【移动应用中的HAR文件应用】:提高网络体验的革命性方法
发布时间: 2024-10-27 20:36:46 阅读量: 36 订阅数: 45 
# 1. 移动应用中的网络性能问题概述
在当今数字化转型的时代,移动应用已成为人们日常生活中不可或缺的一部分。然而,随着用户对移动应用性能的要求日益提高,网络性能问题成了开发者和性能优化工程师亟待解决的关键难题。移动应用中的网络性能问题不仅影响用户体验,还可能直接导致用户流失。本章将从移动应用的网络性能问题出发,探讨这些问题背后的原因、表现形式以及它们对用户产生的影响,为后续章节中HAR文件的应用和网络优化打下基础。
# 2. HAR文件基础与生成机制
HAR文件是网络性能分析和优化中不可或缺的工具,它记录了网页加载过程中发生的网络请求和响应的详细信息。本章节深入探讨HAR文件的定义、结构、生成以及数据解读,为后续的性能优化和监控奠定基础。
## 2.1 HAR文件定义和结构
### 2.1.1 HAR文件的起源和应用背景
HAR(HTTP Archive)文件由网络浏览器自动化测试工具WebPagetest的开发者提出,旨在记录和分析网页加载过程中的HTTP交互数据。HAR文件以其标准化和易于解析的特性,成为了性能工程师和开发人员分析和优化移动应用性能的重要手段。
### 2.1.2 HAR文件标准格式解析
HAR文件遵循JSON格式,由一系列嵌套的键值对组成。文件本身以一个根对象开始,包含一个`log`对象,该对象记录了浏览器的版本、设备类型、页面加载时间、网络类型、HTTP请求和响应列表等信息。每一个请求和响应都被详细记录,包括时间戳、请求头、响应头、内容大小、缓存状态等。
## 2.2 HAR文件的生成工具和方法
### 2.2.1 浏览器内置工具生成HAR文件
大多数现代浏览器,包括Chrome、Firefox和Safari,都内置了开发者工具,这些工具可以用来生成HAR文件。例如,在Chrome浏览器中,可以通过访问“开发者工具”>“网络”标签页,录制网页加载过程,并选择“保存为 HAR”,将网络活动保存为HAR文件。
### 2.2.2 移动应用中生成HAR文件的库与API
对于移动应用,开发者可以使用诸如Wireshark、Fiddler或Charles等专业工具来捕获应用的HTTP流量并导出为HAR文件。在应用的代码中集成这些库,或者使用代理设置,可以让应用在运行时生成HAR文件,这对于分析应用在真实设备上的性能尤为重要。
### 2.2.3 使用开发者工具和模拟器收集HAR数据
开发者可以利用Android Studio和Xcode等官方开发环境提供的开发者工具和模拟器来捕获网络数据。例如,在Android Studio中,通过"连接调试器"或"Android监视器"捕获网络流量,并将其保存为HAR文件。类似地,iOS开发者可以使用Xcode内置的网络功能来完成这一任务。
## 2.3 HAR文件的数据解读
### 2.3.1 分析网络请求和响应的结构
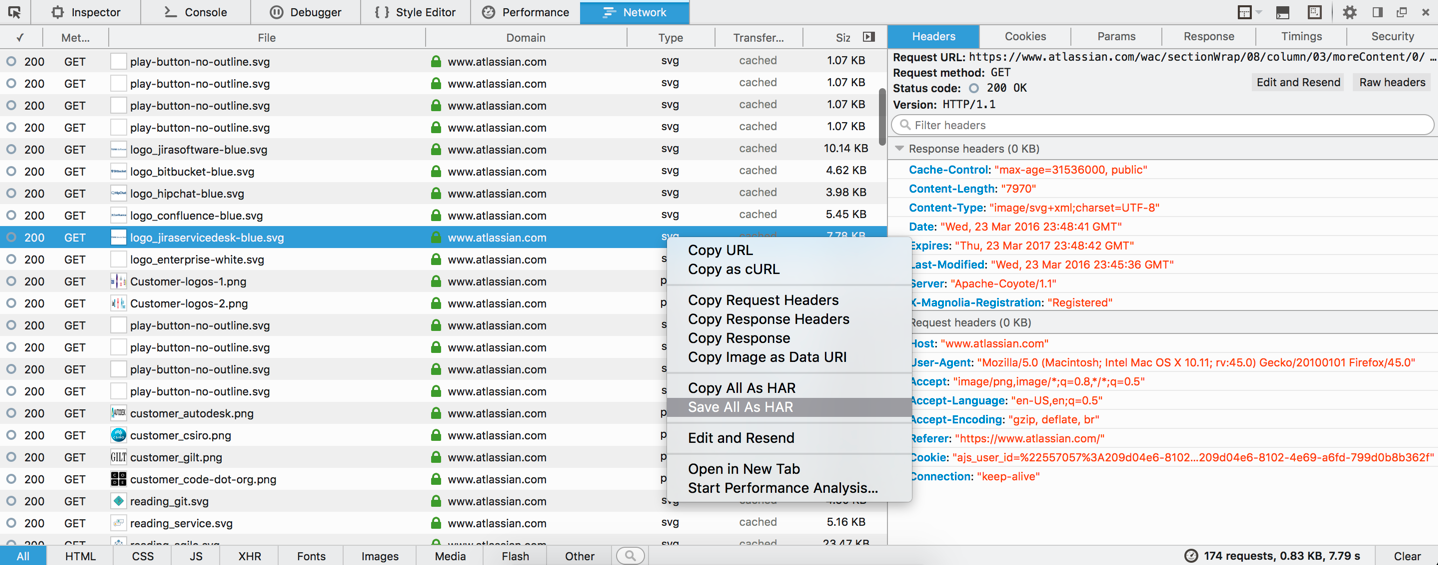
HAR文件中记录的每个条目都表示一次网络请求和响应。通过分析请求和响应的结构,我们可以看到请求的发起时间、请求方法(如GET或POST)、请求URL、请求头、响应状态码、响应类型和大小等。这些信息有助于理解请求的完整性和成功性。
### 2.3.2 从HAR文件中提取关键性能指标
HAR文件中的数据可以用来计算多个关键性能指标,如请求延迟时间、总下载时间、缓存使用情况和数据传输效率等。这些指标对于评估应用性能至关重要,可以帮助开发者发现性能瓶颈并指导优化工作。
## 代码块:解析HAR文件
以下是一个Python脚本示例,该脚本使用`json`库解析HAR文件,并提取网络请求和响应的关键信息。
```python
import json
def parse_har_file(file_path):
with open(file_path, 'r') as ***
***
***['log']
entries = log['entries']
for entry in entries:
request = entry['request']
response = entry['response']
# 提取关键信息
request_url = request['url']
request_time = entry['time']
response_status = response['status']
response_size = response['bodySize']
print(f"Request URL: {request_url}")
print(f"Request Time: {request_time}")
print(f"Response Status: {response_status}")
print(f"Response Size: {response_size}")
# 使用示例
parse_har_file('example.har')
```
### 参数说明
- `file_path`: HAR文件的路径。
- `log`: HAR文件中的根对象,包含了所有捕获的网络活动。
- `entries`: 请求和响应条目的列表。
### 逻辑分析
上述脚本首先打开HAR文件,并使用`json.load`方法将其内容加载为一个Python字典对象。随后,它遍历`log`对象中的`entries`列表,对每一个条目中的`request`和`response`字段进行解析,并打印出URL、请求时间、响应状态码和响应体大小等关键信息。
通过执行上述脚本,开发者可以快速获得HAR文件中的重要数据,为性能分析和优化提供有价值的信息。
# 3. HAR文件在网络优化中的实践应用
## 3.1 网络请求分析与问题定位
### 3.1.1 识别和诊断网络请求延迟
在移动应用的开发和维护过程中,网络请求延迟是常见的性能瓶颈。通过分析HAR文件,可以有效识别造成延迟的主要因素。HAR记录了每一个网络请求的时间戳、耗时、状态码等信息,因此可以将请求的总耗时与服务器响应时间进行对比,从而定位出是网络延迟还是服务器处理延迟。
分析HAR文件时,重点关注以下几个关键点:
1. **请求发起时间**和**接收时间**:这两个时间点可以用来计算请求的响应时间。
2. **服务器处理时间**:这是服务器处理请求所花费的时间,它与响应时间的差异可以帮助我们判断网络延迟。
3. **内容加载时间**:这个时间是用户感受到的延迟,包括了网络传输时间和服务器处理时间。
通过代码块可以更直观地展示如何从HAR文件中提取这些信息:
```json
[
{
"startedDateTime": "2023-04-01T00:00:00.000Z",
"time": 800,
"request": {
"method": "GET",
"url": "***",
"headers": []
},
"response": {
"status": 200,
"statusText": "OK",
"headers": []
},
"cache": {},
" timings": {
"blocked": 200,
"dns": 100,
"connect": 150,
"send": 50,
"wait": 200,
"receive": 100
}
}
]
```
每个请求条目中的`timings`字段包含了详细的计时信息,通过分析这些信息,开发者可以较为准确地确定网络请求的瓶颈所在。例如,如果`connect`和`blocked`的时间较长,可能意味着网络连接慢或者有域名解析的问题;如果`wait`时间长,那么可能是服务器处理请求的速度较慢。
### 3.1.2 确定移动应用中的性能瓶颈
性能瓶颈可能是由多种因素造成的,例如网络环境不稳定、服务器响应慢、数据传输量过大或者移动设备的处理能力不足。通过HAR文件,我们可以从多个维度对性能瓶颈进行分析。
以下是HAR文件中可能包含的关键性能指标:
- **请求数量**:如果请求数量过多,可能会导致网络拥堵。
- **数据传输量**:传输的数据量越大,通常意味着加载时间越长。
- **缓存命中率**:通过查看HAR文件中的缓存状态,可以评估应用对于缓存的利用效果。
- **第三方资源的加载**:第三方资源可能会影响加载速度,尤其是当它们的服务器响应时间较长或不稳定时。
在处理性能瓶颈时,开发者需根据HAR文件提供的详细信息,确定瓶颈的类型,并根据瓶颈性质采取相应的优化措施。例如,如果发现数据传输量过大,可以考虑压缩图片、使用WebP格式资源、减少JavaScript或CSS的大小等方法来优化。
## 3.2 网络优化策略实施
### 3.2.1 图片和资源的压缩与优化
移动应用中通常会包含大量的图片和资源文件,这些文件的大小直接关联到应用的加载速度。优化这些资源可以减少网络请求的总数据量,从而提高应用性能。
- **压缩图片**:使用工具如TinyPNG或JPEGmini对图片进行压缩,减少文件大小但尽量保持质量。
- **优化代码资源**:对于JavaScript和CSS文件,可以使用如UglifyJS或CSSNano这类工具进行压缩和优化。
- **使用图标字体**:相比图标图片,图标字体文件小且可轻易调整大小颜色,适合用于表示小图标。
- **懒加载**:对于非首屏图片或资源,可以实现懒加载,即在需要的时候才加载,减少初次加载时间。
实施以上策略后,要生成新的HAR文件,比较前后加载时间以及数据传输量的差异,以评估优化效果。
### 3.2.2 CDN使用与缓存策略的调整
内容分发网络(CDN)可以帮助分散服务器的负载,并将资源缓存到离用户更近的地理位置,从而缩短响应时间。
- **选择合适的CDN提供商**:不同的CDN服务商可能在不同地区的覆盖能力和速度上有所差异,需根据用户群体的具体分布选择最合适的CDN提供商。
- **缓存策略**:合理配置缓存头(如`Cache-Control`),确保资源被缓存到浏览器或CDN,减少对服务器的不必要请求。
- **智能路由**:部分CDN支持基于网络状况的智能路由,自动将用户的请求路由到最优节点。
通过HAR文件可以验证缓存策略是否有效,例如通过检查`Cache-Control`字段和缓存命中率(`from cache`)等信息。
### 3.2.3 代码和资源的优化加载

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
HAR使用注意事项与缺陷专栏全面探讨了HAR(HTTP档案)的使用技巧、常见陷阱和最佳实践。专栏涵盖广泛主题,包括:
* HAR文件深入分析和数据提取技术
* 避免HAR数据处理错误解读的策略
* 利用HAR数据优化网络性能和用户体验
* 保护HAR数据敏感信息的实践
* HAR文件故障诊断和案例分析
* HAR文件解析工具对比和选择
* HAR数据管理方案的优化策略
* HAR文件在移动应用中的应用
* HAR文件的替代方案和自动化处理技巧
* HAR文件与网络负载生成技巧
* 专家深度剖析HAR数据分析的挑战和前沿探索
该专栏为网络性能分析人员、开发人员和用户体验优化专家提供了全面的指南,帮助他们有效利用HAR数据提升网络体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【高斯数据库驱动终极指南】:深入掌握GaussDB驱动技术及其最佳实践
# 摘要
高斯数据库驱动作为数据库连接与操作的关键组件,其架构的复杂性和性能优化对于数据库应用至关重要。本文首先对高斯数据库驱动进行概览,详细介绍其架构组件、连接管理、事务处理机制等基础要素。随后,文章深入探讨了驱动开发实践,包括开发环境搭建、核心API实现以及测试与质量保证策
PageMesh性能优化秘技:高级应用轻松提高性能的秘诀

# 摘要
本文对PageMesh性能优化进行了系统性的分析和讨论。第一章概述了性能优化的重要性及其在PageMesh系统中的应用。第二章探讨了性能优化的理论基础、PageMesh架构分析以及性能调优的理论模型,为读者提供了深入理解PageMesh性能瓶颈和优化策略的基础
【MySQL数据恢复秘籍】:专家教你如何在数据丢失后迅速找回

# 摘要
随着信息技术的快速发展,数据成为企业和个人最为宝贵的资产之一。MySQL作为广泛使用的开源数据库管理系统,其数据恢复的重要性日益凸显。本文深入探讨了MySQL数据恢复的必要性与面临的挑战,并系统分析了数据存储与备份机制。通过
深入解码:Windows Server 2008 R2 USB3.0支持的秘密与限制

# 摘要
本文针对Windows Server 2008 R2环境下USB3.0的支持进行了全面的探讨。首先概述了USB3.0技术标准及其在Windows Server 2008 R2中的理论基础,包括技术发展历程、核心特性和系统架构支持。随后,文章详细介绍了USB
机器学习模型选择宝典:如何根据问题类型一击即中
# 摘要
随着数据科学与人工智能技术的快速发展,机器学习模型选择与应用已成为数据挖掘和智能分析的关键。本文系统介绍了机器学习模型选择的基本原理,涵盖了监督学习和无监督学习模型的选取、性能评估和调优实
【CST仿真:精通边界条件】:新手到专家的必修之路

# 摘要
本文系统回顾了CST仿真中的边界条件基础知识,并深入探讨了边界条件的理论基础、在实践操作中的应用、高级应用案例分析,以及理论深化等方面。通过分析边界条件的类型、数学模型和物理意义,本文强调了在CST仿真中正确设置和优化边界条件的重要性。文章进一步介绍了边界条件在复杂结构和特殊问题中的应用,并提供了多个案例实操演练,以此帮助仿真新手逐步提升至专家水平。最后,文
【深入探索LVDS技术】:从起源到现代应用,一文掌握接口标准发展史

# 摘要
本文系统地探讨了低压差分信号(LVDS)技术的发展历程、应用实践及面临的挑战与未来趋势。首先介绍了LVDS技术的起源和基本原理,以及其标准的演进,包括早期标准的定义、变迁和新技术的融合。随后,文章详细阐述了LVDS在显示技术、通信行业和工业自动化领域的广泛应用,以及这些应用背后的实践案例。最后,本文分析了LVDS技术目前面临的挑战
ABB机器人IRB660:快速掌握基础操作的终极指南

# 摘要
本文全面介绍了ABB机器人IRB660系列,涵盖了从硬件组成到高级应用的各个方面。首先,对IRB660进行了概览,包括其硬件组件与操作面板。接着,介绍了基础编程与调试技巧,涵盖了RAPID编程语言及其在实际操作中的应用。在实际操作与应用章节,本文详述了
Tamarin-Prover概念精讲:详解状态、动作与推导规则
# 摘要
本文综述了Tamarin-Prover在形式化方法中的应用和理论基础。首先,介绍了Tamarin-Prover的基本概念和状态与动作的形式化描述,涵盖状态的定义、动作的分类以及它们之间的关系。其次,探讨了推导规则的类型、语法、有效性和完备性,以及在理论上的应用和实例分析。此外,本文深入分析了Tamarin-Prover在协议分析和安全协议中的实际应用,包括协议建模、验证属性和案例研究。最后,评述了Tamarin-Prover当前面临的技术挑战和未来研究方向,展望了安全协议分析领域的发展趋势和潜在技术进步。
# 关键字
Tamarin-Prover;形式化方法;状态与动作;推导规则;
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )