【Python数据结构实战手册】:打造复杂数据处理系统
发布时间: 2024-09-11 20:24:36 阅读量: 292 订阅数: 50 

Python学习资料及数据分析与自然语言处理.zip

# 1. Python数据结构概述与应用
在开始深入探索Python编程之前,理解数据结构是至关重要的。数据结构不仅是一门组织和存储数据的艺术,也是有效处理信息的基础。本章将为读者提供Python数据结构的概述,以及如何在各种应用场景中进行实际应用。
## 1.1 数据结构的重要性
数据结构是编程的核心,它定义了数据的组织方式和存储结构,影响着算法的效率和资源的使用。对于Python,它丰富的内置数据结构允许开发者快速实现复杂的数据操作。
## 1.2 常见数据结构类型
Python中的数据结构包括但不限于列表(list)、元组(tuple)、字典(dict)、集合(set)和字符串(str)。列表和元组是序列数据结构,常用于存储有序元素集合;字典是映射数据结构,能够通过键值对快速检索元素;集合用于存储唯一元素,而字符串则是字符序列。
## 1.3 应用实例:数据存储与访问
举一个简单的例子,假设我们需要存储一个学生的信息。我们可以使用字典来存储学生的姓名、年龄、分数等信息。以下是一个简单的Python代码片段:
```python
student_info = {
'name': 'Alice',
'age': 20,
'grades': [90, 95, 88]
}
print(student_info['name']) # 输出: Alice
```
在上述代码中,我们创建了一个字典`student_info`并添加了一些键值对。使用`print`函数,我们可以通过指定键(如'name')来访问对应的值。
这一章我们仅仅入门了Python数据结构的世界,但在后续章节中,我们将深入探讨每一种数据结构,并演示如何将它们应用于解决实际问题。从基本的数据结构到复杂的系统设计,我们将逐步揭开Python数据结构的神秘面纱。
# 2. 深入理解Python基本数据类型
Python作为一种高级编程语言,为开发者提供了丰富多样的数据类型。掌握这些数据类型不仅有助于编写更高效、更安全的代码,而且能够更好地理解和使用Python的高级特性。本章将深入探讨Python中的不可变和可变数据类型,并提供数据类型转换的策略以及性能优化方法。
## 2.1 不可变数据类型分析
在Python中,不可变数据类型指的是那些一旦创建就不能修改的数据类型。Python的不可变类型主要包括数字、字符串和元组。
### 2.1.1 数字类型及其操作
Python中的数字类型包括整数、浮点数、复数。Python3中整数类型不再有限制,而浮点数则遵循IEEE 754标准。Python提供了丰富的内置运算符和函数来操作数字类型。
#### 数字类型的操作示例
```python
# 整数运算示例
a = 10
b = 3
print(a + b) # 加法
print(a - b) # 减法
print(a * b) # 乘法
print(a // b) # 整除
print(a % b) # 求余
print(a ** b) # 求幂
# 浮点数运算示例
c = 2.5
d = 3.2
print(c + d) # 加法
print(c * d) # 乘法
print(c / d) # 除法
# 复数运算示例
e = 3 + 4j
f = 1 - 2j
print(e + f) # 复数加法
print(e * f) # 复数乘法
```
### 2.1.2 字符串和元组的使用
字符串和元组是Python中常用的数据类型,它们都是不可变的。字符串是字符的有序序列,而元组是多个元素的有序集合。
#### 字符串的常见操作
```python
s = "Hello, World!"
print(s.upper()) # 转换成大写
print(s.lower()) # 转换成小写
print(s.split(',')) # 以','分割字符串
print(s.replace('World', 'Python')) # 替换字符串内容
```
#### 元组的常见操作
```python
t = (1, 2, 3, 4, 5)
print(t.count(2)) # 计算元素出现次数
print(t.index(4)) # 查找元素位置
print(t + (6, 7)) # 元组合并
```
## 2.2 可变数据类型详解
与不可变数据类型不同,可变数据类型可以在程序运行时修改其内容。在Python中,列表、字典和集合是典型的可变数据类型。
### 2.2.1 列表的操作与应用
列表是Python中最常用的可变类型之一。列表中的元素可以是任意类型,包括数字、字符串、甚至是其他列表。
#### 列表的基本操作
```python
# 列表创建与访问
fruits = ['apple', 'banana', 'cherry']
print(fruits[0]) # 访问第一个元素
# 列表元素的增加和删除
fruits.append('orange')
fruits.remove('banana')
print(fruits)
# 列表排序
fruits.sort() # 按字典顺序排序
print(fruits)
```
### 2.2.2 字典和集合的高级使用
字典是一种键值对的集合,每个键值对称为一个项。集合是一个无序的不重复元素集。
#### 字典和集合的常见操作
```python
# 字典的创建与访问
person = {'name': 'John', 'age': 30, 'city': 'New York'}
print(person['name']) # 访问字典中的值
# 集合的创建与操作
colors = {'red', 'green', 'blue'}
colors.add('yellow')
print(colors)
```
## 2.3 数据类型转换与优化
数据类型转换指的是将一种数据类型转换为另一种数据类型。Python提供了丰富的内建函数来实现这一转换。
### 2.3.1 类型转换策略
在Python中,可以使用诸如`int()`, `float()`, `str()`, `list()`, `dict()`等函数将数据类型相互转换。
```python
# 数字类型转换为字符串
num = 123
num_str = str(num)
print(num_str, type(num_str))
# 字符串转换为数字
str_num = '123'
print(int(str_num), type(int(str_num)))
# 列表转换为元组
lst = [1, 2, 3]
tup = tuple(lst)
print(tup, type(tup))
# 字典转换为列表
dict_items = person.items()
print(list(dict_items), type(list(dict_items)))
```
### 2.3.2 内存管理和性能优化
Python的内存管理是自动的,但是了解一些基本的内存使用原理可以帮助我们写出更好的代码。
```mermaid
graph LR
A[开始] --> B[对象创建]
B --> C{是否引用}
C -->|是| D[对象保留在内存]
C -->|否| E[垃圾回收]
E --> F[优化内存]
```
在Python中,使用`del`语句可以删除对象的引用,有助于Python垃圾回收器回收内存。
```python
# 使用del释放对象引用
del person
```
**性能优化小贴士:** 尽量减少全局变量的使用,因为全局变量会阻止Python的垃圾回收器回收内存。同时,应避免在循环中创建新的对象。
在本章节中,我们深入探讨了Python中的不可变和可变数据类型,并学习了不同类型之间的转换策略。通过具体的操作示例和内存管理的最佳实践,本章内容旨在加深读者对Python基础数据类型的理解,为后续章节中复杂数据结构的构建与应用打下坚实的基础。在接下来的章节中,我们将继续探索如何在Python中构建和应用更复杂的数据结构,并分析它们在实际问题中的应用。
# 3. 复杂数据结构的构建与应用
在处理复杂问题时,掌握复杂数据结构的构建和应用是至关重要的。这一章节将深入探讨栈、队列、树、图和哈希表等数据结构的内部原理和实际应用案例。通过本章节的学习,读者应能熟悉这些高级数据结构,并能够在自己的项目中恰当选择和应用。
## 3.1 栈和队列在算法中的实现
### 3.1.1 栈的基本原理与操作
栈是一种后进先出(LIFO)的数据结构,它只允许在一端(通常称为“顶部”)进行插入(push)和删除(pop)操作。栈的操作非常简单,但功能却十分强大,在算法中被广泛应用,如函数调用、表达式求值、递归算法等场景。
```python
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
def pop(self):
return self.stack.pop()
def peek(self):
return self.stack[-1]
def is_empty(self):
return len(self.stack) == 0
def size(self):
return len(self.stack)
```
在这个简单的栈实现中,我们使用Python内置的列表来存储数据。`push()`方法向栈中添加元素,`pop()`方法从栈中移除元素并返回它。`peek()`方法返回栈顶元素而不移除它,`is_empty()`方法检查栈是否为空,而`size()`方法返回栈中元素的数量。
### 3.1.2 队列的实现与应用
队列是一种先进先出(FIFO)的数据结构,它允许在一端添加元素(入队),而在另一端删除元素(出队)。队列在很多场景中都有应用,如任务调度、缓冲处理等。
```python
from collections import deque
class Queue:
def __init__(self):
self.queue = deque()
def enqueue(self, item):
self.queue.append(item)
def dequeue(self):
return self.queue.popleft()
def is_empty(self):
return len(self.queue) == 0
def size(self):
return len(self.queue)
```
在这个队列的Python实现中,我们使用`collections.deque`,这是因为`deque`提供了一个双端队列,它比列表更适合实现队列操作,具有更高的性能。
#### 栈和队列的高级应用案例
在解决实际问题时,栈和队列经常被用于算法中。例如,栈可以用来检查括号是否正确匹配,而队列则常用于广度优先搜索(BFS)算法中。
## 3.2 树与图的构建及应用
### 3.2.1 二叉树的操作与遍历
树是一种分层数据结构,广泛应用于数据库索引、文件系统的组织、搜索算法等领域。二叉树是树的一种特殊形式,其中每个节点最多有两个子节点,通常称为左子节点和右子节点。
```python
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
class BinaryTree:
def __init__(self, root_value):
self.root = TreeNode(root_value)
# 添加节点方法、遍历方法等将在后续章节中介绍。
```
在这个基础的二叉树实现中,我们定义了`TreeNode`类来表示树的节点,并使用一个根节点来构建整棵树。树的遍历方式包括前序遍历、中序遍历、后序遍历以及层序遍历。
### 3.2.2 图的创建与搜索算法
图是由顶点(节点)和边组成的网络结构。图分为有向图和无向图,常用于表示网络、社交网络、推荐系统等。
```python
class Graph:
def __init__(self):
self.adj_list = {}
def add_vertex(self, vertex):
if vertex not in self.adj_list:
self.adj_list[vertex] = []
def add_edge(self, v1, v2):
if v1 in self.adj_list and v2 in self.adj_list:
self.adj_list[v1].append(v2)
self.adj_list[v2].append(v1) # For undirected graph
```
在这个图的实现中,我们使用邻接表(`adj_list`)来表示图。`add_vertex()`方法用于添加顶点,`add_edge()`方法用于添加边。根据需要,图可以是无向的,也可以是定向的。
#### 树和图的高级应用案例
在构建系统和算法时,树和图的使用可以极大地提高数据处理效率。例如,二叉搜索树(BST)可以用于高效地查找和排序数据,而图搜索算法(如深度优先搜索DFS和广度优先搜索BFS)可用于解决路径查找和网络流量问题。
## 3.3 高级数据结构的选择与应用
### 3.3.1 哈

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索 Python 数据结构的各个方面,从内置数据类型到高级自定义结构。它涵盖了数据结构的优化、内存管理、性能比较、构建技巧、算法应用、实战案例和内存剖析。通过一系列文章,本专栏旨在提升读者对 Python 数据结构的理解,并帮助他们高效地使用这些结构来解决现实世界中的问题。无论你是初学者还是经验丰富的程序员,本专栏都能为你提供宝贵的见解和实用技巧,让你在 Python 数据结构的世界中游刃有余。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
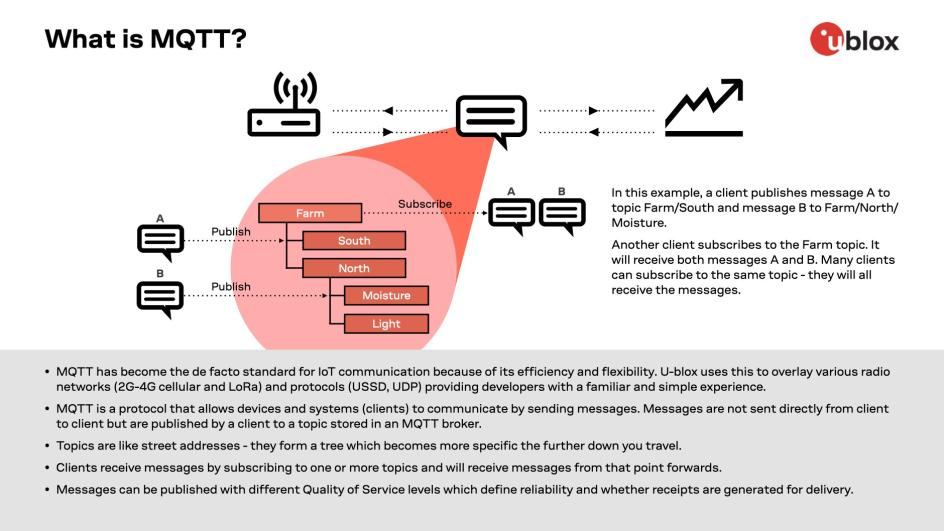
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )