【Python可视化工具深度定制】
发布时间: 2024-09-01 05:51:21 阅读量: 190 订阅数: 139 

# 1. Python可视化概述
Python在数据科学和可视化领域已占据不可撼动的地位,其强大的库生态使开发者能够轻松地将数据转换为视觉信息,从而洞察数据背后的深层含义。可视化不仅是展示数据的手段,也是分析数据的重要工具,它能够帮助我们识别数据中的模式、趋势和异常值。
Python的可视化工具丰富多样,从基础的Matplotlib到高级的Seaborn,再到交互式的Plotly和Bokeh,每种工具都有其独特的使用场景和优势。Matplotlib是构建其他可视化库的基石,而Seaborn则提供了更优雅的统计图形。Plotly和Bokeh则让数据以交互式的方式呈现,极大地增强了用户体验。
本章将为读者提供一个对Python可视化工具的整体概述,从基础知识到高级应用,帮助读者建立起一个系统的可视化知识体系。我们将从为什么可视化开始,逐步深入到各种工具的介绍,让读者对Python在数据可视化方面的强大能力有一个全面的了解。接下来的章节将详细探讨每一种工具的特点、应用以及最佳实践。
# 2. Matplotlib基础知识与应用
## 2.1 Matplotlib的安装与配置
### 2.1.1 安装Matplotlib的方法
为了在Python环境中使用Matplotlib,首先需要确保已经安装了该库。Matplotlib是一个流行的Python绘图库,能够帮助开发者创建各种静态、动态、交互式的图表。安装Matplotlib的推荐方法是通过pip,Python的包管理器。可以使用以下命令进行安装:
```bash
pip install matplotlib
```
这条命令将从Python包索引(PyPI)下载最新版本的Matplotlib并安装到当前Python环境中。通常,Matplotlib与Python的标准库一起工作,无需额外配置。
### 2.1.2 配置环境及基础设置
安装完成后,我们可以开始配置Matplotlib环境以及进行一些基础设置。配置环境是指设置Matplotlib的默认行为,例如默认的图像大小、分辨率和颜色设置。基础设置通常在脚本的开始部分进行,这样可以确保整个脚本运行时都使用相同的配置。
```python
import matplotlib.pyplot as plt
# 设置图像的全局参数
plt.rcParams['figure.figsize'] = (10, 5) # 设置默认图像大小为10x5英寸
plt.rcParams['figure.dpi'] = 100 # 设置默认图像分辨率为100 DPI
plt.rcParams['savefig.format'] = 'png' # 设置默认保存图像的格式为PNG
# 设置一些默认的样式参数
plt.rcParams['lines.linewidth'] = 2 # 设置线条宽度
plt.rcParams['lines.color'] = 'blue' # 设置线条颜色
```
通过上述代码,我们定义了一些常见的Matplotlib全局参数。这些设置影响所有使用Matplotlib创建的图表,除非在绘制图表时特别指定了其他参数。
## 2.2 Matplotlib基础图表绘制
### 2.2.1 线图和散点图的绘制
Matplotlib的强大之处在于其简单和直接的API,允许用户用很少的代码来创建复杂的图表。例如,创建一个线图或散点图只需要几行代码。下面的例子展示了如何使用Matplotlib绘制一个简单的线图和散点图:
```python
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制线图
plt.figure()
plt.plot(x, y, label='sin(x)')
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Line Plot of sin(x)')
plt.legend()
plt.show()
# 绘制散点图
plt.figure()
plt.scatter(x, y, color='red', label='sin(x) scatter')
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Scatter Plot of sin(x)')
plt.legend()
plt.show()
```
线图使用`plot`方法绘制,而散点图则使用`scatter`方法。在这些代码块中,我们使用了`numpy`库生成数据,并通过`plt.xlabel()`, `plt.ylabel()`, `plt.title()`和`plt.legend()`对图表的标题和图例等进行设置。
### 2.2.2 条形图与柱状图的创建
条形图和柱状图是数据可视化中常用的一种图表类型,它们用于展示不同类别之间的数值对比。Matplotlib提供了一个简单的方式来创建这两种图表。下面的代码展示了如何生成条形图和柱状图:
```python
# 创建类别数据和相应的数值
categories = ['Category A', 'Category B', 'Category C', 'Category D']
values = [10, 20, 15, 30]
# 绘制条形图
plt.figure()
plt.bar(categories, values)
plt.xlabel('Categories')
plt.ylabel('Values')
plt.title('Bar Chart')
plt.show()
# 绘制柱状图
plt.figure()
plt.barh(categories, values)
plt.xlabel('Values')
plt.ylabel('Categories')
plt.title('Horizontal Bar Chart')
plt.show()
```
在`plt.bar()`函数中,第一个参数是x轴上各条形的位置,第二个参数是每个条形的高度,也就是我们所要展示的数值。`plt.barh()`函数与`plt.bar()`相似,只是它会创建水平的条形图,其中的参数对应的位置和高度互换。
## 2.3 Matplotlib高级功能
### 2.3.1 自定义图表样式和颜色
Matplotlib支持自定义图表的样式和颜色,使用户能够创建具有个性化的可视化效果。我们可以自定义线条样式、标记样式和颜色映射等。下面的示例展示了如何自定义线条样式:
```python
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制自定义样式的线图
plt.figure()
plt.plot(x, y, color='green', linestyle='--', marker='o', label='custom plot')
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Custom Style Plot')
plt.legend()
plt.show()
```
在`plt.plot()`函数中,我们可以指定线条的颜色、样式、标记等。此外,Matplotlib还提供了一些预定义的颜色映射表,可以用于填充图表,例如`plt.cm.viridis`。
### 2.3.2 多轴图和子图的实现
有时,我们需要在同一张图中展示多组数据,此时可以使用多轴图或多子图来实现。Matplotlib的`subplot`功能可以帮助我们创建复杂的布局,例如在一个图像中展示多个图表。下面的例子展示了如何创建一个2x2的子图网格:
```python
# 创建数据
x = np.linspace(0, 2 * np.pi, 400)
# 子图网格布局
plt.figure(figsize=(8, 6))
# 第一个子图
plt.subplot(2, 2, 1)
plt.plot(x, np.sin(x))
plt.title('Plot 1')
# 第二个子图
plt.subplot(2, 2, 2)
plt.plot(x, np.cos(x))
plt.title('Plot 2')
# 第三个子图
plt.subplot(2, 2, 3)
plt.scatter(x, np.sin(x))
plt.title('Plot 3')
# 第四个子图
plt.subplot(2, 2, 4)
plt.scatter(x, np.cos(x))
plt.title('Plot 4')
plt.tight_layout()
plt.show()
```
在这里,`plt.subplot(2, 2, i)`表示创建一个2x2的网格,并在第i个位置创建子图。`plt.tight_layout()`用于自动调整子图参数,确保子图之间不会重叠。
通过这种方式,我们可以在一张图中展示多个不同的图表,而且每个子图都可以独立地调整样式和内容。这在比较多个数据集或不同视觉表达时非常有用。
以上就是Matplotlib的基础知识与应用的详细内容。在后续章节中,我们将探讨Seaborn数据可视化工具的高级应用,它构建在Matplotlib之上,并提供了更多高级绘图功能和美观的默认设置。
# 3. Seaborn的数据可视化高级应用
Seaborn是基于Matplotlib的Python数据可视化库,它提供了一个高级界面来绘制吸引人的统计图形。Seaborn使得创建复杂统计图表变得更加简单,同时保持了Matplotlib的灵活性和定制性。它特别适合于统计图表,例如分布图、分类图和回归模型的可视化。在本章节中,我们将深入了解Seaborn的基本概念,以及如

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了有关 Python 算法可视化工具的全面信息,旨在帮助读者掌握算法和数据结构的可视化技术。从核心工具和技巧到深度解析、性能测试和进阶之路,专栏涵盖了广泛的主题。它还探讨了可视化在算法决策、教学、优化和扩展应用中的作用。此外,专栏深入研究了数据可视化、交互式可视化、案例研究和安全性分析,为读者提供了全面的理解和应用 Python 算法可视化工具所需的知识和见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
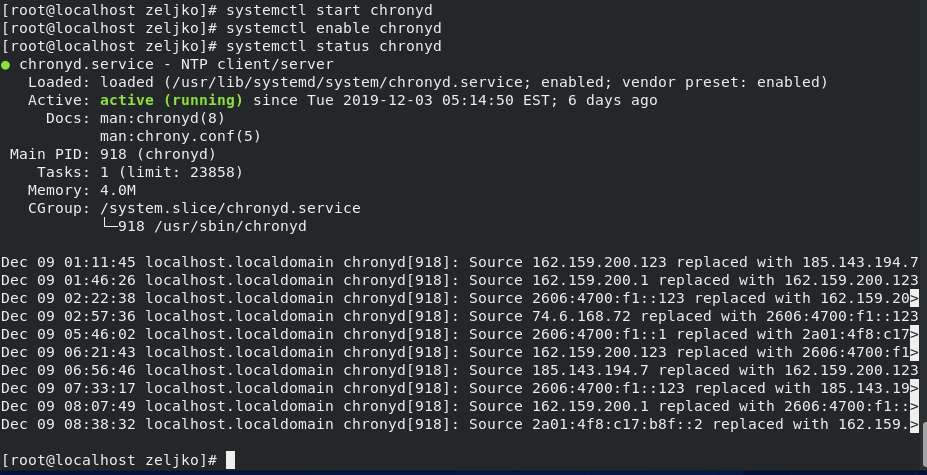
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
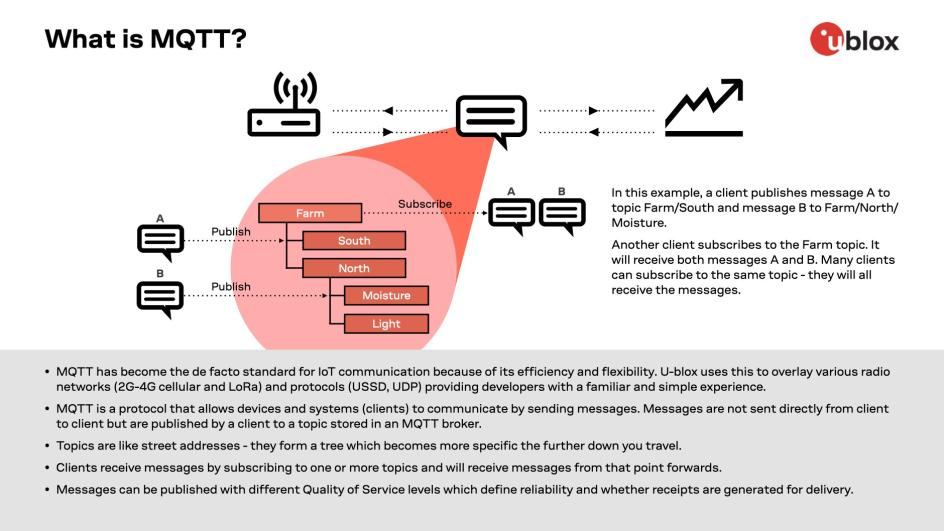
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )