YOLOv8模型在GPU上的加速优化方法
发布时间: 2024-05-01 13:18:24 阅读量: 260 订阅数: 141 

# 1. YOLOv8模型简介**
YOLOv8是You Only Look Once(YOLO)目标检测算法的最新版本,由旷视科技于2022年推出。它以其卓越的精度和速度而闻名,在COCO数据集上实现了56.8%的AP(平均精度)和160 FPS(每秒帧数)。
YOLOv8采用了多种创新技术,包括:
* **Bag of Freebies(BoF):**一系列免费的训练技巧,可以显著提高模型精度,而无需增加训练时间或计算成本。
* **Cross-Stage Partial Connections(CSP):**一种新的网络结构,可以减少计算量,同时保持模型精度。
* **Path Aggregation Network(PAN):**一种特征聚合模块,可以提高小目标的检测精度。
# 2. YOLOv8模型加速优化理论
### 2.1 模型压缩和剪枝
模型压缩和剪枝是通过减少模型的大小和复杂性来加速模型推理的两种技术。
#### 2.1.1 模型量化
模型量化是将模型中的浮点权重和激活转换为低精度格式(如int8或int16)的过程。这可以显著减少模型的大小和内存占用,从而提高推理速度。
**代码块:**
```python
import torch
from torch.quantization import quantize_dynamic
# 创建一个浮点模型
model = torch.nn.Linear(10, 10)
# 将模型量化为int8
quantized_model = quantize_dynamic(model, qconfig_spec={torch.nn.Linear: torch.quantization.default_qconfig})
```
**逻辑分析:**
* `quantize_dynamic`函数将模型量化为int8格式。
* `qconfig_spec`指定了量化配置,其中`torch.nn.Linear`指定了线性层应使用默认量化配置。
#### 2.1.2 模型蒸馏
模型蒸馏是一种将知识从大型“教师”模型转移到较小“学生”模型的技术。这可以创建具有与教师模型类似性能但大小和复杂性较小的学生模型。
**代码块:**
```python
import torch
from torch.nn.utils import distill
# 创建教师模型和学生模型
teacher_model = torch.nn.Linear(10, 10)
student_model = torch.nn.Linear(5, 10)
# 蒸馏教师模型到学生模型
distill.kl_divergence(student_model, teacher_model)
```
**逻辑分析:**
* `kl_divergence`函数计算教师模型和学生模型之间的KL散度,并将其用作损失函数来训练学生模型。
* 通过最小化KL散度,学生模型学习模仿教师模型的输出分布。
### 2.2 并行计算和分布式训练
并行计算和分布式训练通过利用多个计算设备(如GPU或TPU)来加速模型训练和推理。
#### 2.2.1 数据并行
数据并行是一种将训练数据拆分成多个小批次,并使用不同的设备并行处理这些小批次的技术。这可以显著提高训练速度。
**代码块:**
```python
import torch
import torch.nn.parallel
# 创建一个数据并行模型
model = torch.nn.DataParallel(torch.nn.Linear(10, 10))
# 并行训练模型
model.train()
for batch in data_loader:
model(batch)
```
**逻辑分析:**
* `torch.nn.DataParallel`将模型包装成一个数据并行模型。
* 在训练期间,每个设备接收一个数据小批次,并行计算损失和更新模型权重。
#### 2.2.2 模型并行
模型并行是一种将模型拆分成多个较小的部分,并使用不同的设备并行处理这些部分的技术。这对于大型模型很有用,这些模型无法装入单个设备的内存中。
**代码块:**
```python
import torch
from torch.distributed import distributed_c10d
# 创建一个模型并行模型
model = torch.nn.parallel.DistributedDataParallel(torch.nn.Linear(10, 10))
# 并行训练模型
model.train()
for batch in data_loader:
model(batch)
```
**逻辑分析:**
* `torch.nn.parallel.DistributedDataParallel`将模型包装成一个模型并行模型。
* 在训练期间,每个设备接收模型的一个部分,并行计算损失和更新模型权重。
#### 2.2.3 分布式训练框架
分布式训练框架提供了管理分布式训练过程的工具和API。这些框架包括:
* **Horovod:**一个用于在多个GPU上进行分布式训练的高性能库。
* **PyTorch-Lightning:**一个用于构建和训练深度学习模型的高级框架,它支持分布式训练。
**表格:分布式训练框架比较**
| 特性 | Horovod | PyTorch-Lightning |
|---|---|---|
| 支持的设备 | GPU | GPU、TPU |
| API | C++、Python | Python |
| 易用性 | 较低 | 较高 |
# 3.1 PyTorch和CUDA编程
### 3.1.1 PyTorch基础知识
PyTorch是一个流行的深度学习框架,它提供了灵活且易于使用的API来构建和训练神经网络。PyTorch使用张量(多维数组)作为其基本数据结构,并支持动态计算图,允许在运行时修改模型。
PyTorch有以下优点:
- **灵活性:**PyTorch允许用户轻松自定义模型架构和训练过程。
- **易用性:**PyTorch具有直观的API,易于学习和使用。
- **社区支持:**PyTorch拥有一个活跃的社区,提供广泛的文档和支持资源。
### 3.1.2 CUDA并

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
专栏“Yolov8简介与应用解析”全面介绍了Yolov8目标检测算法。从基本原理、应用概述到与其他算法的对比分析,专栏深入探讨了Yolov8的优势和特性。文章还提供了Yolov8训练数据集准备、模型训练调参、移动设备部署优化、NMS算法原理、FPN实现原理、多尺度训练技巧、微调技巧、性能评估指标、优化方法、数据增强技术、迁移学习方法、连续帧处理技术等方面的详细指导。此外,专栏还展示了Yolov8在道路交通车辆检测、无人机目标识别、工业安全监控、食品质检、医学影像分析、体育动作识别、智能家居行为检测、环境监控、机器人导航等领域的实战应用案例,为读者提供了深入了解和应用Yolov8的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
大数据量下的性能提升:掌握GROUP BY的有效使用技巧
# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
【C++内存泄漏检测】:有效预防与检测,让你的项目无漏洞可寻

# 1. C++内存泄漏基础与危害
## 内存泄漏的定义和基础
内存泄漏是在使用动态内存分配的应用程序中常见的问题,当一块内存被分配后,由于种种原因没有得到正确的释放,从而导致系统可用内存逐渐减少,最终可能引起应用程序崩溃或系统性能下降。
## 内存泄漏的危害
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
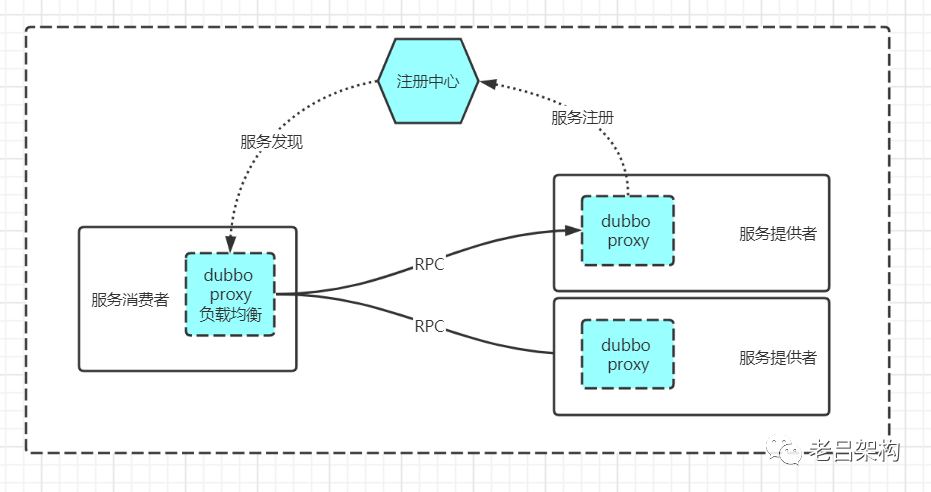
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
Java药店系统国际化与本地化:多语言支持的实现与优化
# 1. Java药店系统国际化与本地化的概念
## 1.1 概述
在开发面向全球市场的Java药店系统时,国际化(Internationalization,简称i18n)与本地化(Localization,简称l10n)是关键的技术挑战之一。国际化允许应用程序支持多种语言和区域设置,而本地化则是将应用程序具体适配到特定文化或地区的过程。理解这两个概念的区别和联系,对于创建一个既能满足
【图表与数据同步】:如何在Excel中同步更新数据和图表

# 1. Excel图表与数据同步更新的基础知识
在开始深入探讨Excel图表与数据同步更新之前,理解其基础概念至关重要。本章将从基础入手,简要介绍什么是图表以及数据如何与之同步。之后,我们将细致分析数据变化如何影响图表,以及Excel为图表与数据同步提供的内置机制。
## 1.1 图表与数据同步的概念
图表,作为一种视觉工具,将数据的分布、变化趋势等信息以图形的方式展
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
【MySQL大数据集成:融入大数据生态】
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
【模板编程中的指针】:泛型编程中指针技术的细节分析

# 1. 模板编程中的指针基础
模板编程是C++中一种强大的编程范式,它允许我们创建可重用的代码片段,这些代码片段可以处理任何类型的数据。指针作为C++语言中的基础元素,在模板编程中扮演了重要角色,它们提供了一种灵活的方式来操作内存和数据。掌握指针和模板的基础知识是深入理解模板编程的前提,也是学习泛型编程的基石。本章我们将从指针的基本概念开始,逐步深入理解它们在模板编程中的应用和作用
mysql-connector-net-6.6.0云原生数据库集成实践:云服务中的高效部署

# 1. mysql-connector-net-6.6.0概述
## 简介
mysql-connector-net-6.6.0是MySQL官方发布的一个.NET连接器,它提供了一个完整的用于.NET应用程序连接到MySQL数据库的API。随着云
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )