【Transformer模型优化方法与技巧总结】: 总结Transformer模型的优化方法与技巧
发布时间: 2024-04-20 11:07:20 阅读量: 110 订阅数: 105 

优化模型 系统介绍了优化模型的求解方法
# 1. Transformer模型简介
在深度学习领域,Transformer模型作为一种革命性的序列到序列模型,已经在自然语言处理等任务中取得了巨大成功。它的核心思想是自注意力机制,能够在不依赖于循环神经网络(RNN)和卷积神经网络(CNN)的情况下,有效地捕捉输入序列的全局依赖关系。其结构简单,易于并行化训练,使得在处理长序列时具有明显的优势。Transformer模型的出现,彻底改变了传统序列建模的格局,为自然语言处理任务注入了新的活力和效率。
# 2.1 什么是Transformer模型
Transformer模型是一种基于注意力机制的深度学习模型,最初由Vaswani等人于2017年提出。相比传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer模型在处理序列数据时表现出色。在深入探讨Transformer模型之前,让我们首先了解其中关键的 Self-Attention 机制。
### 2.1.1 Self-Attention 机制解析
Self-Attention 机制是Transformer模型的核心组成部分之一,通过计算输入序列各个位置之间的相互作用来捕捉长距离依赖关系。具体而言,Self-Attention机制允许模型在计算每个输出位置时,关注输入序列中所有位置的信息,并根据它们的相关性赋予不同的权重。
下面是Self-Attention的计算过程:
```python
# Self-Attention计算过程示例
query = 输入序列
key = 输入序列
value = 输入序列
attention_scores = softmax(query * key.T / sqrt(d_k)) # 计算注意力分数
output = attention_scores * value # 得到Self-Attention输出
```
### 2.1.2 Transformer编码器和解码器
Transformer 模型由编码器和解码器组成,两者分别用于处理输入序列和生成输出序列。编码器由多个相同结构的层堆叠而成,每个层包括一个 Self-Attention 子层和一个前馈神经网络子层。解码器也由堆叠的层组成,每层包括一个 Self-Attention 子层、一个编码器-解码器注意力子层和一个前馈神经网络子层。
在Transformer中,编码器将输入序列编码成一系列高维向量表示,解码器则根据这些向量生成目标序列。
## 相关文章
- Transformer模型详解:https://example.com/transformer
- Self-Attention 机制解析:https://example.com/self-attention
本章节详细介绍了Transformer模型的基本原理,包括Self-Attention机制和编码器解码器结构。在下一节中,我们将探讨Transformer模型的优势所在。
# 3. Transformer模型的优化方法
Transformer模型的优化是在训练和推理过程中对模型性能进行提升的关键环节。本章将介绍Transformer模型的优化方法,包括学习率调度策略和注意力机制优化。
### 3.1 学习率调度策略
在训练神经网络时,学习率的设置对模型的收敛速度和性能至关重要。Transformer模型也不例外,下面将介绍几种常见的学习率调度策略。
#### 3.1.1 Warmup策略
**Warmup策略**是指在训练初期将学习率逐渐增加到一个较高的初始值,然后再按照原来的学习率调度策略进行训练。这种策略可以帮助模型更快地找到合适的参数区域,并加速收敛的过程。
具体实现代码如下:
```python
# 设置初始学习率
initial_lr = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=initial_lr)
# Warmup策略
def adjust_learning_rate(optimizer, step_num, warmup_steps=1000):
lr = initial_lr * min(step_num ** (-0.5), step_num * warmup_steps ** (-1.5))
for param_group in
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 Transformer 模型的方方面面,涵盖了从原理解析到应用场景、从常见问题解决方案到超参数调优技巧,以及在不同领域的应用案例分析。专栏还探讨了 Transformer 模型与其他模型的对比分析、可解释性、大规模数据集表现、参数量化、移动端部署优化、低资源环境应用等方面。此外,专栏还介绍了 Transformer 模型的技术生态系统、工具、实际部署经验和未来发展趋势,为读者提供了全面的 Transformer 模型知识体系。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度分析】:Windows 11非旺玖PL2303驱动问题的终极解决之道
# 摘要
随着Windows 11操作系统的推出,PL2303芯片及其驱动程序的兼容性问题逐渐浮出水面,成为技术维护的新挑战。本文首先概述了Windows 11中的驱动问题,随后对PL2303芯片的功能、工作原理以及驱动程序的重要性进行了理论分析。通过实例研究,本文深入探讨了旺玖PL2303驱动问题的具体案例、更新流程和兼容性测试,并提出了多种解决和优化方案。文章最后讨论了预防措施和对Windows 11驱动问题未来发展的展望,强调了系统更新、第三方工具使用及长期维护策略的重要性。
# 关键字
Windows 11;PL2303芯片;驱动兼容性;问题分析;解决方案;预防措施
参考资源链接:
【Chem3D个性定制教程】:打造独一无二的氢原子与孤对电子视觉效果

# 摘要
Chem3D软件作为一种强大的分子建模工具,在化学教育和科研领域中具有广泛的应用。本文首先介绍了Chem3D软件的基础知识和定制入门,然后深入探讨了氢原子模型的定制技巧,包括视觉定制和高级效果实现。接着,本文详细阐述了孤对电子视觉效果的理论基础、定制方法和互动设计。最后,文章通过多个实例展示了Chem3D定制效果在实践应用中的重要性,并探讨了其在教学和科研中的
【网格工具选择指南】:对比分析网格划分工具与技术
# 摘要
本文全面综述了网格划分工具与技术,首先介绍了网格划分的基本概念及其在数值分析中的重要作用,随后详细探讨了不同网格类型的选择标准和网格划分算法的分类。文章进一步阐述了网格质量评估指标以及优化策略,并对当前流行的网格划分工具的功能特性、技术特点、集成兼容性进行了深入分析。通过工程案例的分析和性能测试,本文揭示了不同网格划分工具在实际应用中的表现与效率。最后,展望了网格划分技术的未来发展趋势,包括自动
大数据分析:处理和分析海量数据,掌握数据的真正力量

# 摘要
大数据是现代信息社会的重要资源,其分析对于企业和科学研究至关重要。本文首先阐述了大数据的概念及其分析的重要性,随后介绍了大数据处理技术基础,包括存储技术、计算框架和数据集成的ETL过程。进一步地,本文探讨了大数据分析方法论,涵盖了统计分析、数据挖掘以及机器学习的应用,并强调了可视化工具和技术的辅助作用。通过分析金融、医疗和电商社交媒体等行
内存阵列设计挑战
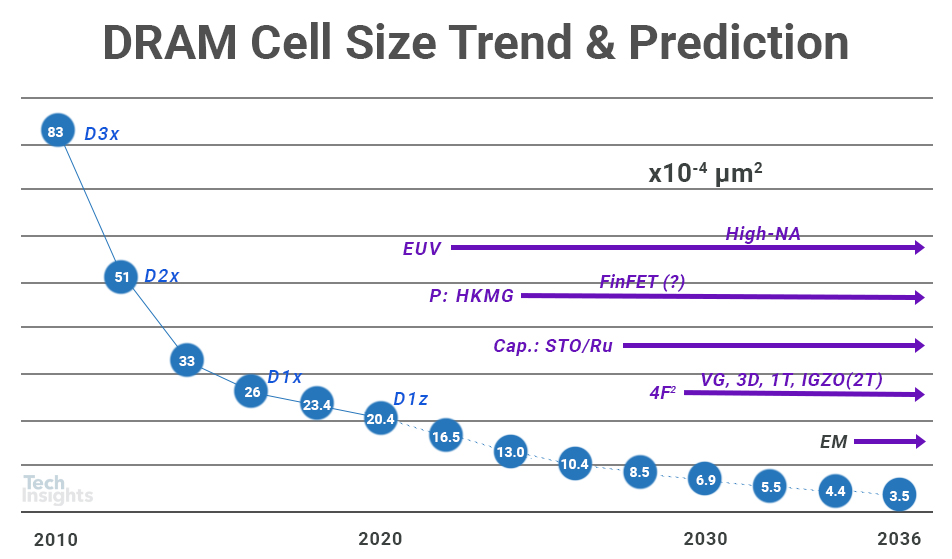
# 摘要
内存阵列技术是现代计算机系统设计的核心,它决定了系统性能、可靠性和能耗效率。本文首先概述了内存阵列技术的基础知识,随后深入探讨了其设计原理,包括工作机制、关键技术如错误检测与纠正技术(ECC)、高速缓存技术以及内存扩展和多通道技术。进一步地,本文关注性能优化的理论和实践,提出了基于系统带宽、延迟分析和多级存储层次结构影响的优化技巧。可靠性和稳定性设计的策略和测试评估方法也被详细分析,以确保内存阵列在各
【网络弹性与走线长度】:零信任架构中的关键网络设计考量

# 摘要
网络弹性和走线长度是现代网络设计的两个核心要素,它们直接影响到网络的性能、可靠性和安全性。本文首先概述了网络弹性的概念和走线长度的重要性,随后深入探讨了网络弹性的理论基础、影响因素及设
天线技术实用解读:第二版第一章习题案例实战分析

# 摘要
本论文回顾了天线技术的基础知识,通过案例分析深入探讨了天线辐射的基础问题、参数计算以及实际应用中的问题。同时,本文介绍了天
音频处理中的阶梯波发生器应用:技术深度剖析与案例研究

# 摘要
阶梯波发生器作为电子工程领域的重要组件,广泛应用于音频合成、信号处理和测试设备中。本文从阶梯波发生器的基本原理和应用出发,深入探讨了其数学定义、工作原理和不同实现方法。通过对模拟与数字电路设计的比较,以及软件实现的技巧分析,本文揭示了在音频处理领域中阶梯波独特的应用优势。此外,本文还对阶梯波发生器的
水利工程中的Flac3D应用:流体计算案例剖析

# 摘要
本文深入探讨了Flac3D在水利工程中的应用,详细介绍了Flac3D软件的理论基础、模拟技术以及流体计算的实践操作。首先,文章概述了Flac3D软件的核心原理和基本算法,强调了离散元方法(DEM)在模拟中的重要性,并对流体计算的基础理论进行了阐述。其次,通过实际案例分析,展示了如何在大坝渗流、地下水流动及渠道流体动力学等领域中建立模型、进行计算
【Quartus II 9.0功耗优化技巧】:降低FPGA功耗的5种方法

# 摘要
随着高性能计算需求的不断增长,FPGA因其可重构性和高性能成为众多应用领域的首选。然而,FPGA的功耗问题也成为设计与应用中的关键挑战。本文从FPGA功耗的来源和影响因素入手,详细探讨了静态功耗和动态功耗的类型、设计复杂性与功耗之间的关系,以及功耗与性能之间的权衡。本文着重介绍并分析了Quartus II功耗分析工具的使用方法,并针对降低FPGA功耗提出了一系列优化技巧。通过实证案
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )