Python代码解析的艺术:使用tokenize库深入理解语法树
发布时间: 2024-10-05 14:50:18 阅读量: 51 订阅数: 33 

Python库 | pyNlple-0.3.6.tar.gz

# 1. Python代码解析的艺术
Python代码解析是理解和处理Python源代码的关键技术,它涉及将源代码转换为可被程序处理的数据结构的过程。这一艺术包括分析代码的语法结构,理解其语义含义,并在必要时对代码进行转换或优化。
在本章中,我们将探讨Python代码解析的基础知识,包括它的核心概念、解析工具的使用以及解析过程中可能遇到的挑战和解决方案。首先,我们会介绍代码解析的必要性及其在软件开发中的重要角色。随后,我们将深入探讨解析过程中所涉及的关键技术和方法,它们如何帮助开发者更好地理解代码,并在自动化工具中实现复杂的代码处理任务。
我们将通过具体案例,演示如何使用Python中的内置库和第三方工具来解析代码,以及如何通过解析来增强代码的可维护性和性能。通过本章的学习,读者将获得对Python代码解析艺术的初步理解,并为进一步深入研究打下坚实基础。
# 2. 深入理解tokenize库
## 2.1 tokenize库的基本概念
### 2.1.1 tokenize库的安装和导入
`tokenize` 是Python标准库中的一个模块,它用于将Python代码分解成各个有效的“令牌”(tokens)。这些令牌是代码的最小单元,包括关键字、标识符、字符串、运算符等。
要使用 `tokenize` 库,你不需要安装它,因为它是Python标准库的一部分,直接导入即可使用。下面的代码展示了如何导入 `tokenize` 模块:
```python
import tokenize
```
### 2.1.2 tokenize库的主要功能
`tokenize` 模块的主要功能包括:
- 分析代码并生成令牌。
- 支持不同类型的令牌,如:`NAME`, `NUMBER`, `STRING`, `NEWLINE` 等。
- 支持处理多种编码的源代码。
- 支持从文件中读取代码并进行令牌化,也可以从字符串直接读取。
- 提供令牌生成的迭代器。
## 2.2 tokenize库的使用方法
### 2.2.1 tokenize库的基本使用案例
下面的示例代码将展示如何使用 `tokenize` 库来分解一段Python代码并打印出所有的令牌:
```python
import tokenize
code = """def foo():
print("Hello, World!")
tokens = tokenize.tokenize(code.readline)
for toknum, tokval, _, _, _ in tokens:
print(toknum, tokval)
```
以上代码首先导入了 `tokenize` 模块,然后定义了一段简单的Python代码并将其赋值给 `code` 变量。接着使用 `tokenize.tokenize()` 方法对代码进行分解,返回一个迭代器,我们可以遍历这个迭代器并打印出每个令牌的类型和值。
### 2.2.2 tokenize库的高级使用技巧
`tokenize` 模块还提供了一些高级功能,例如:
- 检测代码中的空白字符、注释。
- 读取和处理来自文件的代码。
- 捕获令牌的行和列信息。
下面的代码展示了如何使用 `tokenize` 来分析文件中的代码并获取令牌的详细位置信息:
```python
import tokenize
with tokenize.open('example.py') as f:
tokens = tokenize.generate_tokens(f.readline)
for toknum, tokval, _, (srow, scol), _, _ in tokens:
print(f"Token type: {tokenize.tok_name[toknum]} at line {srow}, column {scol}")
```
这段代码使用了 `tokenize.open` 函数,它和普通的 `open` 函数类似,但会正确处理文件的编码和行结束符。然后,它使用 `generate_tokens` 函数来生成令牌,并打印出每个令牌的类型、值以及令牌在代码中的位置。
## 2.3 tokenize库的扩展应用
### 2.3.1 tokenize库的自定义token类型
你可以通过继承 `tokenize.TokenInfo` 类来定义自己的令牌类型。这在需要对代码进行自定义分析时非常有用。下面的代码展示了如何定义一个自定义令牌类型并将其应用于 `tokenize` 库:
```python
import tokenize
class CustomToken(tokenize.TokenInfo):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 在这里可以根据需要对令牌信息进行扩展或修改
# 这里你可以编写代码处理或分析自定义令牌
# ...
```
### 2.3.2 tokenize库在代码优化中的应用
在代码优化中,`tokenize` 可以用来检查代码中不高效的模式。例如,它可以用来检测不必要的字符串连接或重复的函数调用。下面是一个简单的示例,展示了如何使用 `tokenize` 来查找不必要的字符串连接:
```python
import tokenize
def find_unnecessary_string_concatenations(tokens):
concat_flags = []
for toknum, tokval, _, _, _ in tokens:
if toknum == tokenize.NAME and tokval == 'str':
concat_flags.append(True)
elif toknum == tokenize.STRING and concat_flags:
concat_flags.pop()
if concat_flags:
print("Possible unnecessary string concatenation detected")
else:
concat_flags = []
# 这里你需要先生成令牌,然后调用上面的函数进行检查
# ...
```
这段代码定义了一个函数 `find_unnecessary_string_concatenations`,它遍历令牌列表,每当检测到字符串变量时,它会暂时记录下来,如果之后再遇到字符串,它会假设这是不必要的字符串连接,并提示检测到这种情况。
请注意,这个方法相对简单,并不能准确判断所有不必要的字符串连接,它只是一个示例。实际应用中,需要对 `tokenize` 库的使用进行更加复杂的分析和设计。
# 3. 深入理解语法树
## 3.1 语法树的基本概念
### 3.1.1 语法树的定义和结构
在计算机科学中,语法树是一种用来表示源代码语法结构的树形数据结构。它以树的形式展示了源代码的语法规则,其中每个节点代表源代码中的构造,例如表达式、语句、声明等。在Python代码解析中,语法树是一种核心数据结构,它可以帮助开发者理解代码的结构和语义。
语法树的构建通常从源代码开始,通过一系列的语法分析步骤,例如词法分析和语法分析,最终形成一个树状结构。语法树的每个节点都是一个语法单元,可以是操作符、变量、函数调用等。树的根节点通常代表整个程序或模块,而叶子节点代表基本语法单元。
### 3.1.2 语法树在Python代码解析中的作用
语法树在Python代码解析中的作用至关重要。它不仅是解释器或编译器理解代码的中间步骤,还对于代码审查、优化、生成等高级操作提供了基础。通过语法树,可以进行如下的操作:
- **代码分析**:分析代码的结构和风格,检查是否有语法错误或潜在的逻辑问题。
- **代码转换**:将一种代码风格转换成另一种,或者优化代码以提高性能。
- **代码生成**:从已有的语法树中生成新的代码,例如在代码生成工具中。
- **自动化重构**:在不改变程序行为的前提下,自动化地改变代码结构。
## 3.2 语法树的构建过程
### 3.2.1 语法树的构建原理
构建语法树的原理基于对源代码的分层解析。首先,词法分析器(Lexer)将源代码文本转换为一系列的token(如关键字、标识符、字面量等),然后语法分析器(Parser)根据这些token和语言的语法规则,构建出代表程序结构的树状模型。
这个过程通常涉及递归下降解析、LL解析、LR解析等技术。这些技术的不同之处在于处理语法规则和生成语法树的方式。例如,LL解析器从左到右扫描输入并构建左派生树,而LR解析器则构建右派生树,并能够处理更复杂的语法结构。
### 3.2.2 语法树的构建方法
构建语法树的方法涉及具体的应用场景。在Python中,可以使用内置的`ast`模块来构建语法树。`ast`模块提供了一系列的类和函数,用于分析Python源代码并生成语法树。以下是一个简单的例子,展示如何使用`ast`模块来解析一个简单的Python语句并生成对应的语法树:
```python
import ast
# 示例代码
code = "a = 1 + 2"
# 解析代码,生成语法树
parsed_code = ast.parse(code)
# 打印语法树
print(ast.dump(parsed_code))
```
在上述代码中,`ast.parse`函数用于解析传入的代码字符串,并返回一个`AST`对象。`ast.dump`函数则用于打印语法树的内容。
## 3.3 语法树的优化和应用
### 3.3.1 语法树的优化策略
在构建和使用语法树时,优化策略是提高效率和性能的关键。下面是一些常见的优化策略:
- **节点重用**:在语法树中,很多节点类型是重复的,比如多个加法操作可能会有相同结构的节点。可以通过节点池的方式重用这些节点,减少内存消耗。
- **懒加载**:在语法树非常大的情况下,可以采用懒加载的策略,即只有在需要时才构建树的部分节点。
- **树压缩**:对于一些不影响程序语义的节点,如括号表达式,可以在构建语法树时进行优化,省略这些节点以减少树的深度和宽度。
### 3.3.2 语法树在代码重构和维护中的应用
代码重构和维护是软件开发中的重要环节。语法树为这两个过程提供了强大的工具。以下是语法树在代码重构和维护中的典型应用:
- **自动化重构**:通过遍历语法树并修改节点,可以实现代码的自动化重构。例如,更改一个变量名的所有引用,或者将一个函数从一个地方移动到另一个地方。
- **代码维护**:在代码维护过程中,语法树可以帮助开发者理解复杂的代码逻辑,甚至帮助自动检测和修复bug。
举一个具体的例子,考虑重构以下Python代码片段中的变量名:
```python
x = 1
y = 2
z = x + y
```
如果要将变量名`x`和`y`重命名为`width`和`height`,可以遍历语法树,找到相关的变量引用,并更新它们的节点。
```python
import ast
import copy
# 原始代码
code = """
x = 1
y = 2
z = x + y
# 解析代码,生成语法树
parsed_code = ast.parse(code)
# 遍历语法树并修改节点
for node in ast.walk(parsed_code):
if isinstance(node, ast.Name) and node.id in ('x', 'y'):
new_node = copy.copy(node)
new_node.id = new_node.id.replace('x', 'width').replace('y', 'height')
ast.copy_location(new_node, node)
node = new_node
# 打印修改后的语法树
print(ast.dump(parsed_code, indent=4))
```
在上述代码中,我们遍历语法树,找到所有的变量名引用,并将`x`和`y`替换为`width`和`height`。通过这种方式,开发者可以快速重构代码,而不必手动搜索和替换文本。
通过这些优化策略和应用,我们可以看到语法树对于代码解析和维护的重要性。它不仅帮助开发者更好地理解代码结构,还能够有效支持自动化工具的开发,提高编程效率和软件质量。
# 4. Python代码解析的实践应用
## 4.1 Python代码解析的常见问题及解决方案
### 4.1.1 Python代码解析中的常见错误
在Python代码解析过程中,开发者经常会遇到一系列问题,这可能会导致解析错误或者不准确的结果。一些常见的错误包括但不限于:
- **语法错误**: 这是最常见的错误类型,可能由于缺少括号、逗号等标点符号,或使用了错误的关键字。
- **缩进错误**: Python使用缩进来定义代码块。不一致或不正确的缩进可能导致代码无法正常执行。
- **编码问题**: 如果源代码文件没有正确地标记其编码,解析器可能无法正确读取文件。
- **导入错误**: 在尝试解析包含未定义模块或包导入的代码时,可能会遇到错误。
### 4.1.2 Python代码解析错误的解决方案
为了有效地解决这些解析错误,可以采取以下措施:
- **使用静态代码分析工具**: 利用像 `flake8` 或 `pylint` 这样的工具在代码运行前检查潜在的语法和编码问题。
- **编写健壮的解析器**: 为了处理缩进和编码问题,可以编写一个健壮的解析器,该解析器能够给出更详细的错误提示,并在可能的情况下尝试自动修复这些问题。
- **模块化代码**: 将大型代码库拆分成多个模块和包,这有助于简化导入问题,并能更清晰地管理依赖关系。
- **异常处理**: 在代码中添加异常处理逻辑,以捕获并处理解析器可能抛出的错误。
## 4.2 Python代码解析的高级应用
### 4.2.1 Python代码解析在代码审查中的应用
代码审查是一种提高代码质量和一致性的常见做法。在审查过程中,解析技术可以用来:
- **自动化代码格式化检查**: 使用解析技术分析代码结构,确保代码遵循一致的格式化标准。
- **检测代码复杂度**: 通过解析代码来计算函数和类的复杂度,这有助于识别需要重构的部分。
- **检测潜在错误**: 解析器可以检查未使用的变量、可能的逻辑错误、甚至安全漏洞。
### 4.2.2 Python代码解析在代码生成中的应用
代码生成是一个将设计规范转换为实际代码的过程,代码解析在其中扮演了重要角色:
- **基于模板的代码生成**: 解析器可以用来分析模板语言,并将其转换为完整的代码库。
- **转换代码范式**: 利用解析技术,可以将遗留代码从一种范式(如过程式编程)转换为更现代的范式(如面向对象编程)。
- **自动生成测试代码**: 解析已有代码,可以自动生成单元测试代码,以确保代码的正确性。
## 4.3 Python代码解析的未来展望
### 4.3.1 Python代码解析技术的发展趋势
未来,Python代码解析技术可能会朝向以下方向发展:
- **集成人工智能**: 使用AI来提高代码解析的智能性,如通过深度学习来更准确地识别模式和结构。
- **跨语言解析能力**: 发展更加通用的解析技术,支持跨语言的代码分析和操作。
- **云原生解析服务**: 利用云平台提供代码解析服务,支持大规模代码库的实时分析。
### 4.3.2 Python代码解析在人工智能中的应用前景
在AI领域,Python代码解析可能会成为:
- **自动化机器学习**: 利用解析技术理解数据处理和模型训练代码,自动化调整算法参数。
- **代码推荐系统**: 结合代码解析和自然语言处理技术,开发出能够根据上下文推荐代码片段的系统。
- **智能编程助手**: 使用解析技术让编程助手能够更准确地理解程序员的意图,并提供更加精确的代码建议和补全。
```python
# 示例代码块:使用ast模块解析Python代码
import ast
def parse_code(code):
try:
# 将字符串形式的代码转换成AST(抽象语法树)
tree = ast.parse(code)
# 打印AST以供分析
print(ast.dump(tree, indent=4))
return tree
except SyntaxError as e:
print(f"Syntax Error: {e.msg}")
return None
# 示例字符串形式的Python代码
code_sample = """
def example_function(x):
return x * 2
# 执行解析
parse_result = parse_code(code_sample)
```
在上述代码块中,我们展示了如何使用Python的`ast`模块解析一个简单的函数定义。该解析器将代码转换成一个AST对象,AST对象包含了代码的抽象语法结构。利用这个结构,我们可以执行各种代码分析任务,如提取代码中的函数定义、循环结构等。
在表格中,我们能够展示如何使用不同的解析技术针对不同代码特点进行分类,并提供每种技术的优势和适用场景:
| 解析技术 | 适用场景 | 优势 |
|------------|--------------------------------------------------|------------------------------------------------------|
| tokenize | 词法分析,用于标记化处理代码 | 精确控制代码解析过程,易于扩展 |
| ast | 结构化分析,用于理解代码语法结构 | 可以轻松遍历、修改代码树 |
| linter | 代码质量分析,用于检测代码中的错误和风格问题 | 可以快速提升代码质量,加强代码维护性 |
| static analysis | 静态代码分析,用于更深层次的代码语义和安全性检查 | 可以自动检测潜在的安全威胁和复杂度问题,减少人工审核工作量 |
```mermaid
graph LR
A[开始解析] --> B{代码类型}
B -->|令牌化| C(tokenize库)
B -->|抽象语法树| D(ast库)
B -->|静态分析| E(static分析工具)
C --> F[生成令牌序列]
D --> G[构建语法树]
E --> H[检测代码质量]
F --> I[解析结果]
G --> I
H --> I
```
在mermaid流程图中,我们展示了代码解析的一个基本流程,从开始解析到选择不同的解析技术,最终输出解析结果。这个过程可以是顺序的,也可以是迭代的,具体取决于开发者的具体需求。
# 5. ```
# 第五章:总结与展望
## 5.1 本文的总结
在前文的章节中,我们对Python代码解析的艺术进行了深入探讨,从tokenize库的使用到语法树的构建和优化,再到代码解析的实践应用,我们系统地学习了Python代码解析的各个方面。
首先,我们了解了tokenize库的基本概念及其安装和导入方式,探讨了其主要功能和使用方法,并通过案例学习了如何在实际中应用tokenize库进行代码分析。此外,我们还讨论了如何利用tokenize库自定义token类型以及在代码优化中的高级应用。
接着,我们转向了语法树的学习。我们定义了语法树,并讨论了它在Python代码解析中的核心作用。详细介绍了语法树的构建过程,包括其构建原理和构建方法。我们也探讨了优化语法树的策略,以及它在代码重构和维护中的应用。
在深入理解语法树之后,我们探讨了Python代码解析的实践应用。从常见问题及解决方案出发,我们讨论了如何应对解析错误,并且在高级应用中探索了代码审查和代码生成的策略。最后,我们展望了代码解析技术的未来趋势,以及它在人工智能领域中的应用前景。
## 5.2 对Python代码解析未来发展的展望
随着人工智能和机器学习的不断进步,Python代码解析技术正变得越来越重要。未来,我们可以期待以下几个领域的发展:
1. **智能化解析工具**:开发更加智能化的代码解析工具,它们能自动识别代码中的模式并提供改进建议。这可能包括更复杂的数据流分析和行为预测。
2. **集成开发环境(IDE)的增强**:IDE可能集成更先进的解析功能,如实时代码质量评估和快速修复建议,从而提高开发者的生产力。
3. **代码重构和维护自动化**:通过高级解析技术,未来的重构工具可以更安全、更智能地处理复杂的代码变更,减少人为错误并减少维护成本。
4. **静态代码分析的扩展应用**:随着静态分析技术的改进,Python代码解析将被应用于更多软件开发生命周期的阶段,提供早期的错误检测和性能优化。
5. **开源社区的贡献**:我们预见到社区驱动的工具将不断涌现,它们将为Python代码解析引入新的视角和创新的方法。
代码解析是软件开发的基石,其未来的发展将直接影响到整个IT行业。我们相信,随着技术的不断进步,代码解析将变得更加高效、准确和智能。
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python tokenize 库学习专栏!该专栏深入探讨了 tokenize 库在 Python 代码分析、安全审计、代码优化、自动化处理、调试和性能分析等方面的广泛应用。您将了解 tokenize 库的工作原理,学习如何自定义 Token 解析器,并探索其在教育、代码生成、程序重构和扩展模块开发中的应用。此外,专栏还涵盖了 Python 3 与 tokenize 的兼容性,以及在不同环境下的适配技巧。通过深入了解 tokenize 库,您将掌握 Python 代码分析和处理的强大工具,提升您的编程技能和代码质量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SAPSD定价策略深度剖析:成本加成与竞对分析,制胜关键解读
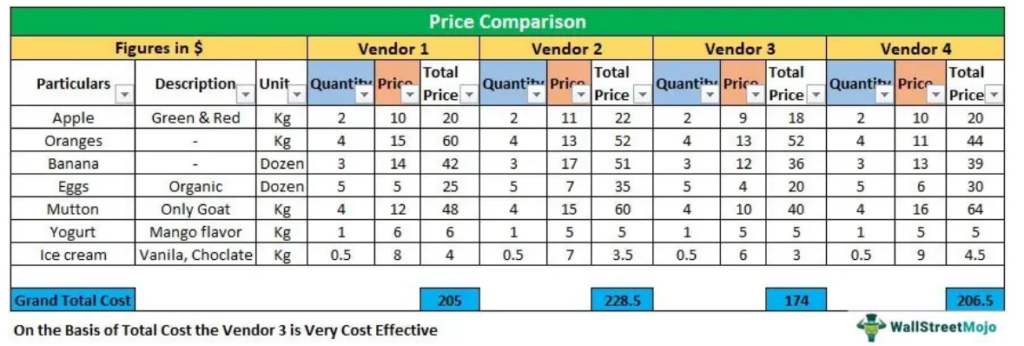
# 摘要
本文首先概述了SAPSD定价策略的基础概念,随后详细介绍了成本加成定价模型的理论和计算方法,包括成本构成分析、利润率设定及成本加成率的计算。文章进一步探讨了如何通过竞争对手分析来优化定价策略,并提出了基于市场定位的定价方法和应对竞争对手价格变化的策略。通过实战案例研究,本文分析了成本加成与市场适应性策略的实施效果,以及竞争对手分析在案例中的应用。最后,探
【指纹模组选型秘籍】:关键参数与性能指标深度解读
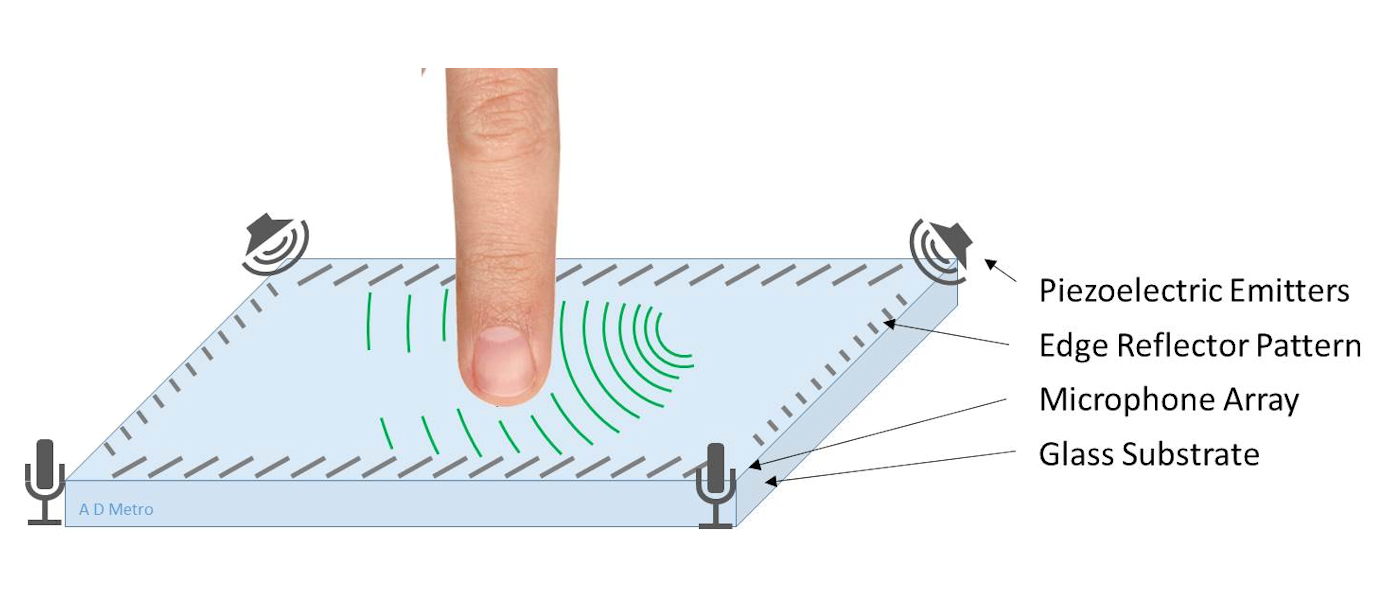
# 摘要
本文系统地介绍了指纹模组的基础知识、关键技术参数、性能测试评估方法,以及选型策略和市场趋势。首先,详细阐述了指纹模组的基本组成部分,如传感器技术参数、识别算法及其性能、电源与接口技术等。随后,文章深入探讨了指纹模组的性能测试流程、稳定性和耐用性测试方法,并对安全性标准和数据保护进行了评估。在选型实战指南部分,根据不同的应用场景和成本效益分析,提供了模组选择的实用指导。最后,
凌华PCI-Dask.dll全解析:掌握IO卡编程的核心秘籍(2023版)
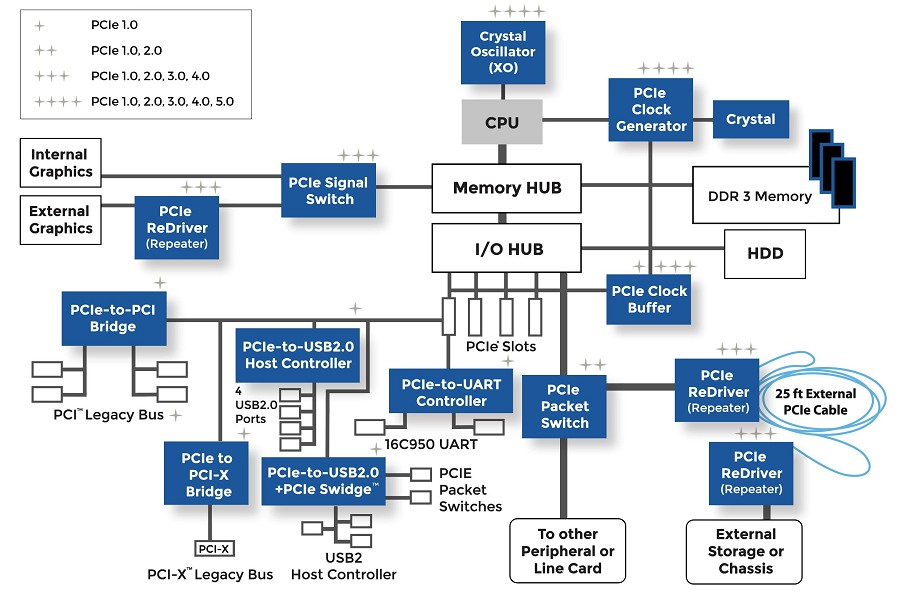
# 摘要
凌华PCI-Dask.dll是一个专门用于数据采集与硬件控制的动态链接库,它为开发者提供了一套丰富的API接口,以便于用户开发出高效、稳定的IO卡控制程序。本文详细介绍了PCI-Dask.dll的架构和工作原理,包括其模块划分、数据流缓冲机制、硬件抽象层、用户交互数据流程、中断处理与同步机制以及错误处理机制。在实践篇中,本文阐述了如何利用PCI-Dask.dll进行IO卡编程,包括AP
案例分析:MIPI RFFE在实际项目中的高效应用攻略

# 摘要
本文全面介绍了MIPI RFFE技术的概况、应用场景、深入协议解析以及在硬件设计、软件优化与实际项目中的应用。首先概述了MIPI RFFE技术及其应用场景,接着详细解析了协议的基本概念、通信架构以及数据包格式和传输机制。随后,本文探讨了硬件接口设计要点、驱动程序开发及芯片与传感器的集成应用,以及软件层面的协议栈优化、系统集成测试和性能监控。最后,文章通过多个项目案例,分析了MIPI RF
Geolog 6.7.1高级日志处理:专家级功能优化与案例研究
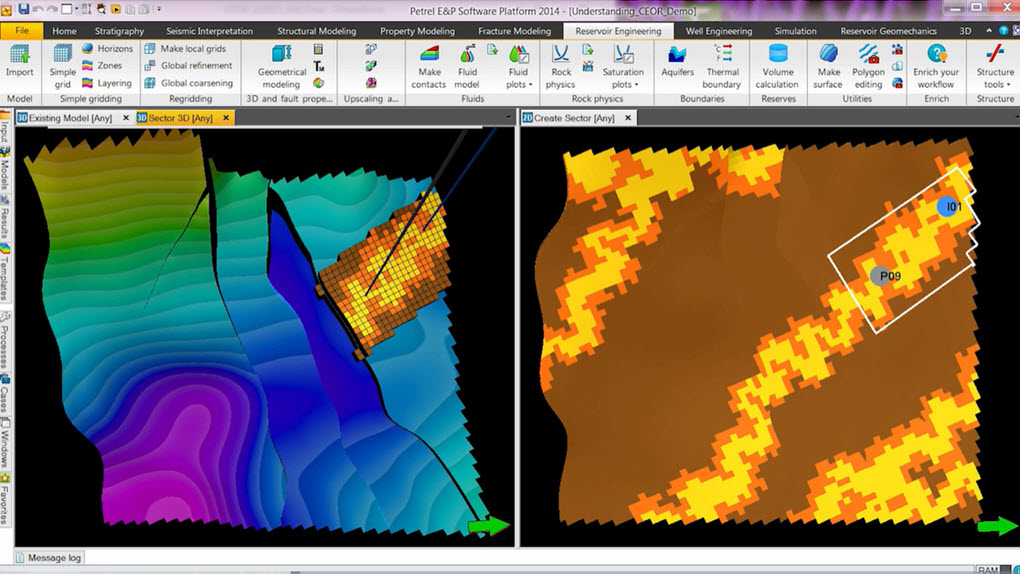
# 摘要
本文全面介绍了Geolog 6.7.1版本,首先提供了该软件的概览,接着深入探讨了其高级日志处理、专家级功能以及案例研究,强调了数据过滤、索引、搜索和数据分析等关键功能。文中分析了如何通过优化日志处理流程,解决日志管理问题,以及提升日志数据分析的价值。此外,还探讨了性能调优的策略和维护方法。最后,本文对Geolog的未来发展趋势进行了展望,包括新版本
ADS模型精确校准:掌握电感与变压器仿真技术的10个关键步骤

# 摘要
本文全面介绍了ADS模型精确校准的理论基础与实践应用。首先概述了ADS模型的概念及其校准的重要性,随后深入探讨了其与电感器和变压器仿真原理的基础理论,详细解释了相关仿真模型的构建方法。文章进一步阐述了ADS仿真软件的使用技巧,包括界面操作和仿真模型配置。通过对电感器和变压器模型参数校准的具体实践案例分析,本文展示了高级仿真技术在提高仿真准确性中的应用,并验证了仿真结果的准确性。最后
深入解析华为LTE功率控制:掌握理论与实践的完美融合

# 摘要
本文对LTE功率控制的技术基础、理论框架及华为在该领域的技术应用进行了全面的阐述和深入分析。首先介绍了LTE功率控制的基本概念及其重要性,随后详细探
【Linux故障处理攻略】:从新手到专家的Linux设备打开失败故障解决全攻略
# 摘要
本文系统介绍了Linux故障处理的基本概念,详细分析了Linux系统的启动过程,包括BIOS/UEFI的启动机制、内核加载、初始化进程、运行级和
PLC编程新手福音:入门到精通的10大实践指南

# 摘要
本文旨在为读者提供一份关于PLC(可编程逻辑控制器)编程的全面概览,从基础理论到进阶应用,涵盖了PLC的工作原理、编程语言、输入输出模块配置、编程环境和工具使用、项目实践以及未来趋势与挑战。通过详细介绍PLC的硬件结构、常用编程语言和指令集,文章为工程技术人员提供了理解和应用PLC编程的基础知识。此外,通过对PLC在自动化控制项目中的实践案例分析,本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )