【HAR数据可视化入门】:网络性能关键数据的直观展示法
发布时间: 2024-10-27 20:24:51 订阅数: 7 

# 1. HAR数据及其重要性
## 1.1 HAR数据概述
HAR数据,即HTTP Archive格式数据,最初用于记录和存储网页加载过程中的所有网络活动。它是网络性能分析和优化不可或缺的基础信息源。HAR文件记录了网络请求的详细时间线,包括每个请求的发起时间、响应时间以及加载过程中的所有细节。它为开发者提供了一个统一且标准化的方式来存储、分享和分析网站性能数据。
## 1.2 HAR数据的重要性
HAR数据的重要性体现在它能够帮助开发者、运维人员和网站所有者从细节层面理解网站性能。通过分析HAR数据,我们可以洞察加载时间、资源消耗、缓存利用以及可能存在的性能瓶颈。此外,HAR数据在调试、性能优化和用户体验改进等方面也扮演着关键角色。它还可以作为性能测试和监控的基础,帮助团队在开发周期中早期识别和解决性能问题。
## 1.3 HAR数据与性能优化
HAR数据提供了网站性能的量化指标,允许开发者对性能进行精确的测量和比较。通过HAR分析,可以发现哪些资源加载时间较长,哪些操作拖慢了网站速度,甚至可以细化到单个资源的加载时间。结合性能优化的最佳实践,如优化图片大小、合并CSS/JS文件、使用CDN等,利用HAR数据可以制定出针对性的优化策略,从而显著提升网站的加载速度和用户体验。
# 2. HAR数据可视化基础
## 2.1 理解HAR文件格式
### 2.1.1 HAR文件结构解析
HAR(HTTP Archive)文件是一个记录Web浏览器和服务器之间交互的JSON格式文件。它为Web开发者提供了一个跟踪浏览器活动的标准方式,帮助开发者分析网络请求的性能。一个典型的HAR文件包括`log`对象,其中包含了关于网络活动的详细信息。
下面展示了一个简化的HAR文件结构:
```json
{
"log": {
"version": "1.2",
"creator": {
"name": "HAR Creator",
"version": "1.0"
},
"browser": {
"name": "Chrome",
"version": "79.0"
},
"pages": [
{
"startedDateTime": "2023-03-15T06:00:00.000Z",
"id": "page_1",
"title": "Example Web Page"
}
],
"entries": [
{
"pageref": "page_1",
"startedDateTime": "2023-03-15T06:00:00.123Z",
"time": 42.749,
"request": {
"method": "GET",
"url": "***",
"httpVersion": "HTTP/1.1",
"cookies": [],
"headers": [],
"queryStrings": []
},
"response": {
"status": 200,
"statusText": "OK",
"httpVersion": "HTTP/1.1",
"cookies": [],
"headers": [],
"content": {
"size": 256,
"mimeType": "text/html"
}
},
"cache": {},
"timings": {
"blocked": 0,
"dns": 0,
"connect": 0,
"send": 0.123,
"wait": 42.626,
"receive": 0,
"ssl": 0
}
}
]
}
}
```
### 2.1.2 数据字段详解
HAR文件包含多个关键字段,可以细分为以下几种类型:
- **元信息字段**:例如`log.version`和`log.creator`提供了关于HAR格式版本和创建这个HAR文件的软件信息。
- **浏览器和页面信息**:`log.browser`和`log.pages`提供了浏览器的详细信息和被请求的页面信息。
- **请求与响应记录**:核心数据存储在`log.entries`中,每一个条目记录了一个单独的HTTP请求和响应。
每个请求和响应包含多个子字段,如`request`和`response`字段中包含方法、URL、状态码等,`timings`字段提供了请求各阶段的时间信息,比如等待时间、发送时间等。
### 2.1.3 代码块解读
对于开发者来说,从HAR文件中提取数据并进行可视化分析是至关重要的。下面的Python代码展示了如何读取和解析HAR文件:
```python
import json
# 读取HAR文件内容
with open('example.har', 'r') as ***
***
* 获取log对象
log_data = har_data['log']
# 获取所有entries
entries = log_data['entries']
# 对于每一个entry进行处理
for entry in entries:
# 获取请求和响应信息
request = entry['request']
response = entry['response']
# 输出请求方法和响应状态码
print(f"Request Method: {request['method']}, Response Status: {response['status']}")
```
以上代码块首先导入了json模块,使用`with open`语句读取HAR文件,然后将内容加载为Python字典。之后,通过访问字典中的'log'键值获取log对象,并遍历其中的`entries`列表,对于每个条目打印出请求方法和响应状态码。
## 2.2 数据可视化理论
### 2.2.1 数据可视化的意义
数据可视化是将数据转换为图形或图像的过程,使人们能够更直观地理解数据的模式、趋势和异常情况。对HAR文件进行可视化,可以帮助开发者快速地识别网络性能瓶颈,例如哪些请求导致延迟,或者哪些资源的加载时间最长。
### 2.2.2 常见的数据可视化类型
根据HAR数据的特性,常见的数据可视化类型包括:
- **条形图**:适合展示每个请求的加载时间或者请求的大小。
- **折线图**:能够表示随时间变化的趋势,例如页面加载时间随时间的变化。
- **散点图**:可以展示请求时间和响应时间之间的关系。
- **饼图和圆环图**:用于展示比例关系,例如不同类型请求的比例。
- **热图**:可以直观地展示加载时间的分布情

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
HAR使用注意事项与缺陷专栏全面探讨了HAR(HTTP档案)的使用技巧、常见陷阱和最佳实践。专栏涵盖广泛主题,包括:
* HAR文件深入分析和数据提取技术
* 避免HAR数据处理错误解读的策略
* 利用HAR数据优化网络性能和用户体验
* 保护HAR数据敏感信息的实践
* HAR文件故障诊断和案例分析
* HAR文件解析工具对比和选择
* HAR数据管理方案的优化策略
* HAR文件在移动应用中的应用
* HAR文件的替代方案和自动化处理技巧
* HAR文件与网络负载生成技巧
* 专家深度剖析HAR数据分析的挑战和前沿探索
该专栏为网络性能分析人员、开发人员和用户体验优化专家提供了全面的指南,帮助他们有效利用HAR数据提升网络体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【高级配置选项】:Hadoop CombineFileInputFormat高级配置选项深度解析
# 1. Hadoop CombineFileInputFormat概述
## 1.1 Hadoop CombineFileInputFormat简介
Hadoop CombineFileInputFormat是Apache Hadoop中的一个输入格式类,它在处理大量小文件时表现优异,因
HDFS文件写入数据副本策略:深度解析与应用案例
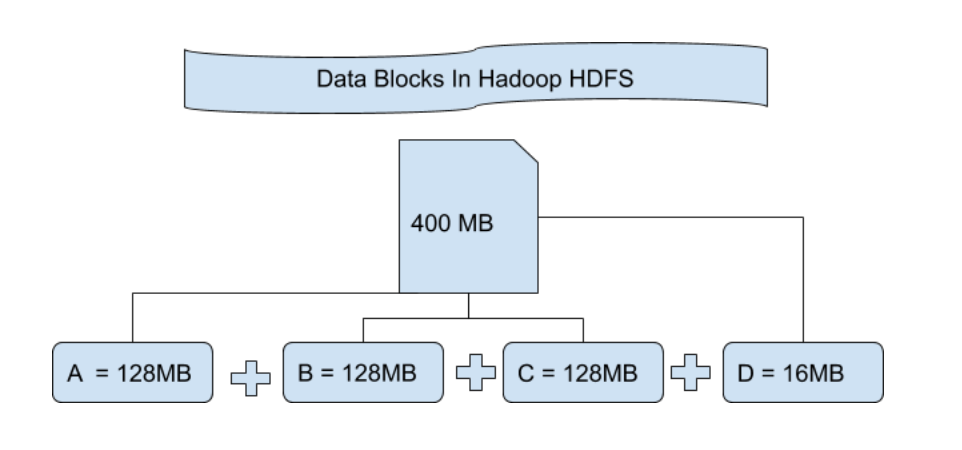
# 1. HDFS文件系统概述
在大数据时代背景下,Hadoop分布式文件系统(HDFS)作为存储解决方案的核心组件,为处理大规模数据集提供了可靠的框架。HDFS设计理念是优化存储成本,而不是追求低延迟访问,因此它非常适合批量处理数据集的应用场景。它能够存储大量的数据,并且能够保证数据的高可靠性,通过将数据分布式地存储在低成本硬件上。
HDFS通过将大文件分割为固定大小的数据块(b
【升级至Hadoop 3.x】:集群平滑过渡到新版本的实战指南
# 1. Hadoop 3.x新特性概览
Hadoop 3.x版本的发布,为大数据处理带来了一系列的革新和改进。本章将简要介绍Hadoop 3.x的一些关键新特性,以便读者能快速把握其核心优势和潜在的使用价值。
## 1.1 HDFS的重大改进
在Hadoop 3.x中,HDFS(Hadoop Distributed File System)得到了显著的增强
Hadoop Archive数据安全:归档数据保护的加密与访问控制策略

# 1. Hadoop Archive数据安全概述
在数字化时代,数据安全已成为企业与组织关注的核心问题。特别是对于大数据存储和分析平台,如Hadoop Archive,数据安全更是关键。本章节将简述Hadoop Archive的基本概念,并概述数据安全的相关内容,为后续深入探讨Hadoop Archive中数据加密技术和访问控制策略打下基础。
## 1
【Hadoop存储优化】:列式存储与压缩技术对抗小文件问题
# 1. Hadoop存储优化的背景与挑战
在大数据处理领域,Hadoop已成为一个不可或缺的工具,尤其在处理大规模数据集方面表现出色。然而,随着数据量的激增,数据存储效率和查询性能逐渐成为制约Hadoop性能提升的关键因素。本章我们将探讨Hadoop存储优化的背景,分析面临的挑战,并为后续章节列式存储技术的应用、压缩技术的优化、小文件问题的解决,以及综合案例研究与展望提供铺垫
Hadoop序列文件的演化:从旧版本到新特性的深度分析

# 1. Hadoop序列文件简介
在大数据处理领域,Hadoop作为领先的开源框架,为存储和处理海量数据集提供了强大的支持。序列文件是Hadoop中用于存储键值对的一种二进制文件格式,它允许高效的顺序读写操作,是处理大规模数据时不可或缺的组件之一。随着Hadoop技术的发展,序列文件也不断演化,以满足更复杂的业务需求。本文将从序列文件的基础知识讲起,逐步深入到其数据模型、编码机制,以及在新特性中的应
Hadoop在机器学习中的应用:构建高效的数据分析流程
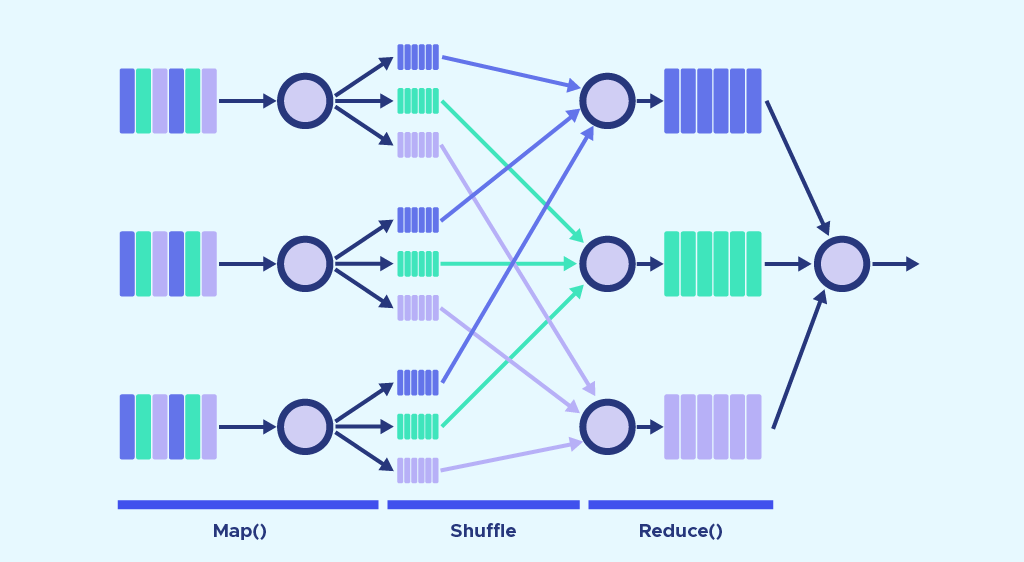
# 1. Hadoop与机器学习简介
## 1.1 Hadoop的起源与定义
Hadoop是由Apache软件基金会开发的一个开源框架,它的出现源于Google发表的三篇关于大规模数据处理的论文,分别是关于GFS(Google File System)、MapReduce编程模型和BigTable的数据模型。Hadoop旨在提供一个可靠、可扩展的分布式系统基础架构,用
【HAR文件与网络负载生成技巧】:真实网络场景模拟的艺术

# 1. HAR文件与网络负载生成概述
在现代的IT领域中,HAR文件(HTTP Archive Format)扮演着记录网络交互细节的重要角色,而网络负载生成则是软件测试和网络性能分析中不可或缺的一环。本章将简要介绍HAR文件的基本概念,以及它在网络负载生成中的关键作用,为理解后续章节奠定基础。
## 1.1
【HDFS权威指南】:数据块管理与复制策略揭秘
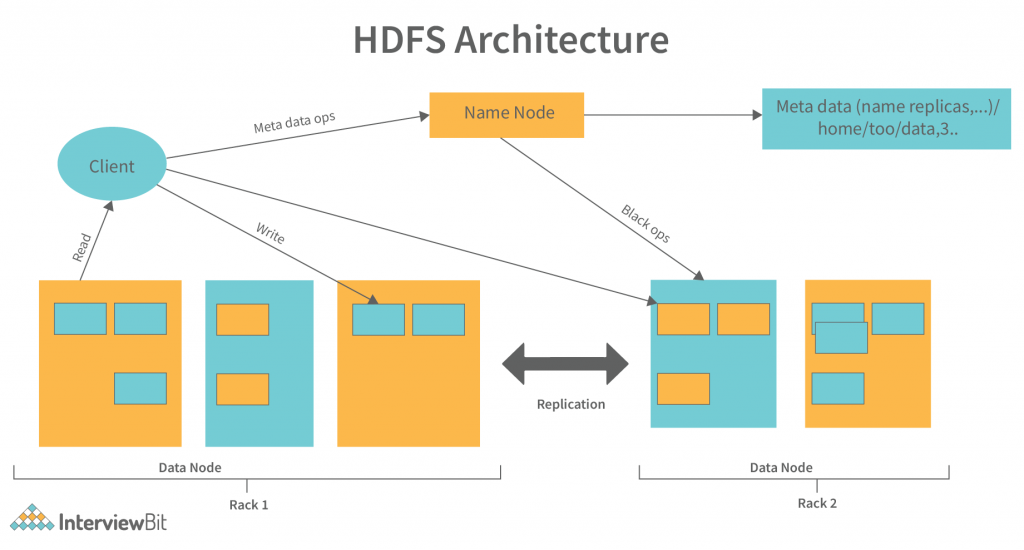
# 1. HDFS数据块管理基础
## Hadoop分布式文件系统(HDFS)是大数据存储的核心组件之一。理解数据块管理是深入了解HDFS内部工作原理和性能优化的基础。
### 数据块概念与重要性
HDFS中的数据不是以文件的整体形式存储,而是被拆分成一系列的块(block)。每个块的默认大小为128MB(Hadoop 2.x版本之前为64MB),这样
HDFS文件读取与网络优化:减少延迟,提升效率的实战指南
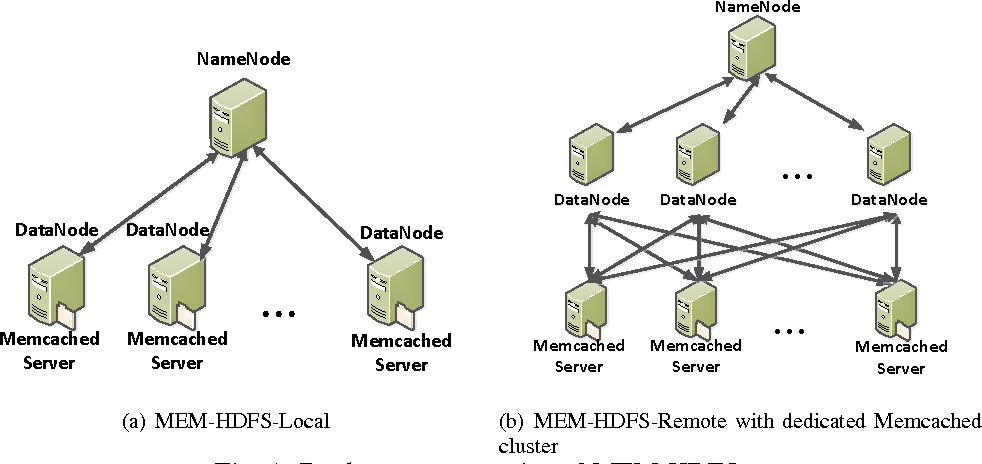
# 1. HDFS文件系统的原理与架构
## 1.1 HDFS文件系统简介
HDFS(Hadoop Distributed File System)是Hadoop项目的一个核心组件,它是一种用于存储大量数据的分布式文件系统。HDFS的设计目标是支持高吞吐量的数据访问,特别适用于大规模数据集的应用。其底层采用廉价的硬件设备,能够保证系统的高容
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )