【Python库文件学习之Twitter与大数据】:大数据处理专家,应对大规模Twitter数据流的挑战
发布时间: 2024-10-14 14:14:06 阅读量: 19 订阅数: 22 

# 1. Twitter数据流与大数据概述
在当今的信息时代,社交媒体如Twitter已成为数据流的重要来源,它以每秒数以万计的推文速度产生海量数据。这些数据流不仅包含用户的日常交流,还蕴含着丰富的社会、经济和政治信息,为大数据分析提供了丰富的素材。大数据技术的发展,使得我们能够存储、处理和分析这些庞大的数据集,从而从中提取有价值的洞察。
大数据不仅仅是数据量的增加,更是一种处理数据的新方法。它涉及数据的采集、存储、管理、分析和可视化等多个方面。通过大数据技术,我们可以对Twitter数据进行实时监控,追踪热点话题,甚至进行情感分析,了解公众情绪的微妙变化。
本章将概述Twitter数据流的特点,以及大数据技术在处理这类数据时的作用和挑战。我们将从基础的Twitter数据流结构讲起,逐步深入到大数据分析的技术和实践,为后续章节的深入学习打下坚实的基础。
# 2. Python库文件基础
在现代数据科学和大数据处理中,Python作为一个功能强大的编程语言,其丰富的库文件为处理各种数据提供了强大的支持。本章节将深入探讨Python的基础语法、数据结构以及如何使用Python进行文件操作和数据处理。此外,我们还将学习如何通过网络编程与API进行交互,尤其是如何与Twitter API进行数据的获取和发送。
## 2.1 Python基础语法和数据结构
### 2.1.1 Python的基本语法
Python以其简洁明了的语法和强大的功能而闻名。在Python中,代码块是通过缩进来表示的,而不是使用大括号或关键字。这种设计使得Python代码易于阅读和编写。Python的基本数据类型包括整数、浮点数、字符串、布尔值和None。
```python
# 定义变量
name = "DataScientist" # 字符串
age = 28 # 整数
salary = 55000.0 # 浮点数
is_active = True # 布尔值
nothing = None # None
# 输出变量
print(name)
print(age)
print(salary)
print(is_active)
print(nothing)
```
在Python中,条件语句使用`if`关键字,循环使用`for`和`while`关键字。函数使用`def`关键字定义。
```python
# 条件语句
if age >= 18:
print("You are an adult.")
elif age >= 13:
print("You are a teenager.")
else:
print("You are a child.")
# 循环语句
for i in range(5):
print("Loop iteration: ", i)
count = 0
while count < 5:
print("While loop iteration: ", count)
count += 1
# 函数定义
def greet(name):
return "Hello, " + name + "!"
print(greet("Alice"))
```
### 2.1.2 常用的数据结构介绍
Python提供了多种内置的数据结构,包括列表(List)、元组(Tuple)、字典(Dictionary)和集合(Set)。
```python
# 列表
my_list = [1, 2, 3, 4, 5]
my_list.append(6) # 添加元素
print(my_list)
# 元组
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[1]) # 访问元素
# 字典
my_dict = {'name': 'Alice', 'age': 25}
print(my_dict['name']) # 访问字典值
# 集合
my_set = {1, 2, 3, 4, 5}
my_set.add(6) # 添加元素
print(my_set)
```
## 2.2 Python中处理文件和数据的库
### 2.2.1 文件操作相关库
Python标准库提供了多个用于文件操作的模块,如`os`, `sys`和`shutil`。`os`模块提供了与操作系统交互的功能,`sys`模块提供了访问与Python解释器紧密相关的变量和函数,而`shutil`模块提供了许多文件操作的高级功能。
```python
import os
import sys
import shutil
# 文件操作示例
file_path = "example.txt"
# 使用os模块创建文件
if not os.path.exists(file_path):
with open(file_path, 'w') as ***
***"Hello, World!")
# 使用sys模块退出程序
sys.exit()
# 使用shutil模块复制文件
shutil.copyfile(file_path, "copy_of_example.txt")
```
### 2.2.2 数据处理相关库
Python的数据处理库主要包括`numpy`和`pandas`。`numpy`主要用于处理数值型数据,提供高性能的多维数组对象以及相关工具。`pandas`则构建在`numpy`之上,提供了DataFrame对象,非常适合于处理表格型数据。
```python
import numpy as np
import pandas as pd
# numpy数组示例
array = np.array([1, 2, 3, 4, 5])
print(array)
# pandas DataFrame示例
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [24, 27, 22]}
df = pd.DataFrame(data)
print(df)
```
## 2.3 Python网络编程和API交互
### 2.3.1 网络编程基础
Python的`socket`模块是进行网络编程的基础。它提供了标准的BSD Sockets API,可以用来创建网络连接、发送和接收数据。
```python
import socket
# 创建socket对象
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到服务器
server_address = ('localhost', 10000)
sock.connect(server_address)
# 发送数据
message = 'Hello, server!'
sock.sendall(message.encode())
# 接收数据
data = sock.recv(1024)
print(data.decode())
# 关闭连接
sock.close()
```
### 2.3.2 与Twitter API交互的方法
要与Twitter API进行交互,我们可以使用`Tweepy`库。这是一个Python库,专门用于与Twitter API进行交互。使用`Tweepy`,我们可以轻松地认证用户、发布推文、查询用户信息等。
```python
import tweepy
# 认证信息
consumer_key = 'YOUR_CONSUMER_KEY'
consumer_secret = 'YOUR_CONSUMER_SECRET'
access_token = 'YOUR_ACCESS_TOKEN'
access_token_secret = 'YOUR_ACCESS_TOKEN_SECRET'
# 设置认证
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# 创建API对象
api = tweepy.API(auth)
# 获取用户信息
user = api.get_user(screen_name='twitter')
print(user.name)
```
在本章节中,我们介绍了Python的基础语法和数据结构,探索了文件操作和数据处理的相关库,以及如何使用Python进行网络编程和与Twitter API进行交互。这些知识为后续章节中使用Python处理Twitter数据流和大数据分析打下了坚实的基础。通过本章节的介绍,读者应该能够理解Python在数据处理和网络编程中的基本应用,并能够开始编写简单的Python脚本来与Twitter API进行交互。
# 3. Twitter数据的获取与处理
### 3.1 使用Tweepy库获取Twitter数据
在本章节中,我们将深入了解如何使用Python中的Tweepy库来获取Twitter数据。Tweepy是一个开源的Python库,它提供了一系列的API接口,使得开发者可以轻松地访问Twitter数据流,并且对数据进

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列全面的文章,深入探讨了 Python 库文件在 Twitter 数据处理和分析中的应用。从入门指南到高级技巧,涵盖了 Twitter API 的使用、OAuth 认证、数据抓取、解析、存储、可视化、情感分析、趋势分析、用户行为分析、网络分析、机器学习、深度学习、自然语言处理、数据挖掘、大数据处理、云计算、实时分析、移动应用集成、API 集成和 Web 框架集成等各个方面。通过循序渐进的学习,读者将掌握 Twitter 数据处理和分析的全面知识,并能够构建强大的应用程序来利用 Twitter 的丰富数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java药店系统国际化与本地化:多语言支持的实现与优化
# 1. Java药店系统国际化与本地化的概念
## 1.1 概述
在开发面向全球市场的Java药店系统时,国际化(Internationalization,简称i18n)与本地化(Localization,简称l10n)是关键的技术挑战之一。国际化允许应用程序支持多种语言和区域设置,而本地化则是将应用程序具体适配到特定文化或地区的过程。理解这两个概念的区别和联系,对于创建一个既能满足
mysql-connector-net-6.6.0云原生数据库集成实践:云服务中的高效部署

# 1. mysql-connector-net-6.6.0概述
## 简介
mysql-connector-net-6.6.0是MySQL官方发布的一个.NET连接器,它提供了一个完整的用于.NET应用程序连接到MySQL数据库的API。随着云
【C++内存泄漏检测】:有效预防与检测,让你的项目无漏洞可寻

# 1. C++内存泄漏基础与危害
## 内存泄漏的定义和基础
内存泄漏是在使用动态内存分配的应用程序中常见的问题,当一块内存被分配后,由于种种原因没有得到正确的释放,从而导致系统可用内存逐渐减少,最终可能引起应用程序崩溃或系统性能下降。
## 内存泄漏的危害
【MySQL大数据集成:融入大数据生态】
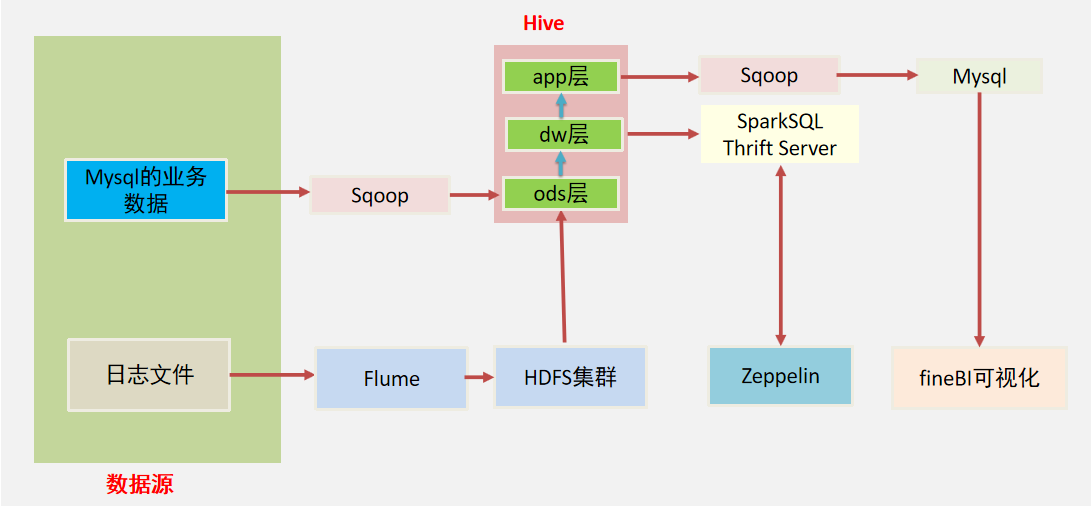
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
大数据量下的性能提升:掌握GROUP BY的有效使用技巧
# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
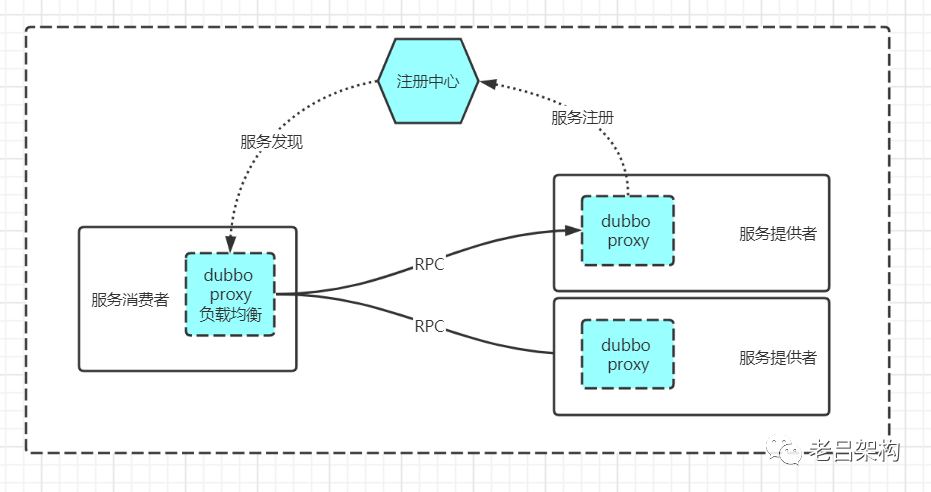
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
【多线程编程】:指针使用指南,确保线程安全与效率
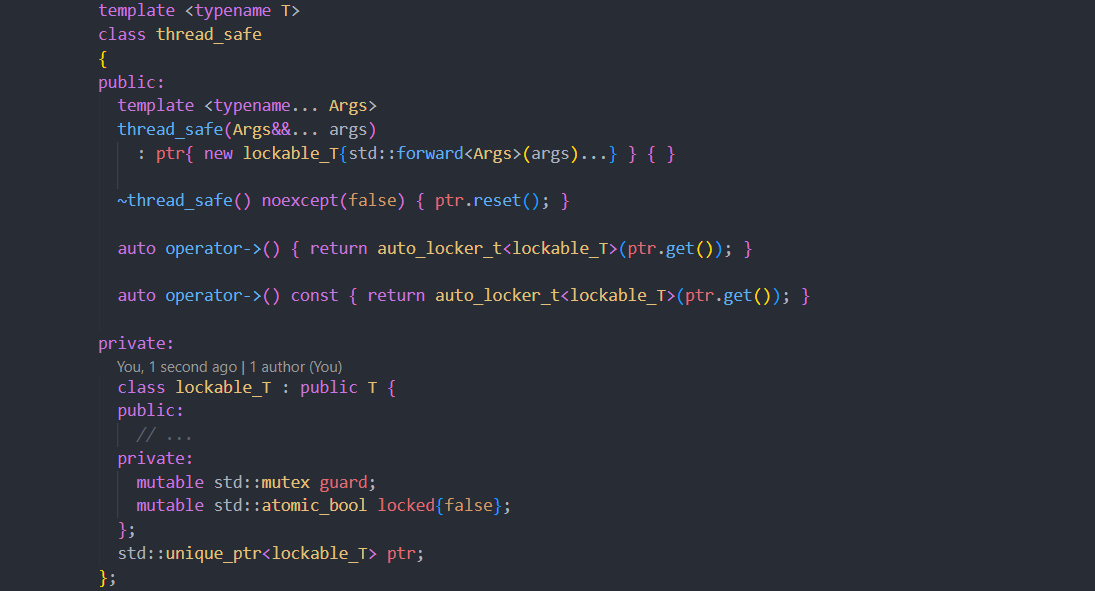
# 1. 多线程编程基础
## 1.1 多线程编程的必要性
在现代软件开发中,为了提升程序性能和响应速度,越来越多的应用需要同时处理多个任务。多线程编程便是实现这一目标的重要技术之一。通过合理地将程序分解为多个独立运行的线程,可以让CPU资源得到有效利用,并提高程序的并发处理能力。
## 1.2 多线程与操作系统
多线程是在操作系统层面上实现的,操作系统通过线程调度算法来分配CPU时
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
【SQL查询优化】:编写高效的在线音乐系统查询语句
# 1. SQL查询优化基础
SQL查询优化是提高数据库性能的关键步骤,它需要从业务需求和数据结构出发,通过各种手段减少查询所涉及的资源消耗。在本章中,我们将初步了解SQL查询优化的重要性,并探索其基础理论,为进一步深入学习做好铺垫。
## 1.1 SQL查询优化的目标
查询优化的目标是减少查询的响应时间,提高资源利用率,减少系统负载。优化过程涉及到对SQL语句的改写,利用索引,以及调整数据库配置等多个方面
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )