逻辑回归详解:二分类预测的经典与实践
发布时间: 2024-11-24 23:40:51 阅读量: 20 订阅数: 25 

logistic_逻辑斯蒂回归二分类_
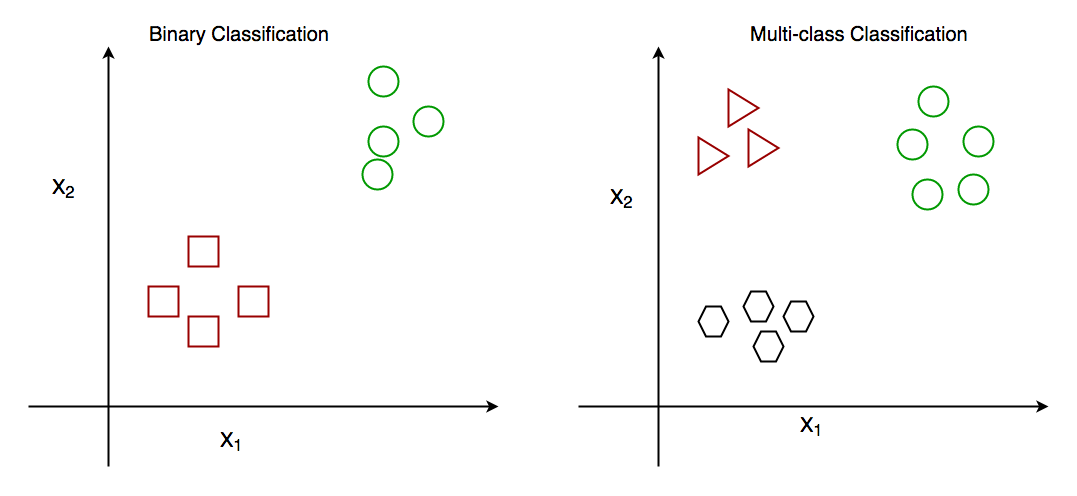
# 1. 逻辑回归简介
逻辑回归是一种广泛应用于二分类问题的统计方法,尤其在预测某事件发生的概率时非常有效。作为机器学习的入门算法之一,它不仅简单易懂,而且在金融、医疗等领域中占有重要的地位。尽管名为回归,实际上逻辑回归是一种分类算法,它通过逻辑函数将线性回归的输出映射到0和1之间,以进行概率预测。下面我们将深入探讨逻辑回归的数学基础和实际应用。
# 2. 逻辑回归的数学基础
## 2.1 线性回归与逻辑回归的关系
逻辑回归虽然是分类算法,但它与线性回归有着密切的联系。理解这种关系,对学习逻辑回归的原理和算法有重要的意义。
### 2.1.1 线性回归的基本概念
线性回归模型是最基本的回归分析方法之一。它试图根据一个或多个预测变量(也称为特征或自变量)来预测一个响应变量(也称为因变量)。线性回归的输出是连续的,可以表示为一个数学公式:
Y = β0 + β1X1 + β2X2 + ... + βnXn + ε
其中,Y是响应变量,X1到Xn是预测变量,β0到βn是模型参数(包括截距),ε是误差项。
### 2.1.2 逻辑函数的作用与意义
逻辑回归虽名为回归,实际上是分类模型。它用于估计一个事件发生的概率。逻辑回归模型使用了逻辑函数(也称为sigmoid函数)将线性回归的输出转换为概率值:
p(Y=1|X) = 1 / (1 + e^-(β0 + β1X1 + ... + βnXn))
在逻辑回归中,我们不是直接预测Y的值,而是预测Y=1的概率。若概率大于阈值(一般设定为0.5),则预测为正类(1),否则预测为负类(0)。
## 2.2 概率论与逻辑回归
逻辑回归深受概率理论的影响,其模型构建和参数估计过程涉及大量的概率论知识。
### 2.2.1 条件概率基础
逻辑回归模型建立在条件概率的基础上。条件概率指的是在给定一个或多个事件发生的条件下,另一个事件发生的概率。它可以用数学公式表示为P(Y|X)。逻辑回归模型的目标是估计P(Y=1|X)的概率。
### 2.2.2 逻辑回归的概率解释
在逻辑回归中,我们使用对数几率(或log odds)的概念。对数几率是事件发生与不发生的对数比率:
log(p(Y=1|X) / (1 - p(Y=1|X)))
对数几率与线性回归方程紧密相关,因为逻辑函数是将线性方程的输出映射到(0,1)区间的概率值。
## 2.3 逻辑回归的成本函数
逻辑回归模型的目标是找到一组参数,使得模型预测概率与实际观测概率之间的差异最小化。
### 2.3.1 成本函数的选择与定义
逻辑回归使用的是交叉熵(Cross-Entropy)损失函数,也称为对数损失函数。其定义如下:
J(θ) = -1/m * ∑ [y(i) * log(p(i)) + (1 - y(i)) * log(1 - p(i))]
这里,m是训练样本的数量,y(i)是第i个样本的真实标签,p(i)是模型对第i个样本预测为正类的概率。
### 2.3.2 优化成本函数的方法
为了优化成本函数,我们通常使用梯度下降算法。该算法通过迭代计算参数的偏导数(即梯度),然后根据梯度调整参数,以最小化成本函数。梯度下降的迭代公式如下:
θj = θj - α * ∂J(θ)/∂θj
其中,α是学习率,θj是模型参数。
在这个过程中,读者可以理解逻辑回归模型是如何从线性回归中延伸出来的,以及其在概率理论中的应用。同时,还介绍了成本函数的定义,以及优化该函数的梯度下降方法。这些知识为学习下一章节的逻辑回归模型实现打下了坚实的基础。
# 3. 逻辑回归模型的实现
在深入到逻辑回归模型的具体实现之前,我们需要了解在构建有效的机器学习模型时,数据预处理和模型评估的重要性不亚于模型训练本身。本章将详细介绍如何准备数据、训练模型,并最终评估和优化逻辑回归模型。我们将通过代码示例、逻辑分析和具体的步骤来展示整个实现过程。
## 特征选择与数据预处理
### 3.1 特征选择与数据预处理
在机器学习任务中,特征选择与数据预处理是模型训练之前的必要步骤。有效的数据预处理可以提高模型的性能,并减少过拟合的风险。
#### 3.1.1 数据清洗与特征提取
在开始之前,必须确保数据的质量。数据清洗涉及识别和处理缺失值、异常值,以及处理噪声数据,这些都可能影响模型的表现。
```python
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
# 处理缺失值
data.fillna(data.mean(), inplace=True)
# 处理异常值,例如对于数值型特征,可以使用Z-score方法
from scipy import stats
import numpy as np
z_scores = np.abs(stats.zscore(data))
data = data[(z_scores < 3).all(axis=1)]
```
特征提取是指从原始数据中创建新特征的过程,这可能包括特征工程技术如特征交叉、多项式特征等。
```python
# 特征交叉
data['feature1_feature2'] = data['feature1'] * data['feature2']
```
#### 3.1.2 数据标准化与编码
数据标准化和编码是预处理的另一个重要环节。标准化通常涉及将特征值缩放到一个统一的范围或分布,例如,使用Z-score标准化或最小-最大标准化。
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 使用Z-score标准化
scale
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《机器学习-预测与推断》专栏深入探讨了机器学习中预测和推断的基本概念。从预测与推断的入门秘籍到过拟合与欠拟合的识别和解决,专栏提供了全面的指导。此外,还涵盖了数据预处理、交叉验证和逻辑回归等关键主题。通过对支持向量机的深入分析,专栏展示了如何解决复杂预测问题。无论你是机器学习新手还是经验丰富的从业者,这个专栏都能提供宝贵的见解和实用的技巧,帮助你提升预测模型的准确性和泛化能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
一步到位:ObjectARX2016中OPM面板的自定义操作秘籍
# 摘要
本文全面探讨了ObjectARX2016环境下OPM面板的设计、开发与应用。文章从OPM面板的基本结构和原理入手,详细介绍了其框架、组件以及与AutoCAD的交互机制。随后,文章深入研究了OPM面板自定义操作的理论基础,并提出了界面和功能模块的实现方法论。在实践指南部分,文中提供了界面自定义、功能扩展和脚本编写的实用技巧,以及调试、测试和优化的具体方法。最后,文章通过高级应用案例
AxureRP9常用交互功能解析:3个技巧打造生动原型
# 摘要
本文全面探讨了AxureRP9中交互功能的细节和应用,从基础概念到高级技巧,提供了系统化的理解与实践指导。文章首先概述了AxureRP9交互功能的重要性,并介绍了交互设计的基础知识,如事件和动作的定义及其在原型中的运用。随后,深入探讨了交互设计的实践技巧,如动态面板的高效使用,中继器的创造性应用,以及如何实现交互式原型的动态效果。接着,本文提供了在
【视频解码技术新手指南】:RN6752M芯片规格书的必读要点
# 摘要
随着多媒体技术的发展,视频解码技术在数字视频播放和处理领域扮演着核心角色。本文首先概述了视频解码技术的基本概念和应用场景,随后详细介绍RN6752M芯片的架构特性,并深入解析了视频编码与解码的基本流程,包括编码标准对比、编码流程各步骤以及解码操作的细节。通过分析RN6752M芯片在视频解码中的实际应用,本文展示了如何搭建开发环境、准备编码文件、编写和调试解码程序,并对其性能进行了评估和
【医学影像分析的利器】:Canny算子在医学领域应用的深入研究
# 摘要
Canny算子是图像处理领域中广泛应用于边缘检测的重要算法,尤其在医学影像分析中,它对于提高疾病诊断的准确性及辅助手术导航具有显著的辅助作用。本文系统介绍了Canny算子的原理、边缘检测流程及优化技术,并将其与其他边缘检测方法进行了比较。同时,探讨了Canny算子在不同医学影像类型中的应用,以及在实际临床环境中的集成和优化策略。本文还进一步分析了Canny算子在高级医学应用中的潜力,如3D重建、计算机辅助外科手术和影像数据库检索。通过对Canny算子在
提高效率的关键:S7-1500 PLC编程技巧大公开

# 摘要
本文全面介绍了S7-1500 PLC编程的各个方面,从基础的编程概念、硬件组成、编程语言和工具,到高级编程技巧、数据处理、故障诊断与程序调试,再到项目实践案例分析及未来自动化与智能化的发展趋势。通过对S7-1500 PLC编程技术的详细介绍和深入分析,本文旨在为读者提供一套系统化的学习路径和实际应用指南,帮助工程师和技术人员在自动化控制系统中高效地使用
NC客户端安全与性能优化:保护数据,保障速度

# 摘要
本文系统地介绍了NC客户端的基础安全概念、安全机制、性能优化策略以及监控工具的使用。首先,本文对NC客户端的基础安全概念进行了简要介绍,并详细阐述了认证授权机制、数据加密技术以及安全策略和风险评估的重要性。接着,文章提出了多种性能优化策略,涵盖系统资源管理、网络与通信优化以及应用程序性能的提升。此外,还探讨了安全与性能监控工具的应用,包括实时入侵检测、安全信息管理(SIEM)、应用性能管理(APM)等
Allegro热分析:如何运用Analysis Modes评估热效应的4大技巧

# 摘要
Allegro热分析是电子设计自动化(EDA)领域中重要的热特性分析工具。本文首先介绍了热分析的基础知识,包括热效应理论以及电路中热效应的产生。接着,对热分析理论背景和不同分析模式进行了深入探讨,并详细阐述了如何选择合适的分析模式。此外,本文还提供了热分析参数设置的理论与实践指南,包括材料属性输入、环境条件模拟以及模拟过程的优化策略。文章进一步阐
【形变监测实战】:如何用Sentinel-1数据捕捉城市沉降的秘密

# 摘要
形变监测技术在城市规划和灾害预防中扮演着重要角色。本文首先概述了形变监测技术的发展与应用,接着重点介绍了Sentinel-1卫星数据的基础知识,包括其任务特点、数据生成过程以及数据预处理和分析方法。随后,本文通过城
【Gnuplot 错误诊断大师班】:确保你的图表无懈可击
# 摘要
Gnuplot作为一种灵活的命令驱动的绘图工具,在数据可视化领域发挥着重要作用。本文首先介绍了Gnuplot的基础知识、安装方法以及数据绘图和错误诊断技术。随后,深入探讨了高级图表优化的理论基础和实用技巧,包括图表美学、性能瓶颈优化以及常见错误的预防措施。此外,本文还强调了通过脚本自动化和定制来提高绘图效率的重要性,并通过应用案例展示了如何在不同数据集上运用Gnuplot进行有效可视化。最后,文中探讨了Gnuplot社区资源、学习途径和未来发展趋势,为读者提供了深入学习和参与贡献的途径。
# 关键字
Gnuplot;数据可视化;图表优化;脚本自动化;错误诊断;大数据集处理
参考资
阿尔派RUX-C800性能激战:系统升级与高级调整必知

# 摘要
阿尔派RUX-C800作为先进的系统平台,其性能分析、系统升级以及高级调整成为技术优化的关键领域。本文首先对RUX-C800进行了全面的概览和性能评估,然后深入探讨了系统升级的理论和实践步骤,包括必要的准备和升级工具的选择,以及升级过程中可能遇到的问题及其解决方案。接着,文章详细阐述了高级调整的理论基础和实践技巧,评估了调整效果,并分享了实际案例经验。最后,本文从故
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )