【GAN进阶应用】:图像合成与风格转换的专家指南
发布时间: 2024-09-03 14:47:32 阅读量: 125 订阅数: 57 

StarGAN v2:多领域的不同图像合成

# 1. 生成对抗网络(GAN)基础
## 1.1 GAN的起源与定义
生成对抗网络(GAN)由Ian Goodfellow在2014年提出,是一种创新的深度学习模型,它由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是产生尽可能接近真实数据分布的假数据,而判别器的任务是识别输入数据是真实的还是由生成器生成的假数据。二者通过对抗性的训练过程相互促进,最终达到一个平衡点,生成器能生成高质量的假数据,而判别器无法有效区分真假数据。
## 1.2 GAN的数学基础
GAN的训练过程可以看作是一个最小-最大问题(min-max game)。在这个过程中,生成器\( G \)和判别器\( D \)进行如下优化:
\[
\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1-D(G(z)))]
\]
其中,\( p_{data} \)是真实数据的分布,\( p_z \)是潜在空间\( z \)的分布,\( D(x) \)表示判别器输出\( x \)为真实数据的概率。目标函数是生成器的损失函数,同时是判别器的收益函数。训练过程中,判别器和生成器交替优化,直到达到纳什均衡状态。
## 1.3 GAN的应用前景
自GAN提出以来,它的应用范围已经扩展到图像和视频的生成、风格转换、图像增强、数据增强等多个领域。尤其在游戏产业、电影特效、艺术创作中,GAN带来了前所未有的创新。此外,GAN在医疗、安全验证等实际应用中也展现了巨大的潜力,是未来人工智能研究的重要方向之一。
# 2. 图像合成技术详解
## 2.1 图像合成的理论基础
### 2.1.1 GAN的工作原理
生成对抗网络(GAN)由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器负责创造看似真实的图像,而判别器则努力区分生成的图像和真实的图像。在训练过程中,生成器不断学习判别器反馈的错误信息,以改进其输出。
```python
# 伪代码展示GAN的训练过程
# 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 训练循环
for epoch in range(total_epochs):
for batch in dataloader:
# 生成噪声
z = noise(batch_size)
# 生成器产生假图像
fake_images = generator(z)
# 判别器判定真假
real_labels = ones(batch_size)
fake_labels = zeros(batch_size)
real_loss = loss_function(discriminator(real_images), real_labels)
fake_loss = loss_function(discriminator(fake_images), fake_labels)
# 计算判别器损失并更新权重
d_loss = real_loss + fake_loss
discriminator.backward(d_loss)
discriminator.update_weights()
# 生成器尝试欺骗判别器
g_loss = loss_function(discriminator(fake_images), real_labels)
generator.backward(g_loss)
generator.update_weights()
```
### 2.1.2 图像合成的关键技术
GAN的图像合成依赖于深度学习的多个关键领域,如卷积神经网络(CNN)、反卷积网络(Deconvolutional Networks)、批量归一化(Batch Normalization)等。这些技术共同作用,增强了模型的表现力和泛化能力。
## 2.2 图像合成的实践技巧
### 2.2.1 数据集的准备与预处理
构建高质量数据集是图像合成的基础。这涉及到数据的采集、清洗、标注,以及后续的数据增强,以扩大数据集的多样性。数据预处理过程中,归一化、标准化操作能有效提升模型训练速度和收敛性。
```python
from sklearn.preprocessing import MinMaxScaler
# 读取图像数据集
images = load_images("dataset_directory")
# 归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
images_normalized = scaler.fit_transform(images.reshape(-1, 1))
# 数据增强
augmented_images = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1
).flow(images_normalized)
```
### 2.2.2 模型的选择与训练策略
选择合适的GAN模型架构,如DCGAN、Pix2Pix、CycleGAN等,对于特定任务至关重要。训练策略包括学习率调整、批大小选择、损失函数调整等,这些因素共同影响着训练的稳定性和生成图像的质量。
```mermaid
graph LR
A[开始训练] --> B[选择GAN架构]
B --> C[设置超参数]
C --> D[选择优化器]
D --> E[逐步训练]
E --> F[监控loss]
F --> G{损失下降?}
G -->|是| H[模型保存]
G -->|否| I[调整策略]
I --> E
```
### 2.2.3 合成图像的质量评估与优化
合成图像的评估是图像合成中的难点之一。通常采用主观评估和客观评估两种方式,其中客观评估可能包括Inception Score(IS)、Fréchet Inception Distance(FID)等指标。针对评估结果,可以通过调整模型结构或训练策略进行优化。
```python
# 使用FID评估模型生成的图像质量
from fid_score import calculate_activation_statistics
from scipy import linalg
def fid(real, fake):
mu_real, sigma_real = calculate_activation_statistics(real)
mu_fake, sigma_fake = calculate_activation_statistics(fake)
fid_value = linalg.sqrt(linalg.norm(mu_real - mu_fake) ** 2 +
linalg.trace(sigma_real + sigma_fake))
return fid_value
real_images_features = ...
fake_images_features = ...
fid_score = fid(real_images_fea
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了生成对抗网络(GAN)的训练方法,涵盖了从入门指南到高级技巧的各个方面。专栏内容包括:
* GAN训练初探:入门者指南
* 揭秘GAN:基础知识与实践技巧
* GAN训练技巧:稳定性和收敛性的高级策略
* GAN损失函数:关键组件的深入分析
* GAN进阶应用:图像合成与风格转换的专家指南
* 模式崩溃问题:原因、影响和解决方案
* GAN训练优化:学习率调整和批归一化的终极技巧
* GAN架构选择:定制最佳GAN
* GAN实战:数据增强中的应用技巧
* GAN生成图像质量评估:指标和方法
* GAN高级话题:条件GAN和序列生成
* GAN训练深度分析:对抗损失与感知损失
* GAN与深度学习:网络结构对性能的影响
* GAN训练实践:数据集准备和预处理
* GAN故障排除:训练过程中常见问题的解决方案
* GAN调参秘籍:优化参数以提升生成质量
* GAN与自然语言处理:文本生成的挑战和突破
* GAN在三维数据生成中的前沿应用
* GAN训练案例研究:从医疗影像到艺术创作
* GAN对抗性学习:防御GAN生成虚假信息的策略
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度剖析Renren Security:功能模块背后的架构秘密

# 摘要
Renren Security是一个全面的安全框架,旨在为Web应用提供强大的安全保护。本文全面介绍了Renren Security的核心架构、设计理念、关键模块、集成方式、实战应用以及高级特性。重点分析了认证授权机制、过滤器链设计、安全拦截器的运作原理和集成方法。通过对真实案例的深入剖析,本文展示了Renren Security在实际应用中的效能,并探讨了性能优化和安全监
电力系统稳定性分析:PSCAD仿真中的IEEE 30节点案例解析
# 摘要
本文详细探讨了电力系统稳定性及其在仿真环境中的应用,特别是利用PSCAD仿真工具对IEEE 30节点系统进行建模和分析。文章首先界定了电力系统稳定性的重要性并概述了仿真技术,然后深入分析了IEEE 30节点系统的结构、参数及稳定性要求。在介绍了PSCAD的功能和操作后,本文通过案例展示了如何在PSCAD中设置和运行IEEE 30节点模型,进行稳定性分析,并基于理论对仿真结果进行了详细分析
Infovision iPark高可用性部署:专家传授服务不间断策略
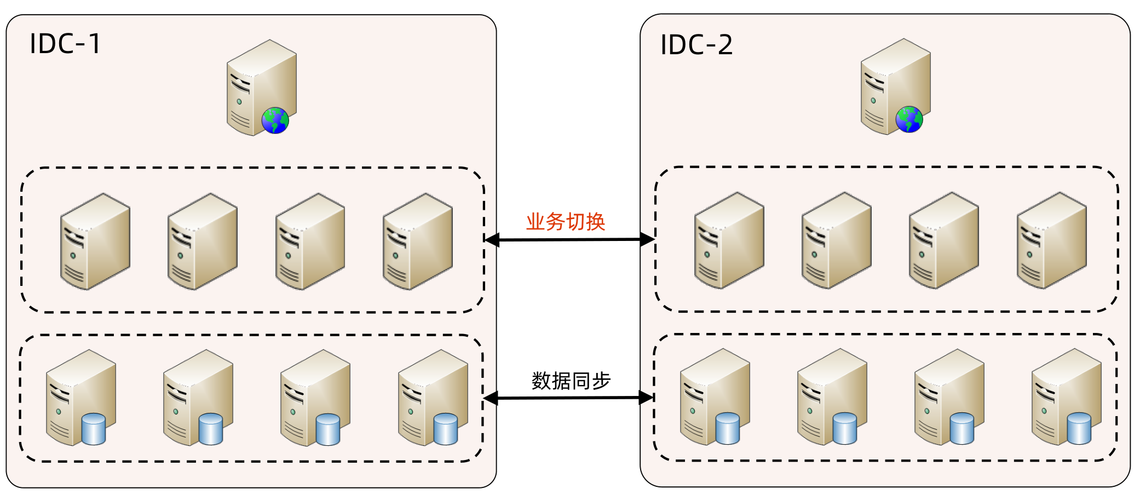
# 摘要
Infovision iPark作为一款智能停车系统解决方案,以其高可用性的设计,能够有效应对不同行业特别是金融、医疗及政府公共服务行业的业务连续性需求。本文首先介绍了Infovision iPark的基础架构和高可用性理论基础,包括高可用性的定义、核心价值及设计原则。其次,详细阐述了Infovision iPark在实际部署中的高可用性实践,包括环境配
USCAR38供应链管理:平衡质量与交付的7个技巧

# 摘要
供应链管理作为确保产品从原材料到终端用户高效流动的复杂过程,其核心在于平衡质量与交付速度。USCAR38的供应链管理概述了供应链管理的理论基础和实践技巧,同时着重于质量与交付之间的平衡挑战。本文深入探讨了供应链流程的优化、风险应对策略以及信息技术和自动化技术的应用。通过案例研究,文章分析了在实践中平衡质量与交付的成功与失败经验,并对供应链管理的未来发展趋
组合数学与算法设计:卢开澄第四版60页的精髓解析
# 摘要
本文系统地探讨了组合数学与算法设计的基本原理和方法。首先概述了算法设计的核心概念,随后对算法分析的基础进行了详细讨论,包括时间复杂度和空间复杂度的度量,以及渐进符号的使用。第三章深入介绍了组合数学中的基本计数原理和高级技术,如生成函数和容斥原理。第四章转向图论基础,探讨了图的基本性质、遍历算法和最短路径问题的解决方法。第五章重点讲解了动态规划和贪心算法,以及它们在
【Tomcat性能优化实战】:打造高效稳定的Java应用服务器

# 摘要
本文旨在深入分析并实践Tomcat性能优化方法。首先,文章概述了Tomcat的性能优化概览,随后详细解析了Tomcat的工作原理及性能
【BIOS画面定制101】:AMI BIOS初学者的完全指南
# 摘要
本文介绍了AMI BIOS的基础知识、设置、高级优化、界面定制以及故障排除与问题解决等关键方面。首先,概述了BIOS的功能和设置基础,接着深入探讨了性能调整、安全性配置、系统恢复和故障排除等高级设置。文章还讲述了BIOS画面定制的基本原理和实践技巧,包括界面布局调整和BIOS皮肤的更换、设计及优化。最后,详细介绍了BIOS更新、回滚、错误解决和长期维护
易康eCognition自动化流程设计:面向对象分类的优化路径

# 摘要
本文综述了易康eCognition在自动化流程设计方面的应用,并详细探讨了面向对象分类的理论基础、实践方法、案例研究、挑战与机遇以及未来发展趋势。文中从地物分类的概念出发,分析了面向对象分类的原理和精度评估方法。随后,通过实践章节展示如何在不同领域中应用易康eCognition进行流程设计和高级分类技术的实现。案例研究部分提供了城市用地、森林资
【变频器通讯高级诊断策略】:MD800系列故障快速定位与解决之道

# 摘要
本文系统阐述了变频器通讯的原理与功能,深入分析了MD800系列变频器的技术架构,包括其硬件组成、软件架构以及通讯高级功能。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )