都小于或等于其子节点的值。
# 2. 堆的理论基础
### 2.1 堆的数据结构和特性
#### 2.1.1 完全二叉树的定义和性质
**定义:**
完全二叉树是一种特殊的二叉树,它满足以下条件:
* 除了最后一层之外,每一层都被完全填满。
* 最后一层的节点从左到右尽可能地向左对齐。
**性质:**
* 一棵高度为 h 的完全二叉树最多有 2^h - 1 个节点。
* 对于任何节点 i,其左子节点为 2i,右子节点为 2i + 1。
* 对于任何节点 i,其父节点为 ⌊i/2⌋。
#### 2.1.2 堆的定义和性质
**定义:**
堆是一种完全二叉树,它满足以下性质:
* **最大堆:**对于任何节点 i,其值大于或等于其左右子节点的值。
* **最小堆:**对于任何节点 i,其值小于或等于其左右子节点的值。
**性质:**
* 根节点是堆中最大(或最小)的值。
* 对于任何节点 i,其左子节点和右子节点的值都小于或等于 i 的值(最大堆)或大于或等于 i 的值(最小堆)。
### 2.2 堆的排序算法
#### 2.2.1 堆排序的原理和过程
堆排序是一种基于堆的数据结构进行排序的算法。其原理是:
1. 将待排序的数组构建成一个最大堆。
2. 将堆顶元素与最后一个元素交换,然后将堆顶元素弹出。
3. 重新调整剩余的堆,使其仍然满足堆的性质。
4. 重复步骤 2 和 3,直到堆为空。
**代码块:**
```python
def heap_sort(arr):
# 构建最大堆
for i in range(len(arr) // 2 - 1, -1, -1):
heapify(arr, i, len(arr))
# 排序
for i in range(len(arr) - 1, 0, -1):
arr[0], arr[i] = arr[i], arr[0]
heapify(arr, 0, i)
def heapify(arr, i, n):
# 获取左子节点和右子节点的索引
left = 2 * i + 1
right = 2 * i + 2
# 找到最大(或最小)的子节点
largest = i
if left < n and arr[left] > arr[i]:
largest = left
if right < n and arr[right] > arr[largest]:
largest = right
# 如果最大子节点不是根节点,则交换
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, largest, n)
```
**代码逻辑分析:**
* `heapify()` 函数将子树以根节点 `i` 为根重新调整为堆。
* `heap_sort()` 函数通过依次将堆顶元素与最后一个元素交换并重新调整堆,完成排序。
#### 2.2.2 堆排序的复杂度分析
堆排序的时间复杂度为 O(n log n),其中 n 是待排序数组的长度。
* 构建堆的时间复杂度为 O(n)。
* 排序过程中,每次交换堆顶元素和最后一个元素并重新调整堆的时间复杂度为 O(log n)。
* 因此,总的时间复杂度为 O(n) + O(n log n) = O(n log n)。
# 3.1 堆的实现方法
堆的数据结构可以通过数组或链表来实现。不同的实现方式各有优缺点,具体选择取决于实际应用场景。
### 3.1.1 数组实现
数组实现的堆结构简单直观,易于理解和操作。它将堆中的元素存储在一个连续的数组中,其中每个元素都对应堆中的一个节点。
**优点:**
- 访问速度快,可以直接通过索引访问堆中的元素。
- 空间利用率高,不需要额外的指针或引用来维护节点之间的关系。
**缺点:**
- 插入和删除操作需要移动大量元素,时间复杂度为 O(n)。
- 难以动态调整堆的大小,需要预先分配足够的空间。
**代码示例:**
```python
class Heap:
def __init__(self, arr):
self.heap = arr
self.heap_size = len(arr)
def insert(self, value):
self.heap.append(value)
self.heap_size += 1
self._heapify_up(self.heap_size - 1)
def delete(self, index):
if index >= self.heap_size:
return
self.heap[index] = self.heap[self.heap_size - 1]
self.heap_size -= 1
self._heapify_down(index)
def _heapify_up(self, index):
while index > 0:
parent_index = (index - 1) // 2
if self.heap[index] < self.heap[parent_index]:
self.heap[index], self.heap[parent_index] = self.heap[parent_index], self.heap[index]
index = parent_index
def _heapify_down(self, index):
while index < self.heap_size:
left_index = 2 * index + 1
right_index = 2 * index + 2
min_index = index
if left_index < self.heap_size and self.heap[left_index] < self.heap[min_index]:
min_index = left_index
if right_index < self.heap_size and self.heap[right_index] < self.heap[min_index]:
min_index = right_index
if min_index != index:
self.heap[index], self.heap[min_index] = self.heap[min_index], self.heap[index]
index = min_index
```
### 3.1.2 链表实现
链表实现的堆结构更加灵活,可以动态调整堆的大小,并且插入和删除操作的时间复杂度为 O(log n)。但是,链表实现的访问速度较慢,因为需要通过指针逐个遍历节点。
**优点:**
- 可以动态调整堆的大小,无需预先分配空间。
- 插入和删除操作的时间复杂度为 O(log n)。
**缺点:**
- 访问速度较慢,需要通过指针逐个遍历节点。
- 空间开销较大,需要额外的指针或引用来维护节点之间的关系。
**代码示例:**
```python
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
class Heap:
def __init__(self):
self.root = None
self.size = 0
def insert(self, value):
new_node = Node(value)
if self.root is None:
self.root = new_node
else:
self._insert_helper(new_node, self.root)
self.size += 1
def delete(self, value):
if self.root is None:
return
node_to_delete = self._find_node(value, self.root)
if node_to_delete is None:
return
self._delete_helper(node_to_delete)
self.size -= 1
def _insert_helper(self, new_node, current_node):
if new_node.value < current_node.value:
if current_node.left is None:
current_node.left = new_node
else:
self._insert_helper(new_node, current_node.left)
else:
if current_node.right is None:
current_node.right = new_node
else:
self._insert_helper(new_node, current_node.right)
def _delete_helper(self, node_to_delete):
if node_to_delete.left is None and node_to_delete.right is None:
if node_to_delete == self.root:
self.root = None
else:
parent_node = self._find_parent(node_to_delete, self.root)
if parent_node.left == node_to_delete:
parent_node.left = None
else:
parent_node.right = None
elif node_to_delete.left is None:
if node_to_delete == self.root:
self.root = node_to_delete.right
else:
parent_node = self._find_parent(node_to_delete, self.root)
if parent_node.left == node_to_delete:
parent_node.left = node_to_delete.right
else:
parent_node.right = node_to_delete.right
elif node_to_delete.right is None:
if node_to_delete == self.root:
self.root = node_to_delete.left
else:
parent_node = self._find_parent(node_to_delete, self.root)
if parent_node.left == node_to_delete:
parent_node.left = node_to_delete.left
else:
parent_node.right = node_to_delete.left
else:
successor_node = self._find_successor(node_to_delete.right)
node_to_delete.value = successor_node.value
self._delete_helper(successor_node)
def _find_node(self, value, current_node):
if current_node is None:
return None
if current_node.value == value:
return current_node
elif value < current_node.value:
return self._find_node(value, current_node.left)
else:
return self._find_node(value, current_node.right)
def _find_parent(self, node_to_delete, current_node):
if current_node.left == node_to_delete or current_node.right == node_to_delete:
return current_node
elif node_to_delete.value < current_node.value:
return self._find_parent(node_to_delete, current_node.left)
else:
return self._find_parent(node_to_delete, current_node.right)
def _find_successor(self, current_node):
if current_node.left is None:
return current_node
else:
return self._find_successor(current_node.left)
```
# 4. 堆的优化与扩展
### 4.1 堆的优化算法
#### 4.1.1 斐波那契堆
斐波那契堆是一种改进的二叉堆,它通过引入潜在值的概念来优化堆的操作。潜在值是指节点的实际值与它子树中最大子节点值的差值。
斐波那契堆的优化算法主要体现在以下方面:
- **合并操作优化:**斐波那契堆使用一个指针数组来存储不同潜在值的根节点,当合并两个堆时,只需要比较指针数组中的根节点,将潜在值较大的根节点作为新堆的根节点,从而减少合并操作的复杂度。
- **删除最小值操作优化:**斐波那契堆使用一个双向循环链表来存储根节点,当删除最小值时,只需要从链表中删除该根节点,并更新指针数组,从而减少删除最小值操作的复杂度。
#### 4.1.2 二项堆
二项堆是一种基于二项树的数据结构,它具有以下特点:
- **每个节点的度数至多为 1:**二项树的每个节点最多有两个子节点,称为左子节点和右子节点。
- **每个节点的子树高度相同:**二项树的每个节点的左子树和右子树的高度相同。
二项堆的优化算法主要体现在以下方面:
- **合并操作优化:**二项堆的合并操作通过将两个二项堆的根节点进行比较,将度数较小的根节点作为子节点连接到度数较大的根节点上,从而减少合并操作的复杂度。
- **删除最小值操作优化:**二项堆的删除最小值操作通过将最小值的子树分解为一系列二项树,然后将这些二项树合并到堆中,从而减少删除最小值操作的复杂度。
### 4.2 堆的扩展应用
#### 4.2.1 离散事件仿真
离散事件仿真是一种计算机模拟技术,它用于模拟离散时间发生的事件序列。堆在离散事件仿真中可以用于以下方面:
- **事件队列管理:**堆可以用于管理事件队列,其中事件按发生时间排序。
- **优先级调度:**堆可以用于对事件进行优先级调度,从而确保高优先级的事件优先处理。
#### 4.2.2 图论算法
堆在图论算法中可以用于以下方面:
- **最短路径算法:**堆可以用于实现Dijkstra算法和A*算法,这些算法用于寻找图中两点之间的最短路径。
- **最小生成树算法:**堆可以用于实现Prim算法和Kruskal算法,这些算法用于寻找图中的最小生成树。
# 5.1 使用堆解决实际问题
堆是一种高效的数据结构,可用于解决各种实际问题。以下是一些常见的应用场景:
### 5.1.1 寻找中位数
中位数是数据集中的中间值。使用堆可以高效地找到中位数,即使数据集非常大。
**算法步骤:**
1. 创建一个最小堆和一个最大堆。
2. 将数据集中的元素依次插入到两个堆中。
3. 如果数据集的元素个数为奇数,则中位数为最小堆的堆顶元素。
4. 如果数据集的元素个数为偶数,则中位数为最小堆的堆顶元素和最大堆的堆顶元素的平均值。
**代码示例(Python):**
```python
import heapq
def find_median(nums):
min_heap = [] # 最小堆
max_heap = [] # 最大堆
for num in nums:
if len(min_heap) == len(max_heap):
heapq.heappush(max_heap, -heapq.heappushpop(min_heap, num))
else:
heapq.heappush(min_heap, -heapq.heappushpop(max_heap, -num))
if len(min_heap) == len(max_heap):
return (min_heap[0] - max_heap[0]) / 2
else:
return -max_heap[0]
```
### 5.1.2 求解哈夫曼编码
哈夫曼编码是一种无损数据压缩算法,它使用变长编码来表示数据。使用堆可以高效地求解哈夫曼编码。
**算法步骤:**
1. 创建一个最小堆,其中每个节点代表一个字符及其频率。
2. 重复以下步骤,直到堆中只剩下一个节点:
- 从堆中取出频率最小的两个节点。
- 创建一个新的节点,其频率为这两个节点频率之和,其左右子节点分别为这两个节点。
- 将新节点插入堆中。
3. 堆中剩下的唯一节点就是哈夫曼树的根节点。
**代码示例(C++):**
```cpp
#include <queue>
#include <map>
using namespace std;
class HuffmanNode {
public:
char character;
int frequency;
HuffmanNode *left, *right;
HuffmanNode(char character, int frequency) {
this->character = character;
this->frequency = frequency;
left = right = nullptr;
}
};
struct compare {
bool operator()(HuffmanNode *a, HuffmanNode *b) {
return a->frequency > b->frequency;
}
};
HuffmanNode* buildHuffmanTree(map<char, int>& frequencies) {
priority_queue<HuffmanNode*, vector<HuffmanNode*>, compare> min_heap;
for (auto& entry : frequencies) {
min_heap.push(new HuffmanNode(entry.first, entry.second));
}
while (min_heap.size() > 1) {
HuffmanNode *left = min_heap.top();
min_heap.pop();
HuffmanNode *right = min_heap.top();
min_heap.pop();
HuffmanNode *parent = new HuffmanNode('\0', left->frequency + right->frequency);
parent->left = left;
parent->right = right;
min_heap.push(parent);
}
return min_heap.top();
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
本专栏深入探讨了堆的数据结构,从基本概念和操作原理到各种应用场景。它涵盖了堆排序算法、优先队列、Top K 问题、滑动窗口最大值问题、连续中值问题等应用。此外,它还比较了堆与快速排序和二叉搜索树,分析了堆的构建方法和调整方法。专栏还介绍了堆在操作系统、定时任务调度和数据流中位数问题中的应用。它还探讨了堆的扩展应用,如外部排序算法和最小生成树算法。通过深入的分析和示例,本专栏旨在为读者提供对堆及其广泛应用的全面理解。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言交互式数据探索】:DataTables包的实现方法与实战演练

# 1. R语言交互式数据探索简介
在当今数据驱动的世界中,R语言凭借其强大的数据处理和可视化能力,已经成为数据科学家和分析师的重要工具。本章将介绍R语言中用于交互式数据探索的工具,其中重点会放在DataTables包上,它提供了一种直观且高效的方式来查看和操作数据框(data frames)。我们会
【R语言高级用户必读】:rbokeh包参数设置与优化指南
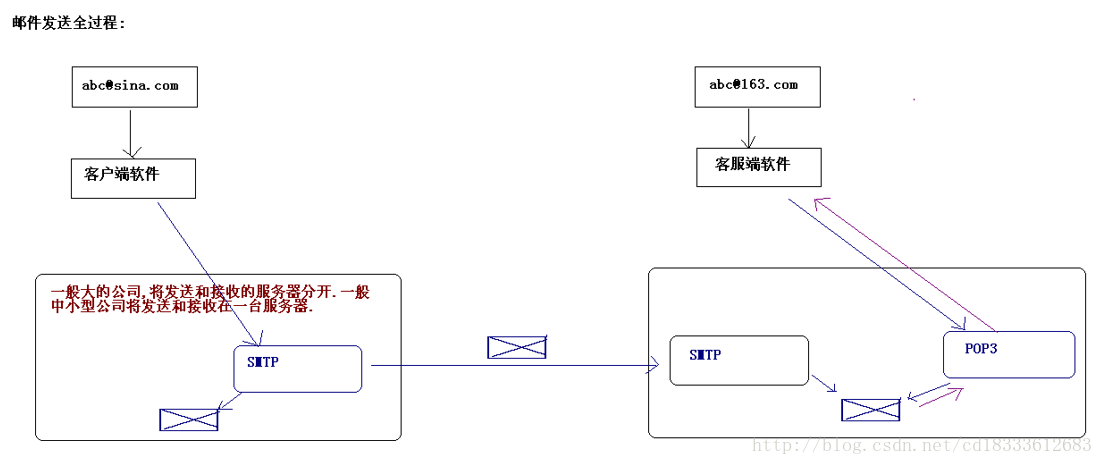
# 1. R语言和rbokeh包概述
## 1.1 R语言简介
R语言作为一种免费、开源的编程语言和软件环境,以其强大的统计分析和图形表现能力被广泛应用于数据科学领域。它的语法简洁,拥有丰富的第三方包,支持各种复杂的数据操作、统计分析和图形绘制,使得数据可视化更加直观和高效。
## 1.2 rbokeh包的介绍
rbokeh包是R语言中一个相对较新的可视化工具,它为R用户提供了一个与Python中Bokeh库类似的
【R语言数据转换专家】:reshape2包带你深入数据重塑的奥秘

# 1. R语言数据重塑基础
在数据分析和处理的领域中,数据重塑是一项基础但至关重要的技能。本章我们将揭开数据重塑的神秘面纱,首先理解R语言中数据重塑的概念和应用场景,然后通过实例演示R语言提供的基本工具和函数,帮助你掌握在R环境中实现数据结构转换的基础知识。我们将从简单的向量操作开始,逐步过渡到数据框(data.
Highcharter包创新案例分析:R语言中的数据可视化,新视角!

# 1. Highcharter包在数据可视化中的地位
数据可视化是将复杂的数据转化为可直观理解的图形,使信息更易于用户消化和理解。Highcharter作为R语言的一个包,已经成为数据科学家和分析师展示数据、进行故事叙述的重要工具。借助Highcharter的高级定制
【R语言热力图解读实战】:复杂热力图结果的深度解读案例
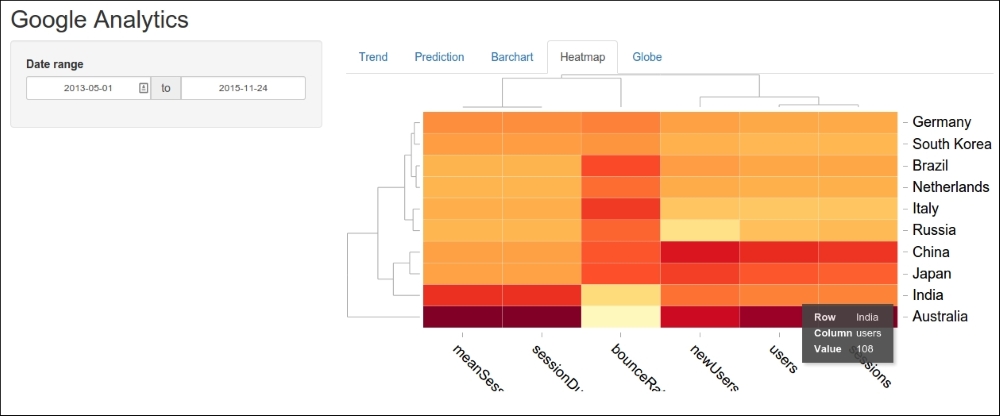
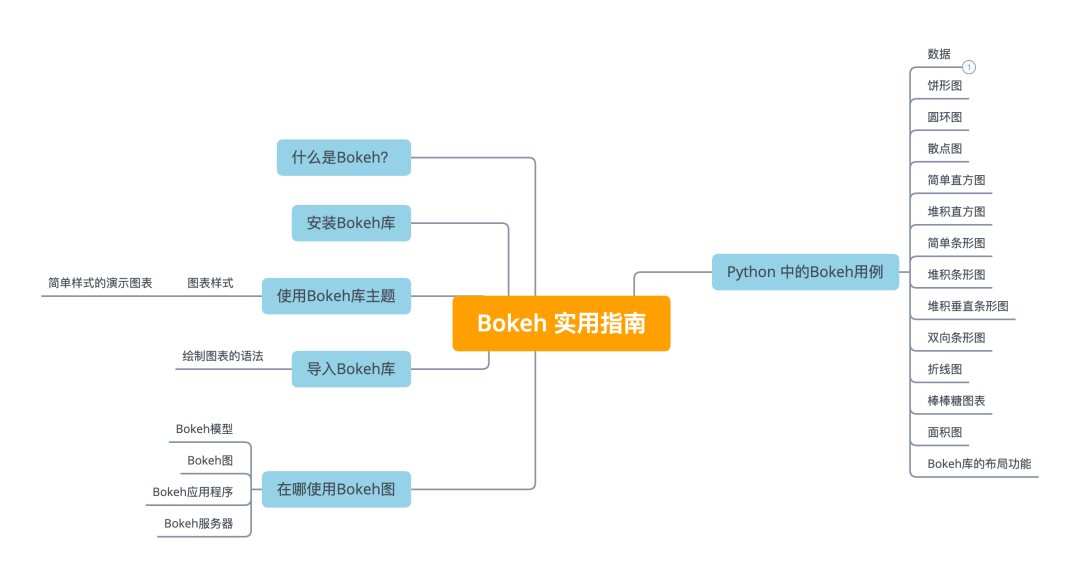
# 1. R语言热力图概述
热力图是数据可视化领域中一种重要的图形化工具,广泛用于展示数据矩阵中的数值变化和模式。在R语言中,热力图以其灵活的定制性、强大的功能和出色的图形表现力,成为数据分析与可视化的重要手段。本章将简要介绍热力图在R语言中的应用背景与基础知识,为读者后续深入学习与实践奠定基础。
热力图不仅可以直观展示数据的热点分布,还可以通过颜色的深浅变化来反映数值的大小或频率的高低,
R语言在遗传学研究中的应用:基因组数据分析的核心技术

# 1. R语言概述及其在遗传学研究中的重要性
## 1.1 R语言的起源和特点
R语言是一种专门用于统计分析和图形表示的编程语言。它起源于1993年,由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建。R语言是S语言的一个实现,具有强大的计算能力和灵活的图形表现力,是进行数据分析、统计计算和图形表示的理想工具。R语言的开源特性使得它在全球范围内拥有庞大的社区支持,各种先
【R语言与Hadoop】:集成指南,让大数据分析触手可及

# 1. R语言与Hadoop集成概述
## 1.1 R语言与Hadoop集成的背景
在信息技术领域,尤其是在大数据时代,R语言和Hadoop的集成应运而生,为数据分析领域提供了强大的工具。R语言作为一种强大的统计计算和图形处理工具,其在数据分析领域具有广泛的应用。而Hadoop作为一个开源框架,允许在普通的
【R语言图表演示】:visNetwork包,揭示复杂关系网的秘密

# 1. R语言与visNetwork包简介
在现代数据分析领域中,R语言凭借其强大的统计分析和数据可视化功能,成为了一款广受欢迎的编程语言。特别是在处理网络数据可视化方面,R语言通过一系列专用的包来实现复杂的网络结构分析和展示。
visNetwork包就是这样一个专注于创建交互式网络图的R包,它通过简洁的函数和丰富
【R语言网络图数据过滤】:使用networkD3进行精确筛选的秘诀
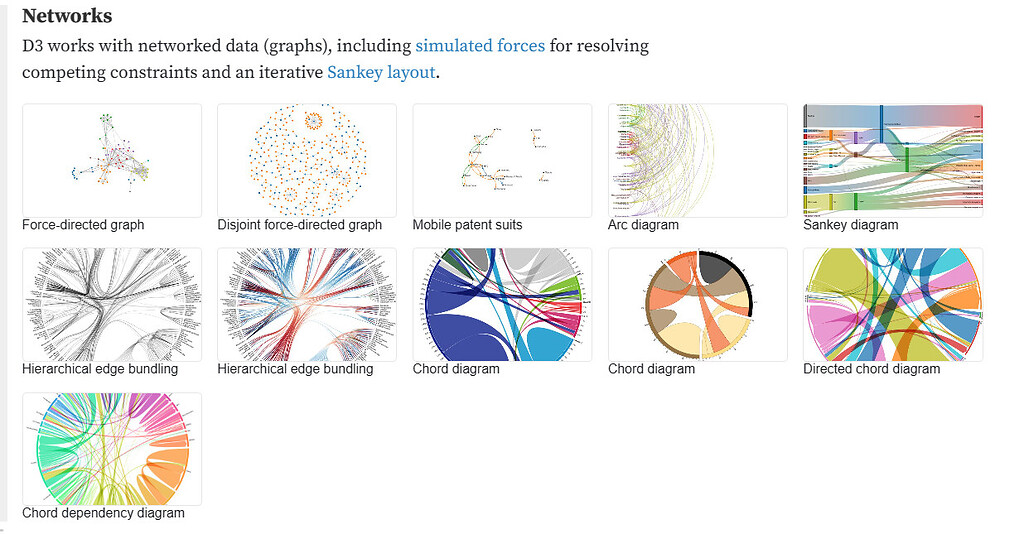
# 1. R语言与网络图分析的交汇
## R语言与网络图分析的关系
R语言作为数据科学领域的强语言,其强大的数据处理和统计分析能力,使其在研究网络图分析上显得尤为重要。网络图分析作为一种复杂数据关系的可视化表示方式,不仅可以揭示出数据之间的关系,还可以通过交互性提供更直观的分析体验。通过将R语言与网络图分析相结合,数据分析师能够更
【大数据环境】:R语言与dygraphs包在大数据分析中的实战演练

# 1. R语言在大数据环境中的地位与作用
随着数据量的指数级增长,大数据已经成为企业与研究机构决策制定不可或缺的组成部分。在这个背景下,R语言凭借其在统计分析、数据处理和图形表示方面的独特优势,在大数据领域中扮演了越来越重要的角色。
## 1.1 R语言的发展背景
R语言最初由罗伯特·金特门(Robert Gentleman)和罗斯·伊哈卡(Ross Ihaka)在19
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )