【文本数据清洗】:打造高质量数据集的终极指南
发布时间: 2024-09-07 20:25:13 阅读量: 212 订阅数: 48 

千言数据集:文本相似度
# 1. 文本数据清洗概述
在信息爆炸的时代,文本数据成为了企业和研究者不可或缺的资源。有效的文本数据清洗不仅能提升数据质量,还能优化数据驱动的决策过程。本章将带你走进文本数据清洗的世界,从其基本概念开始,理解为何进行预处理以及常用的清洗方法。我们将详细探讨数据清洗的重要性,并强调其在提升数据质量和可用性方面的作用。
随着数据量的增长和数据处理技术的发展,文本数据清洗正变得越来越重要。数据预处理不再是简单的数据筛选过程,而是一个综合的数据分析和管理步骤,涉及去除噪声、规范格式、编码转换等多个环节。掌握这些基础知识,将为后续深入探讨预处理技术打下坚实的基础。
# 2. 文本数据预处理理论
## 2.1 文本数据的基本概念
### 2.1.1 文本数据的定义和特性
文本数据是由自然语言构成的非结构化信息,它们通常包括邮件、报告、网页内容、社交媒体帖子等多种形式。相较于结构化数据(如数据库中的表格数据),文本数据不遵循预定义的数据模型,因此难以直接用于数据分析和机器学习任务。
文本数据具有以下特性:
- **多变性**:自然语言在语法和词汇上都具有多样性,同一意思可以用不同的词汇和结构表达。
- **上下文依赖性**:文本中的词汇往往依赖于上下文才能准确表达其意义。
- **噪声和歧义性**:由于拼写错误、语法错误、同义词、俚语和缩写等,文本数据中存在大量噪声和歧义。
### 2.1.2 文本数据的常见问题
文本数据在进行分析之前,通常会遇到以下问题:
- **格式不统一**:文本数据来源多样,格式繁杂,不经过处理难以形成统一的数据集。
- **质量参差不齐**:由于作者水平、传输过程中的错误等因素,文本数据中存在大量噪声,如错别字、非结构化标记等。
- **不一致性**:同一概念在不同文本中可能有不同的表达方式,造成理解上的不一致。
## 2.2 文本数据预处理的必要性
### 2.2.1 数据清洗的重要性
在数据挖掘和机器学习之前,数据清洗是一个关键步骤。由于文本数据中包含大量不准确和不一致的信息,未经处理的数据会严重影响最终模型的性能。数据清洗工作包括识别和纠正数据中的错误和不一致,以便于后续分析任务的进行。
### 2.2.2 数据预处理的目标和效果
数据预处理的主要目标包括:
- **准确性**:提高数据质量,确保信息的准确性和可靠性。
- **完整性**:填充缺失值,识别和修正不一致的数据。
- **一致性**:确保数据符合预期的格式和规则,提高数据集的可用性。
经过有效的数据预处理后,数据集会变得整洁,分析结果的准确度和可信度也会显著提高。
## 2.3 文本数据预处理的常用方法
### 2.3.1 去除噪声数据
噪声数据指的是文本中无关紧要或者错误的信息,它们可能会干扰分析模型。常见的噪声数据包括HTML标签、URL链接、电子邮件地址、表情符号等。去除噪声数据的方法包括:
- **字符串替换**:利用正则表达式对特定的噪声模式进行匹配和替换。
- **自然语言处理工具**:使用NLP工具识别和去除停用词(如“的”,“和”等常见词汇)和标点符号。
### 2.3.2 数据规范化
数据规范化是将数据转换为统一的格式。在文本数据预处理中,规范化通常包括:
- **大小写转换**:将文本统一转换为小写或大写,消除大小写造成的差异。
- **词形还原**:将词汇还原到基本形式,例如将“goes”还原为“go”。
- **标准化数字和日期格式**:将数字和日期统一为标准形式,例如将“12/01/2021”和“2021-12-1”统一为“2021-12-1”。
### 2.3.3 文本编码和字符集处理
编码和字符集问题主要涉及到不同计算机系统之间的文本数据交换。预处理步骤可能包括:
- **字符集转换**:将文本从一种字符编码(如GBK)转换到另一种编码(如UTF-8),以保证跨平台的兼容性。
- **编码规范化**:确保文本使用的是标准的Unicode编码,避免乱码问题。
以下是字符集转换的Python代码示例:
```python
import chardet
# 假设我们有一个原始文本文件,内容编码可能是未知的
with open('example.txt', 'rb') as ***
***
* 使用chardet探测内容的编码
detected_encoding = chardet.detect(raw_data)
print(f"Detected encoding: {detected_encoding['encoding']}")
# 将原始数据转换为标准的UTF-8编码
utf8_data = raw_data.decode(detected_encoding['encoding'])
with open('example_utf8.txt', 'w', encoding='utf-8') as ***
***
```
在使用`chardet.detect`方法后,我们将原始字节数据解码为UTF-8编码的字符串,并写入新文件中。需要注意的是,在进行这种转换之前,我们需要确认数据使用的原始编码和目标编码,以保证转换的准确性。
在实际应用中,由于字符编码问题的复杂性,建议在数据收集阶段就明确字符编码,尽量避免后续转换带来的数据损坏风险。
通过上述内容,我们对文本数据预处理的基本概念、必要性以及常用方法进行了全面的介绍。在接下来的章节中,我们将进一步探讨文本数据清洗实践,包括工具和库的使用,以及清洗技术的应用。
# 3. 文本数据清洗实践
文本数据清洗是一个将原始文本数据转换为高质量、结构化数据的过程。本章重点介绍文本数据清洗的实践应用,从工具选择到技术应用,再到案例分析,使读者能够理解和掌握如何将理论知识应用于实际工作中。
## 3.1 文本数据清洗工具和库
### 3.1.1 文本编辑器和IDE工具
文本编辑器和集成开发环境(IDE)是进行文本数据清洗的基础工具。它们能够提供文本查找、替换、格式化和多种语言的语法高亮功能。流行的文本编辑器如Sublime Text、Notepad++等,以其轻量级和丰富的插件生态,成为数据清洗人员的首选工具。此外,专业的IDE如PyCharm、Visual Studio Code不仅支持文本编辑,还提供代码片段、调试工具和版本控制等高级功能,便于进行更复杂的清洗任务。
### 3.1.2 数据清洗专用库和工具
随着编程语言的发展,涌现出了许多用于数据清洗的专用库和工具。Python作为数据分析和处理的主流语言,拥有如`pandas`、`NumPy`、`BeautifulSoup`和`Scrapy`等强大的数据处理库。`pandas`提供了数据结构和数据分析工具,可以方便地进行数据清洗和预处理。`BeautifulSoup`和`Scrapy`专注于HTML/XML文件的解析和爬取,适合从网页中提取结构化文本信息。
## 3.2 文本数据清洗技术应用
### 3.2.1 正则表达式在清洗中的应用
正则表达式是一种用于匹配字符串中字符组合的模式。在文本数据清洗中,正则表达式可以用来识别无效数据、提取信息或者格式化文本。以下是一个使用Python和正则表达式提取URL和电子邮件地址的示例:
```python
import re
text = "访问我们的网站 *** 或者联系我们的邮箱 ***. "
urls = re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', text)
emails = re.findall(r'[\w\.-]+@[\w\.-]+', text)
print("URLs:", urls)
print("Emails:", emails)
```
在这个代码块中,我们首先导入了Python的`re`模块。然后使用`findall`方法来查找所有匹配正则表达式的部分。第一个正则表达式用于匹配URL,第二个用于匹配电子邮件地址。输出结果将会列出文本中的所有URL和电子邮件地址。
### 3.2.2 自然语言处理技术的辅助应用
自然语言处理(NLP)技术能够帮助我们更深入地理解文本内容,进行语义分析和结构化。NLP库如`NLTK`和`spaCy`提供了丰富的工具,用于执行词性标注、命名实体识别、情感分析等任务。下面是一个使用`spaCy`进行命名实体识别的简单例子:
```python
import spacy
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
text = "Apple is looking at buying U.K. startup for $1 billion"
# 处理文本
doc = nlp(text)
# 输出每个实体及其类型
for ent in doc.ents:
print(ent.text, ent.label_)
```
在这个代码块中,我们加载了`spaCy`的英文小模型,并使用它来处理一段文本。`doc.ents`包含了识别出的命名实体,我们可以遍历它们并打印出来。这种技术在清洗包含人名、地点、组织等实体的文本时非常有用。
### 3.2.3 大数据清洗框架(如Apache NiFi)
大数据清洗框架如Apache NiFi提供了一个易于使用的、功能强大的用户界面来设计数据流。NiFi支持实时数据处理、数据路由以及强大的流控制和监控功能,特

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨文本挖掘的各个方面,从入门基础到高级应用。它提供了一系列全面的文章,涵盖了核心技巧、行业案例和算法实践。从文本分类、实体识别和信息抽取,到主题建模、机器学习和文本数据清洗,专栏涵盖了文本挖掘的各个领域。此外,它还探讨了文本挖掘的艺术、挑战和机遇,并提供了文本相似度计算、文本摘要技术和聚类分析等高级技术。通过深入的分析和实际案例,本专栏旨在帮助读者掌握文本挖掘的精髓,成为非结构化数据的大师。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
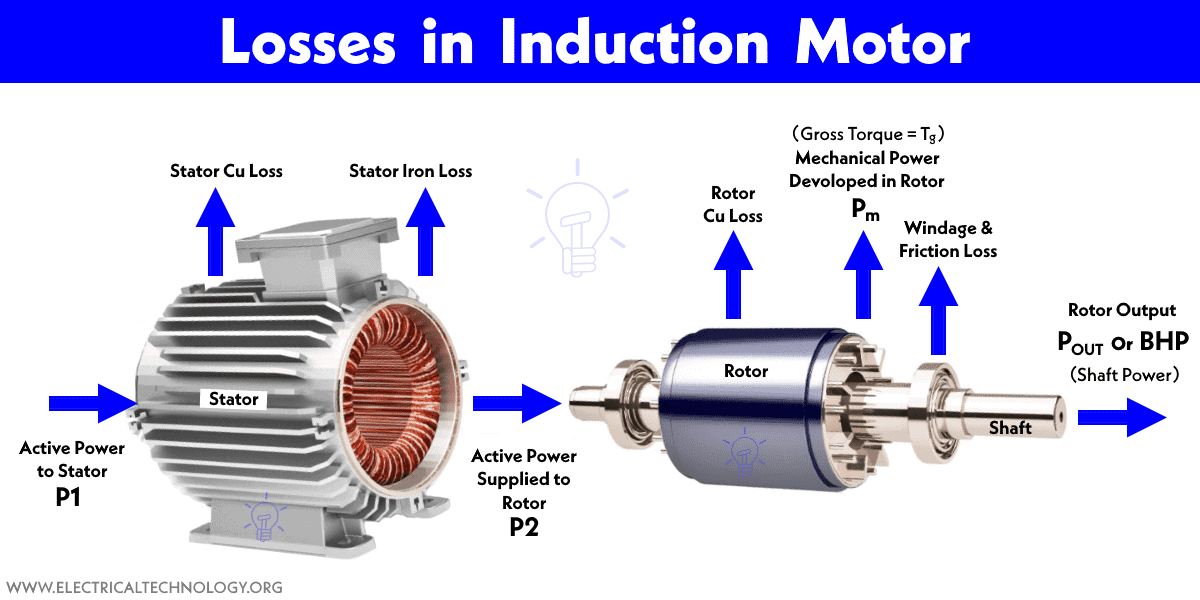
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
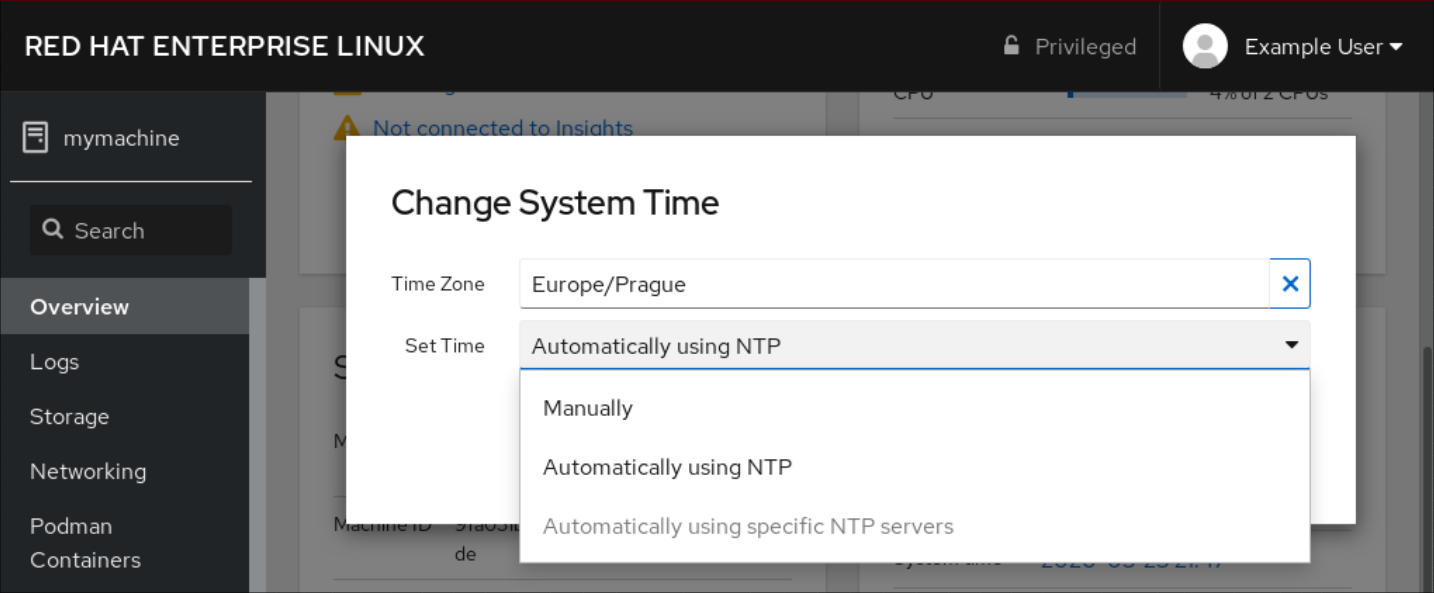
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )