Python data库实战指南:从入门到精通,3步打造数据处理专家
发布时间: 2024-10-15 17:52:58 阅读量: 79 订阅数: 38 

pydata-book:利用Python进行数据分析
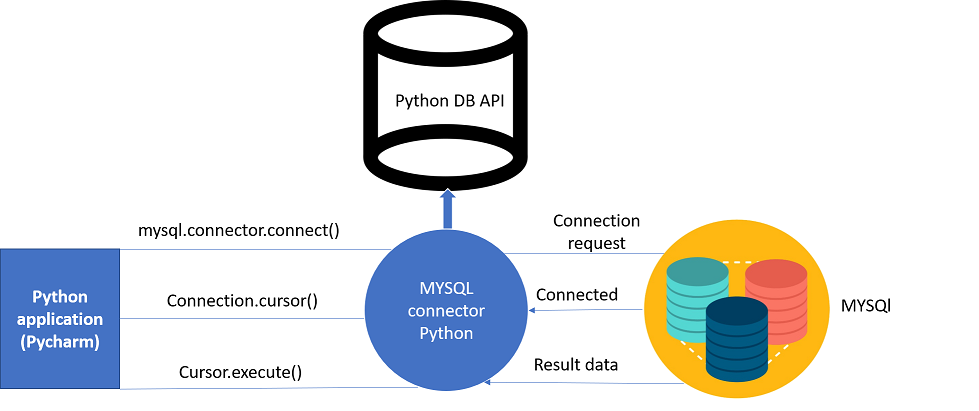
# 1. Python data库概述
Python的data库是一组强大的数据处理工具,提供了高效、灵活的数据结构以及数据分析工具。在这一章中,我们将概述data库的基本功能和优势,并介绍如何在日常的数据分析任务中使用它来提升工作效率。
## 1.1 data库的功能与优势
data库是一个专为数据分析设计的库,它的核心在于提供了一组易于使用的数据结构和数据分析工具。它支持复杂的数据操作,如数据清洗、转换、聚合、合并等,同时与NumPy和SciPy等科学计算库紧密集成,为更高级的数据分析提供了便利。
### 功能特点:
- **高效的数据结构**:提供Series和DataFrame两种主要的数据结构,分别用于一维和二维数据操作。
- **数据操作简便**:内置丰富的函数和方法,简化了数据筛选、排序、合并等操作。
- **强大的数据整合能力**:能够从多种数据源(如CSV、Excel、SQL数据库等)加载和保存数据。
- **高级数据分析**:提供统计、时间序列分析、数据透视表等高级分析工具。
### 优势:
- **易学易用**:Python的语法简洁,使得data库的学习曲线相对平缓。
- **高效的性能**:利用Cython、NumPy等底层优化,确保了操作的高性能。
- **丰富的资源**:拥有庞大的社区支持,提供大量的文档和第三方工具。
通过本章的学习,读者将对data库有一个全面的了解,并能够在后续章节中深入掌握其数据操作的技巧。
# 2. Python data库基础操作
### 2.1 数据结构的使用
在本章节中,我们将深入探讨`pandas`库中两个核心的数据结构:`Series`和`DataFrame`。这两个数据结构是处理和分析数据的基础,掌握它们的操作对于任何数据处理任务都是至关重要的。
#### 2.1.1 Series对象的操作
`Series`对象是`pandas`中的一维数据结构,可以看作是一个带有索引的数组。在实际应用中,`Series`通常用于处理时间序列数据或实现简单的数据映射关系。
```python
import pandas as pd
# 创建一个简单的Series对象
data = [1, 2, 3, 4, 5]
index = ['a', 'b', 'c', 'd', 'e']
s = pd.Series(data, index=index)
```
在上述代码中,我们首先导入了`pandas`库,并创建了一个名为`s`的`Series`对象。这个对象包含了5个元素,每个元素都有一个对应的索引标签。通过这种方式,`Series`将简单的数据映射到了一个索引标签上。
**代码逻辑解读分析:**
- `data`列表包含了`Series`对象的值。
- `index`列表定义了每个数据值的索引标签。
- `pd.Series()`函数创建了一个`Series`对象,其中`data`参数是数据值,`index`参数是对应的索引标签。
**参数说明:**
- `data`:包含数据值的列表或数组。
- `index`:与`data`相对应的索引标签。
#### 2.1.2 DataFrame对象的操作
`DataFrame`是`pandas`中的二维数据结构,可以看作是一个表格,每一列可以有不同的数据类型。`DataFrame`是数据分析中最常用的数据结构,因为它能够处理结构化数据,如CSV文件或数据库表。
```python
# 创建一个DataFrame对象
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
```
在上述代码中,我们使用`pd.DataFrame()`函数创建了一个名为`df`的`DataFrame`对象。这个对象包含了两列数据,分别是`Name`和`Age`,以及三行数据。
**代码逻辑解读分析:**
- `data`字典定义了`DataFrame`的列名和对应的数据值。
- `pd.DataFrame()`函数创建了一个`DataFrame`对象,其中`data`参数是一个字典,字典的键是列名,值是列数据。
**参数说明:**
- `data`:一个字典,键是列名,值是列数据。
### 2.2 数据加载与存储
在本章节中,我们将学习如何从不同的数据源加载数据,以及如何将数据保存到外部存储中。这对于数据预处理和数据分析至关重要。
#### 2.2.1 从CSV文件读取数据
CSV文件是一种常见的数据格式,`pandas`提供了`read_csv`函数来从CSV文件中读取数据。
```python
# 从CSV文件读取数据
df = pd.read_csv('data.csv')
```
在上述代码中,我们使用`pd.read_csv()`函数从名为`data.csv`的CSV文件中读取数据,并将其存储在`df`变量中。
**代码逻辑解读分析:**
- `pd.read_csv()`函数从CSV文件中读取数据,并自动解析为`DataFrame`对象。
**参数说明:**
- `filepath_or_buffer`:文件路径或类似文件的对象。
#### 2.2.2 保存数据到CSV文件
将`DataFrame`对象保存到CSV文件中可以通过`to_csv`方法实现。
```python
# 将数据保存到CSV文件
df.to_csv('output.csv', index=False)
```
在上述代码中,我们使用`DataFrame`对象的`to_csv`方法将数据保存到名为`output.csv`的CSV文件中。
**代码逻辑解读分析:**
- `to_csv`方法将`DataFrame`对象保存到CSV文件中。
- `index=False`参数表示在保存时不包含行索引。
#### 2.2.3 从数据库加载数据
`pandas`还提供了与多种数据库交互的能力,例如SQLite、MySQL、PostgreSQL等。
```python
# 从SQLite数据库加载数据
from sqlalchemy import create_engine
engine = create_engine('sqlite:///example.db')
df = pd.read_sql_query('SELECT * FROM data_table', engine)
```
在上述代码中,我们首先导入了`sqlalchemy`库中的`create_engine`函数,然后创建了一个SQLite数据库引擎。接着,我们使用`pd.read_sql_query()`函数从数据库表`data_table`中读取数据,并将其存储在`df`变量中。
**代码逻辑解读分析:**
- `create_engine()`函数创建了一个数据库引擎,它是一个连接数据库的桥梁。
- `pd.read_sql_query()`函数从数据库中执行SQL查询,并将结果转换为`DataFrame`对象。
### 2.3 数据清洗与预处理
在本章节中,我们将介绍数据清洗和预处理的基本概念和方法,包括缺失值处理、异常值检测与处理、数据转换与归一化等。
#### 2.3.1 缺失值处理
处理缺失值是数据清洗中的一个重要步骤。`pandas`提供了多种处理缺失值的方法,如删除含有缺失值的行或列、填充缺失值等。
```python
# 处理缺失值
import numpy as np
# 删除含有缺失值的行
df.dropna(inplace=True)
# 使用平均值填充缺失值
df.fillna(df.mean(), inplace=True)
```
在上述代码中,我们首先导入了`numpy`库中的`np`对象。然后,我们使用`dropna`方法删除了含有缺失值的行,并使用`fillna`方法将缺失值填充为该列的平均值。
**代码逻辑解读分析:**
- `dropna()`方法用于删除含有缺失值的行或列。
- `fillna()`方法用于填充缺失值。
**参数说明:**
- `inplace=True`:在原地修改`DataFrame`对象,而不是返回一个新的`DataFrame`对象。
#### 2.3.2 异常值检测与处理
异常值可能会对数据分析的结果产生负面影响。`pandas`提供了描述性统计方法来帮助识别异常值。
```python
# 检测异常值
z_scores = (df['column_name'] - df['column_name'].mean()) / df['column_name'].std()
# 移除异常值
df = df[(np.abs(z_scores) < 3)]
```
在上述代码中,我们首先计算了`column_name`列的Z分数,然后使用这个分数来识别异常值,并从`DataFrame`中移除它们。
**代码逻辑解读分析:**
- 使用Z分数来识别异常值,即数据点与平均值的标准差的倍数。
- `np.abs(z_scores) < 3`用于识别Z分数小于3的数据点。
#### 2.3.3 数据转换与归一化
数据转换和归一化是预处理步骤中的关键步骤,它们可以提高模型的性能。例如,标准化和归一化是两种常见的数据转换方法。
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df[['column_name']])
# 数据归一化
min_max_scaler = MinMaxScaler()
normalized_data = min_max_scaler.fit_transform(df[['column_name']])
```
在上述代码中,我们使用了`sklearn.preprocessing`模块中的`StandardScaler`和`MinMaxScaler`类来分别对数据进行标准化和归一化处理。
**代码逻辑解读分析:**
- `StandardScaler`用于标准化数据,即调整数据使其具有零均值和单位方差。
- `MinMaxScaler`用于归一化数据,即将数据缩放到[0, 1]区间。
**参数说明:**
- `fit_transform()`方法用于拟合数据并转换数据。
- `df[['column_name']]`用于选择`DataFrame`中的特定列。
以上是第二章“Python data库基础操作”的内容,我们将继续在下一节中深入探讨数据加载与存储的方法,以及如何进行有效的数据清洗与预处理。
# 3. 深入探索数据操作
## 3.1 数据筛选与排序
### 3.1.1 基于条件的筛选
在数据分析中,我们经常需要从大量的数据中筛选出满足特定条件的子集。在Python的pandas库中,我们可以使用布尔索引来实现这一目的。布尔索引是一种利用布尔值(True/False)来筛选数据的方式。
```python
import pandas as pd
# 创建一个DataFrame示例
data = {'Name': ['Tom', 'Nick', 'John', 'Tom', 'Jane', 'Alice'],
'Age': [20, 21, 19, 22, 23, 24]}
df = pd.DataFrame(data)
# 筛选年龄大于20岁的用户
condition = df['Age'] > 20
filtered_df = df[condition]
print(filtered_df)
```
在这个例子中,我们首先创建了一个包含姓名和年龄的DataFrame。然后,我们定义了一个条件`condition`,该条件检查年龄是否大于20岁。最后,我们使用这个条件来筛选DataFrame,得到一个新的DataFrame`filtered_df`,其中只包含年龄大于20岁的用户。
### 3.1.2 基于索引的筛选
除了基于条件的筛选,我们还可以基于索引进行筛选。例如,如果我们想要根据特定的索引标签来选择数据,可以使用`loc`方法。
```python
# 筛选索引标签为'Tom'的数据
selected_data = df.loc[df['Name'] == 'Tom']
print(selected_data)
```
在这个例子中,我们使用`loc`方法和一个条件来筛选出姓名为'Tom'的用户。`loc`方法允许我们根据标签选择行和列。
### 3.1.3 数据排序技巧
数据排序是数据操作中的另一个重要方面。我们可以使用`sort_values`方法来对DataFrame进行排序。
```python
# 按照年龄排序
sorted_df = df.sort_values(by='Age')
print(sorted_df)
```
在这个例子中,我们使用`sort_values`方法按照年龄列对DataFrame进行排序。默认情况下,排序是升序的,但我们可以设置`ascending=False`来进行降序排序。
## 3.2 数据聚合与分组
### 3.2.1 数据聚合方法
数据聚合是指将数据集中的多个数据点组合成单个数据点的过程。在pandas中,我们可以使用`groupby`和`agg`方法来执行数据聚合。
```python
# 计算每个姓名的平均年龄
grouped_data = df.groupby('Name')['Age'].agg('mean')
print(grouped_data)
```
在这个例子中,我们首先使用`groupby`方法按姓名对DataFrame进行分组,然后使用`agg`方法计算每个组的平均年龄。
### 3.2.2 分组操作实例
分组操作允许我们对数据集进行更复杂的分析。例如,我们可以计算每个分组的最小值、最大值和平均值。
```python
# 计算每个姓名的最小年龄、最大年龄和平均年龄
grouped_data = df.groupby('Name')['Age'].agg(['min', 'max', 'mean'])
print(grouped_data)
```
在这个例子中,我们使用`agg`方法一次性计算了每个分组的最小值、最大值和平均年龄。
### 3.2.3 多层次分组处理
在某些情况下,我们需要进行多层次的分组处理。例如,我们可以先按年龄分组,然后再按姓名分组。
```python
# 按年龄分组,然后按姓名分组
multi_grouped_data = df.groupby(['Age', 'Name']).agg('count')
print(multi_grouped_data)
```
在这个例子中,我们首先按年龄分组,然后在每个年龄组内按姓名分组,并计算每个组内的记录数。
## 3.3 数据合并与合并策略
### 3.3.1 基于键的合并
数据合并是将两个或多个DataFrame合并为一个的过程。在pandas中,我们可以使用`merge`方法来进行基于键的合并。
```python
# 创建另一个DataFrame
data2 = {'Name': ['Tom', 'Nick', 'John', 'Jane', 'Alice'],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df2 = pd.DataFrame(data2)
# 基于姓名合并DataFrame
merged_df = pd.merge(df, df2, on='Name')
print(merged_df)
```
在这个例子中,我们创建了一个新的DataFrame`df2`,包含姓名和薪水信息。然后,我们使用`merge`方法基于姓名合并两个DataFrame。
### 3.3.2 不同来源数据的合并
有时候,我们可能需要合并来自不同来源的数据。例如,我们可能需要将Excel文件中的数据与CSV文件中的数据合并。
```python
# 从Excel文件加载数据
excel_df = pd.read_excel('data.xlsx')
# 从CSV文件加载数据
csv_df = pd.read_csv('data.csv')
# 假设两个文件中都有'ID'列,我们可以基于'ID'合并这两个DataFrame
merged_df = pd.merge(excel_df, csv_df, on='ID')
print(merged_df)
```
在这个例子中,我们首先从Excel和CSV文件中加载数据,然后基于共同的'ID'列合并这两个DataFrame。
### 3.3.3 合并策略选择
在合并数据时,我们可能需要选择不同的合并策略。pandas提供了几种合并类型,如内连接(inner)、外连接(outer)、左连接(left)和右连接(right)。
```python
# 使用外连接合并DataFrame
merged_df_outer = pd.merge(df, df2, on='Name', how='outer')
print(merged_df_outer)
```
在这个例子中,我们使用`how='outer'`参数执行外连接合并,这意味着合并结果将包含所有记录,即使某些记录在某个DataFrame中不存在。
# 4. 高级数据处理技巧
## 4.1 数据透视表与交叉表
### 4.1.1 创建数据透视表
数据透视表是一种强大的数据分析工具,它可以快速地汇总、分析、探索和呈现大量数据。在Python中,我们可以使用`pandas`库中的`pivot_table`函数来创建数据透视表。这个函数允许我们根据一个或多个键对数据进行分组,并计算分组的汇总统计信息。
```python
import pandas as pd
# 示例数据
data = {
'日期': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-03'],
'产品': ['产品A', '产品B', '产品A', '产品B', '产品C'],
'销售额': [100, 150, 200, 250, 300],
'成本': [50, 75, 100, 125, 150]
}
df = pd.DataFrame(data)
# 创建数据透视表
pivot = pd.pivot_table(df, index='日期', columns='产品', values=['销售额', '成本'], aggfunc='sum')
print(pivot)
```
在上面的代码中,我们首先创建了一个包含日期、产品、销售额和成本的示例数据框。然后,我们使用`pivot_table`函数创建了一个数据透视表,其中`index`参数指定了行索引(日期),`columns`参数指定了列索引(产品),`values`参数指定了我们需要汇总的数据列(销售额和成本),而`aggfunc`参数指定了汇总函数(求和)。
### 4.1.2 调整数据透视表格式
创建了数据透视表之后,我们可能需要对它的格式进行调整。例如,我们可以重命名轴标签、调整列的顺序、应用格式化等。
```python
# 重命名轴标签
pivot = pivot.rename_axis(None, axis=1).rename_axis('日期', axis=0)
# 调整列的顺序
pivot = pivot[['销售额', '成本']]
# 应用格式化
pivot.style.format({'销售额': '{:,.2f}', '成本': '{:,.2f}'})
```
在上面的代码中,我们首先使用`rename_axis`方法重命名了轴标签,然后调整了列的顺序,最后应用了格式化,使得销售额和成本以货币格式显示。
### 4.1.3 使用交叉表分析数据
交叉表是一种特殊的透视表,用于计算分组的频率。在`pandas`中,我们可以使用`crosstab`函数来创建交叉表。
```python
# 创建交叉表
cross_tab = pd.crosstab(index=df['日期'], columns=df['产品'])
print(cross_tab)
```
在上面的代码中,我们使用`crosstab`函数创建了一个交叉表,其中`index`参数指定了行索引(日期),`columns`参数指定了列索引(产品)。交叉表会显示每个产品在不同日期的计数。
通过本章节的介绍,我们了解了如何在Python中使用`pandas`库创建和调整数据透视表和交叉表,以及如何进行数据分析。这些工具在处理和分析大量数据时非常有用,可以帮助我们快速获得洞察并做出决策。
# 5. Python data库实战案例
## 5.1 实战案例一:金融数据分析
在本章节中,我们将通过一个金融数据分析的实战案例,深入探讨如何运用Python的data库进行数据处理和分析。这个案例将包括数据准备与预处理、建立回归模型分析投资回报以及风险评估与预测。
### 5.1.1 数据准备与预处理
在进行金融数据分析之前,我们首先需要准备和预处理数据。这通常包括从不同来源收集数据,如数据库、CSV文件或网络API,并进行清洗和转换,以便于分析。
```python
import pandas as pd
import numpy as np
# 从CSV文件读取数据
df = pd.read_csv('financial_data.csv')
# 处理缺失值
df.fillna(method='ffill', inplace=True)
# 检测并处理异常值
# 例如,我们可以使用Z-score方法来检测异常值
z_scores = np.abs(stats.zscore(df.select_dtypes(include=[np.number])))
df = df[(z_scores < 3).all(axis=1)]
# 数据转换与归一化
# 假设有一个数值列'amount',我们将其转换为对数形式
df['amount'] = np.log(df['amount'])
# 保存处理后的数据到新的CSV文件
df.to_csv('cleaned_financial_data.csv', index=False)
```
在这个数据准备与预处理的代码块中,我们首先使用`pandas`库从CSV文件中读取数据,并使用`fillna`方法填充缺失值。接着,我们使用Z-score方法检测并处理异常值。最后,我们将数值列进行对数转换以归一化数据,并将处理后的数据保存到新的CSV文件中。
### 5.1.2 建立回归模型分析投资回报
金融数据分析的核心部分之一是建立模型来分析投资回报。在这个步骤中,我们将使用线性回归模型来预测投资回报。
```python
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 假设'investment_return'是我们想要预测的目标变量
X = df.drop('investment_return', axis=1)
y = df['investment_return']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算模型的均方误差
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
```
在这段代码中,我们首先划分数据集为训练集和测试集,然后创建并训练一个线性回归模型。最后,我们使用模型对测试集进行预测,并计算均方误差来评估模型性能。
### 5.1.3 风险评估与预测
除了分析投资回报,金融数据分析还需要评估投资的风险。在这里,我们将使用时间序列分析中的GARCH模型来预测投资的波动率,从而评估风险。
```python
from arch import arch_model
# 假设'investment_return'是我们想要分析波动率的时间序列数据
returns = df['investment_return']
# 创建GARCH模型
garch = arch_model(returns, vol='Garch', p=1, q=1)
# 拟合模型
garch_fit = garch.fit(disp='off')
# 获取预测的波动率
volatility = garch_fit.conditional_volatility
# 可视化波动率预测结果
volatility.plot()
```
在这段代码中,我们使用了`arch`库中的GARCH模型来拟合投资回报的时间序列数据,并计算预测的波动率。最后,我们通过绘图来可视化波动率的预测结果。
在本章节介绍的金融数据分析案例中,我们展示了如何使用Python的data库及其相关库进行数据的准备、预处理、建立回归模型以及风险评估。这些步骤是金融数据分析中常见的任务,通过实践这些操作,我们可以更好地理解数据,并做出更有根据的决策。
# 6. 性能优化与最佳实践
## 6.1 性能优化技巧
在处理大规模数据集时,性能优化是至关重要的。通过优化代码,我们可以显著减少运行时间,提高数据处理效率。
### 6.1.1 利用向量化操作提高效率
向量化是数据处理中一种强大的技术,它可以将循环操作转换为底层的矩阵运算,从而显著提高性能。
```python
import numpy as np
import pandas as pd
# 创建一个大型的DataFrame
data = np.random.randn(1000000, 10)
df = pd.DataFrame(data)
# 使用循环进行计算
def loop_operation(df):
result = []
for i in range(len(df)):
result.append(df.iloc[i].sum())
return result
# 使用向量化操作
def vectorized_operation(df):
return df.sum(axis=1)
# 测试性能
%timeit loop_operation(df) # 使用循环
%timeit vectorized_operation(df) # 使用向量化
```
在上述代码中,我们创建了一个包含100万行数据的DataFrame,并分别使用循环和向量化方法进行计算。通过`%timeit`魔法命令,我们可以看到向量化操作的性能远超循环。
### 6.1.2 多进程与并行处理
Python中的多进程可以通过`multiprocessing`模块实现,它可以帮助我们利用多核处理器的优势,加速数据处理。
```python
from multiprocessing import Pool
import numpy as np
def compute(x):
return [x[0] * x[1], x[0] + x[1]]
if __name__ == '__main__':
data = [(i, i) for i in range(1000)]
pool = Pool(processes=4) # 创建一个进程池
results = pool.map(compute, data) # 并行计算
pool.close()
pool.join()
```
在这个例子中,我们定义了一个简单的函数`compute`,然后创建了一个进程池来并行计算一系列元组。多进程可以显著减少大规模数据集的处理时间。
### 6.1.3 内存优化策略
在处理大型数据集时,内存使用也是一个重要考虑因素。合理使用内存可以避免不必要的内存溢出。
```python
import pandas as pd
# 创建一个大型的DataFrame
data = {'A': np.random.rand(1000000),
'B': np.random.rand(1000000)}
df = pd.DataFrame(data)
# 使用内存优化策略
def reduce_memory_usage(df):
for col in df.columns:
col_data = df[col]
dtype_str = str(col_data.dtype)
if dtype_str == 'float64':
c = col_data.values
df[col] = pd.to_numeric(pd.to_datetime(c), downcast='float')
elif dtype_str == 'object':
df[col] = c.astype('category')
return df
df_optimized = reduce_memory_usage(df)
```
在这个例子中,我们定义了一个函数`reduce_memory_usage`,它会将DataFrame中的列转换为更节省内存的数据类型。例如,将`float64`转换为`float32`,或者将`object`类型的列转换为`category`类型。
## 6.2 代码质量与调试技巧
高质量的代码是可靠和可维护的基础。通过代码审查、重构和调试,我们可以提高代码的健壮性和可读性。
### 6.2.1 代码审查与重构
代码审查是提高代码质量的有效方法。通过审查,我们可以发现潜在的错误和改进代码的机会。
```python
import numpy as np
def square(x):
# 原始代码可能存在性能问题
result = 0
for i in range(x):
result += i * i
return result
def square_optimized(x):
# 优化后的代码
return x * (x - 1) * (2 * x - 1) // 6
# 测试性能
x = 10000
%timeit square(x)
%timeit square_optimized(x)
```
在这个例子中,我们定义了两个计算平方数的函数,一个是原始的循环版本,另一个是优化后的数学公式版本。通过代码审查和重构,我们可以发现并改进性能瓶颈。
### 6.2.2 调试工具与方法
使用调试工具可以帮助我们更有效地找到代码中的错误。
```python
import pdb; pdb.set_trace() # 设置断点
def divide(a, b):
return a / b
result = divide(10, 0)
print(result)
```
在这个例子中,我们使用了Python的调试工具`pdb`。通过在代码中设置断点,我们可以逐步执行代码,检查变量的值,并找出错误所在。
### 6.2.3 错误处理与日志记录
良好的错误处理和日志记录可以帮助我们更好地理解和解决问题。
```python
import logging
logging.basicConfig(level=***)
def divide(a, b):
try:
result = a / b
except ZeroDivisionError as e:
logging.error(f"Error: {e}")
return None
return result
result = divide(10, 0)
print(result)
```
在这个例子中,我们定义了一个除法函数,并使用了`try`和`except`语句来捕获可能发生的`ZeroDivisionError`错误。同时,我们使用了日志记录来记录错误信息。
## 6.3 成为数据处理专家的路径
成为一名数据处理专家需要不断的学习和实践。
### 6.3.1 持续学习与资源推荐
持续学习是提升技能的关键。以下是一些推荐的学习资源:
- Coursera: 提供了大量数据科学和机器学习课程。
- Kaggle: 数据科学竞赛平台,提供了丰富的实际问题和数据集。
- GitHub: 学习他人的代码,参与开源项目。
### 6.3.2 实战项目的积累
通过参与实战项目,我们可以将理论知识应用到实践中。
```python
import pandas as pd
# 加载一个实战项目数据集
df = pd.read_csv('path_to_dataset.csv')
# 数据清洗
# ...
# 数据分析
# ...
# 结果可视化
# ...
```
在这个例子中,我们加载了一个实际的数据集,并进行了数据清洗、分析和可视化。通过实际操作,我们可以加深理解并提高技能。
### 6.3.3 社区参与与知识分享
参与社区活动和知识分享可以帮助我们建立联系并获得反馈。
- Stack Overflow: 解决编程问题的问答网站。
- Reddit: 讨论各种话题的论坛,包括数据科学。
- LinkedIn: 专业网络,可以找到同行和导师。
通过参与社区,我们可以获得新的见解和机会。
以上是第六章的内容,希望能帮助你更好地理解Python data库的性能优化和最佳实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python data 库学习专栏!本专栏将带你深入探索 data 库,掌握其基本使用、高级特性、实战技巧和性能优化方法。我们还将探讨数据清洗、预处理、数据分析、数据可视化、并发编程、内存管理、调试技巧和扩展开发等主题。此外,本专栏还将介绍 data 库与其他流行数据分析库的集成、单元测试、代码复用、版本控制和性能监控。通过本专栏,你将成为一名熟练的数据处理专家,能够高效地处理和分析数据,并创建健壮、可维护的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
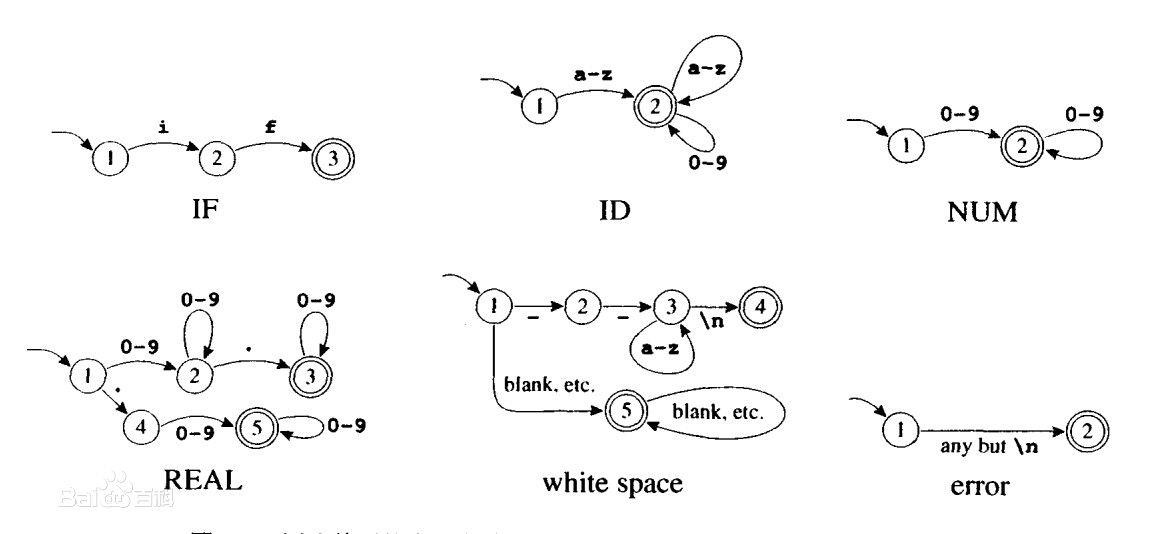
【编译原理实验报告解读】:燕山大学案例分析
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )