Python data库的错误处理:避免常见陷阱和解决方案,保证数据处理的稳定性
发布时间: 2024-10-15 18:01:19 阅读量: 3 订阅数: 3 
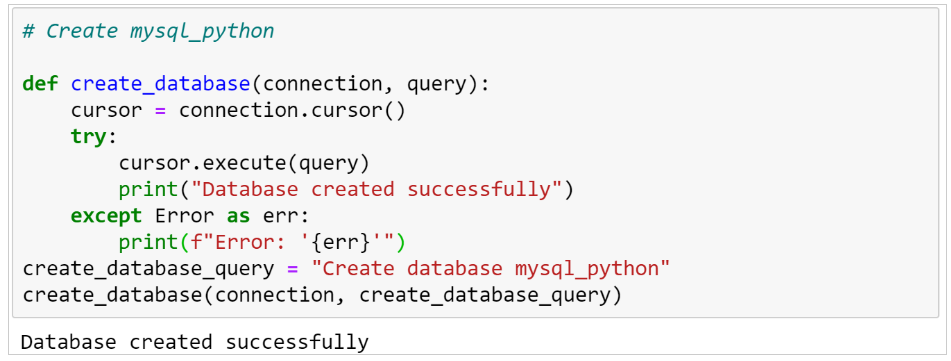
# 1. Python data库概述和错误处理的重要性
Python作为一种广泛使用的编程语言,其强大的生态系统中包含了多个用于数据分析的库,其中`data`库因其简洁的API和强大的功能而受到许多数据科学家的青睐。然而,在实际使用过程中,错误处理的重要性不容忽视,它能够帮助我们更好地理解和应对可能出现的异常情况,确保数据分析的准确性和稳定性。
本章首先将对`data`库进行概述,包括它的功能、用途以及在数据处理流程中的位置。随后,我们将深入探讨错误处理的重要性,它不仅涉及到代码的健壮性,也是数据分析过程中不可或缺的一部分。我们将通过实例来展示错误处理如何帮助我们避免常见的陷阱,以及它在提高数据处理效率方面的作用。
```python
# 示例代码:错误处理的基本框架
try:
# 尝试执行的代码块
pass
except Exception as e:
# 捕获并处理异常
print(f"An error occurred: {e}")
finally:
# 无论是否发生异常都会执行的代码块
print("This is the end of the block.")
```
在上述代码中,`try`块包含了可能引发异常的代码,`except`块用于捕获异常并进行处理,而`finally`块则确保无论是否发生异常,相关的清理工作都能被执行。这种结构是错误处理的核心,有助于我们在使用`data`库时,更加从容地面对各种挑战。
# 2. Python data库的基本使用和常见错误类型
## 2.1 Python data库的基本使用
### 2.1.1 数据加载和存储
在使用Python进行数据分析时,`data`库提供了一系列便捷的工具来加载和存储数据。这一小节我们将探讨如何使用这些工具来加载数据集,以及如何将处理后的数据保存到不同的格式中。
首先,加载数据通常是从CSV或Excel文件开始的。例如,我们可以使用`data.load_csv`函数来加载CSV文件:
```python
import data
# 加载CSV文件
df = data.load_csv('data.csv')
print(df.head())
```
上面的代码加载了一个名为`data.csv`的CSV文件,并打印出前五行数据。`data.load_csv`函数读取文件并将其转换为一个DataFrame对象,这是`data`库中最常用的数据结构之一。
接下来,我们可能会将DataFrame保存到不同的文件格式中,比如Excel。`data.save_excel`函数可以帮助我们实现这一点:
```python
# 保存DataFrame到Excel文件
data.save_excel(df, 'data.xlsx')
```
这段代码将DataFrame保存为一个Excel文件。`data`库支持多种格式的数据加载和存储,包括但不限于CSV、Excel、JSON、SQL等。
### 2.1.2 数据集的基本操作
一旦数据被加载到DataFrame中,我们就可以对其进行各种操作了。例如,我们可以对数据进行排序、过滤、合并、分组等。
下面是一个简单的例子,展示了如何对数据进行排序:
```python
# 对DataFrame按某一列进行排序
sorted_df = df.sort_values(by='column_name')
print(sorted_df.head())
```
这里,`df.sort_values`函数根据列`column_name`的值对数据进行排序。除了排序,我们还可以使用`df.filter`来过滤数据,`df.merge`来进行数据合并,`df.groupby`来分组数据等等。
## 2.2 常见的错误类型和原因
### 2.2.1 数据类型错误
在处理数据时,数据类型错误是一种常见的问题。这可能是由于数据集中某个字段的类型不一致,或者在加载数据时没有正确指定数据类型。
例如,假设我们有一个包含数字和文本的列:
```python
# 加载CSV文件
df = data.load_csv('data_with_mixed_types.csv')
# 尝试将某列转换为整数
df['mixed_column'] = df['mixed_column'].astype(int)
```
如果`mixed_column`列包含文本,那么`astype(int)`操作将会失败,并抛出一个错误。在这种情况下,我们可以使用`errors='coerce'`参数来忽略转换错误:
```python
df['mixed_column'] = df['mixed_column'].astype(int, errors='coerce')
```
这将把无法转换的值设置为NaN(不是数字),从而避免了错误。
### 2.2.2 数据缺失错误
数据缺失是另一个常见的问题。在数据集中,某些值可能因为各种原因而缺失,比如数据录入错误或数据传输中断。
处理数据缺失的方法有很多。一种简单的方法是使用平均值或中位数填充缺失值:
```python
# 填充缺失值为列的平均值
df['missing_column'].fillna(df['missing_column'].mean(), inplace=True)
```
在这个例子中,我们使用`fillna`方法将`missing_column`列中的所有缺失值替换为该列的平均值。
### 2.2.3 数据格式错误
数据格式错误通常涉及到日期时间或特定格式的字符串。例如,如果一个日期列的格式不一致,它可能会导致错误。
我们可以使用`pd.to_datetime`来转换日期格式:
```python
# 将字符串转换为日期时间格式
df['date_column'] = pd.to_datetime(df['date_column'], errors='coerce')
```
如果转换失败,`errors='coerce'`参数将缺失值设置为NaT(不是时间)。这避免了格式错误导致的异常,并允许我们继续处理数据。
### 代码块逻辑解读
在上面的代码块中,我们首先加载了一个CSV文件到DataFrame中,然后尝试将其中一列转换为整数类型。如果该列包含非数字的值,转换操作会失败。为了解决这个问题,我们使用了`errors='coerce'`参数,这会将无法转换的值设为NaN。这样做可以避免程序因类型错误而中断。
在处理数据缺失时,我们使用了`fillna`方法,并将缺失值替换为该列的平均值。这是处理缺失数据的一种常用方法,可以确保数据的连续性,尽管在某些情况下可能会影响分析结果。
最后,我们使用`pd.to_datetime`来处理日期时间格式的错误。通过设置`errors='coerce'`参数,我们可以将格式不正确的日期转换为NaT,这样就不会影响后续的数据处理流程。
### 表格展示
在处理数据类型错误时,我们可以使用一个表格来记录原始数据类型和转换后的数据类型,以及是否成功转换。这样的表格有助于我们理解数据转换的过程和结果。
| 原始类型 | 目标类型 | 转换是否成功 | 结果类型 |
|-----------|-----------|---------------|-----------|
| 字符串 | 整数 | 是 | 整数 |
| 字符串 | 整数 | 否 | NaN |
| 整数 | 字符串 | 是 | 字符串 |
通过上述表格,我们可以清晰地看到不同类型数据转换的结果,并且可以基于这些信息进一步处理数据。
### mermaid流程图
在处理数据时,我们通常会遇到多个步骤和条件。mermaid流程图可以帮助我们可视化这些步骤和条件之间的关系。下面是一个简单的流程图,展示了处理数据类型错误的过程:
```mermaid
graph TD
A[开始] --> B[加载数据]
B --> C{数据类型检查}
C -->|是| D[转换数据类型]
C -->|否| E[记录错误]
D --> F[继续处理]
E --> F
F --> G[结束]
```
在这个流程图中,我们从加载数据开始,然后检查数据类型。如果数据类型是正确的,我们进行类型转换;如果不是,我们记录错误并继续处理。最终,我们结束处理流

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Werkzeug.exceptions库的异常链:深入理解异常链的用法和好处
# 1. Werkzeug.exceptions库概述
Werkzeug.exceptions库是Python编程语言中Flask框架的一个重要组成部分,它提供了一系列预定义的异常类,这些异常类在Web应用开发中扮演着重要的角色。通过定义不同类型的HTTP异常,Werkzeug允许开发者以一种标准化的方式来表达错误,并且能够与Web服务器进行有效交互。
## 1.1 Werkz
Pylons WebSockets实战:实现高效实时通信的秘诀

# 1. Pylons WebSockets基础概念
## 1.1 WebSockets简介
在Web开发领域,Pylons框架以其强大的功能和灵活性而闻名,而WebSockets技术为Web应用带来了全新的实时通信能力。WebSockets是一种网络通信协议,它提供了浏览器和服务器之间全双工的通信机制,这意味着服务器可以在任何时候向客户端发送消息,而不仅仅是响应客户端的请求。
## 1.2 WebSockets的
Pygments社区资源利用:解决Pygments.filter难题
# 1. Pygments概述与基本使用
## 1.1 Pygments简介
Pygments是一个Python编写的通用语法高亮工具,它可以处理多种编程语言的源代码。它将代码转换为带有颜色和格式的文本,使得阅读和理解更加容易。Pygments不仅提供了命令行工具,还通过API的形式支持集成到其他应用中。
## 1.2 安装Pygments
PycURL与REST API构建:构建和调用RESTful服务的实践指南

# 1. PycURL简介与安装
## PycURL简介
PycURL是一款强大的Python库,它是libcurl的Python接口,允许开发者通过Python代码发送网络请求。与标准的urllib库相比,PycURL在性能上有着显著的优势
Django multipartparser的缓存策略:提高响应速度与减少资源消耗的6大方法

# 1. Django multipartparser简介
## Django multipartparser的概念
Django作为一个强大的Python Web框架,为开发者提供了一系列工具来处理表单数据。其中,`multipa
Numpy.linalg在优化问题中的应用:线性和非线性规划问题的求解
# 1. Numpy.linalg库简介
## 1.1 Numpy库概述
Numpy是一个强大的Python库,专门用于进行大规模数值计算,尤其是在科学计算领域。它提供了高性能的多维数组对象以及用于处理这些数组的工具。
## 1.2 Numpy.linalg模块介绍
Numpy.linalg模块是Numpy库中专门用于线性代数计算的模块,包含了大量的线性代数运算函数
Twisted.web.client与asyncio的集成:探索异步编程的新纪元

# 1. Twisted.web.client与asyncio的基本概念
## 1.1 Twisted.web.client简介
Twisted.web.client是一个强大的网络客户端库,它是Twisted框架的一部分,提供了构建异步HTTP客户端的能力。Twisted是一个事件驱动的网络编程框架,它允许开发者编写非阻塞的网络
【敏捷开发中的Django版本管理】:如何在敏捷开发中进行有效的版本管理
# 1. 敏捷开发与Django版本管理概述
## 1.1 敏捷开发与版本控制的关系
在敏捷开发过程中,版本控制扮演着至关重要的角色。敏捷开发强调快速迭代和响应变化,这要求开发团队能够灵活地管理代码变更,确保各个迭代版本的质量和稳定性。版本控制工具提供了一个共享代码库,使得团队成员能够并行工作,同时跟踪每个成员的贡献。在Django项目中,版本控制不仅能帮助开发者管理代码
【Django文件校验:性能监控与日志分析】:保持系统健康与性能
# 1. Django文件校验概述
## 1.1 Django文件校验的目的
在Web开发中,文件上传和下载是常见的功能,但它们也带来了安全风险。Django文件校验机制的目的是确保文件的完整性和安全性,防止恶意文件上传和篡改。
## 1.2 文件校验的基本流程
文件校验通常包括以下几个步骤:
1. **文件上传**:用户通过Web界面上传文件。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )