【PSO-SVM可视化技巧】:简单几步,让预测结果一目了然
发布时间: 2024-11-12 20:13:59 阅读量: 33 订阅数: 31 

pso-svm电力负荷预测.rar_PSO 预测_PSO优化SVM_svm负荷预测_svm预测

# 1. PSO-SVM算法基础
在本章中,我们将引入粒子群优化支持向量机(PSO-SVM)算法,并概述其作为机器学习领域中一个强大工具的基础。PSO-SVM结合了支持向量机(SVM)在分类和回归问题上的强大功能和粒子群优化(PSO)在全局优化上的效率。SVM利用数据空间的结构,能够处理线性和非线性问题,而PSO作为一种启发式优化算法,通过模拟鸟群的社会行为来寻找最优解,这种结合为解决复杂优化问题提供了新的视角。
SVM是基于统计学理论的一种机器学习方法,它主要通过找到一个最优超平面来实现对数据的分类。超平面的选择依赖于训练数据中最接近分类边界的点,这些点被称为支持向量。PSO算法则是通过不断迭代更新个体的位移和速度来接近最优解,其原理简单,但能在复杂多维空间中快速收敛至全局最优。
本章的主要目标是为读者提供PSO-SVM算法的入门知识,并为其后的深入分析和应用打下基础。我们会讨论PSO和SVM的理论基础以及如何将两者结合起来解决优化问题。随着章节的深入,我们将逐步揭示PSO-SVM的运作机制,并通过实践案例展示其在不同场景中的应用。
# 2. 理论基础与算法原理
### 2.1 SVM核心原理
支持向量机(Support Vector Machine, SVM)是一种有效的分类算法,在解决分类问题上有着广泛的应用。它在高维空间中寻找最优的决策边界,以此来最大化不同类别数据间的间隔。
#### 2.1.1 SVM的基本概念和目标函数
SVM的目标是寻找一个超平面,它能够将不同类别的数据分离开来,并且使得两类数据之间的间隔(也叫作间隔宽度或边距)最大化。这个超平面被称为最大间隔超平面。在实际应用中,数据往往不是线性可分的,这时候就引入了所谓的松弛变量(slack variables),允许部分数据违反间隔约束。
假设在n维特征空间中,有m个训练样本,每个样本具有n个特征,表示为 \( \{ (x_1, y_1), (x_2, y_2), ..., (x_m, y_m) \} \),其中 \( x_i \in \mathbb{R}^n \) 为特征向量,\( y_i \in \{-1, +1\} \) 为类别标签。SVM的目标函数如下:
\[ \min_{\omega, b} \frac{1}{2} ||\omega||^2 \]
\[ \text{subject to } y_i(\omega \cdot x_i + b) \geq 1 - \xi_i, \quad i = 1,...,m \]
这里的 \( \omega \) 表示超平面的法向量,\( b \) 是偏置项,\( \xi_i \) 是松弛变量,保证了数据可以被正确分类。
#### 2.1.2 核技巧与非线性问题的处理
当数据是非线性可分的时候,直接在原始特征空间中寻找最大间隔超平面变得复杂。这时,核技巧(Kernel Trick)被引入SVM中,它允许我们在高维空间中进行计算,而无需显式地映射数据到那个空间。核函数(Kernel Function)被用来计算两个数据点在高维空间中的内积,从而无需知道映射函数的具体形式。
核函数的例子包括线性核、多项式核、径向基函数(Radial Basis Function, RBF)核、以及Sigmoid核等。其中,RBF核由于其灵活的特性,尤其适用于解决非线性问题,其表达式如下:
\[ K(x, x') = \exp(-\gamma ||x - x'||^2) \]
其中,\( \gamma \) 是RBF核的一个重要参数,它决定了数据映射后的分布情况。
### 2.2 PSO算法概述
粒子群优化(Particle Swarm Optimization, PSO)是一种群体智能优化算法,它模拟鸟群捕食的行为。PSO通过粒子群体的迭代来寻找最优解,每个粒子代表了问题空间中的一个潜在解,并根据自己的经验(个体最优)和群体的经验(全局最优)来更新自己的位置和速度。
#### 2.2.1 PSO算法的工作原理
PSO初始化一组随机粒子,然后通过迭代过程不断更新每个粒子的速度和位置。每个粒子的速度代表了它在搜索空间中移动的方向和距离,而位置则代表了潜在的解决方案。
更新规则如下:
\[ v_{i}^{t+1} = w \cdot v_{i}^{t} + c_1 \cdot r_1 \cdot (p_{i}^{best} - x_{i}^{t}) + c_2 \cdot r_2 \cdot (g^{best} - x_{i}^{t}) \]
\[ x_{i}^{t+1} = x_{i}^{t} + v_{i}^{t+1} \]
这里,\( v_{i}^{t} \) 是粒子 \( i \) 在第 \( t \) 次迭代时的速度,\( x_{i}^{t} \) 是粒子的位置,\( p_{i}^{best} \) 是粒子的历史最佳位置,\( g^{best} \) 是整个群体的历史最佳位置,\( w \) 是惯性权重,\( c_1 \) 和 \( c_2 \) 是学习因子,\( r_1 \) 和 \( r_2 \) 是介于 \( [0, 1] \) 区间的随机数。
#### 2.2.2 粒子群优化的数学模型
粒子群优化算法的数学模型基于对粒子的动态行为进行建模。每个粒子都有一个适应度函数,这个函数用来评估粒子位置的好坏。粒子将根据适应度函数来更新自己的速度和位置,使得群体不断朝着更优的方向进化。
适应度函数是优化问题的一个重要组成部分,它决定了粒子的性能。对于SVM参数优化问题,适应度函数可以是分类准确率、F1分数、交叉验证得分等。
粒子群优化算法的关键步骤包括:
1. 初始化粒子的位置和速度。
2. 评价每个粒子的适应度。
3. 更新粒子的个体最优和群体最优。
4. 更新粒子的速度和位置。
5. 判断是否满足结束条件,如达到最大迭代次数或性能目标。
### 2.3 PSO与SVM结合的动机
在机器学习模型中,参数的选择对模型性能有着重要的影响。对于SVM来说,合适的参数能够显著提高模型的分类性能和泛化能力。
#### 2.3.1 参数优化的重要性
在SVM中,参数如C(正则化参数)、\( \gamma \)(RBF核的参数)、以及核函数的选择都对模型性能有着显著的影响。通过参数优化,可以找到模型性能最优化的参数组合,使得模型在测试集上的表现最佳。
#### 2.3.2 PSO在SVM参数优化中的应用
粒子群优化算法因其简单、高效的特点,在SVM参数优化中得到了广泛的应用。PSO可以高效地探索参数空间,寻找到一组最优或近似最优的参数,使得SVM模型达到最佳性能。通过将PSO用于SVM参数优化,不仅能够改善模型的分类精度,还能在一定程度上避免过拟合,提高模型的泛化能力。
总结来说,第二章主要介绍了SVM的核心原理和PSO算法的工作原理及其在SVM参数优化中的应用。通过结合这两种方法,我们能够有效地解决实际问题中SVM参数选择的问题,为后续的实战操作和案例研究打下坚实的理论基础。
# 3. PSO-SVM参数调优实战
## 3.1 PSO参数的选取与初始化
在使用粒子群优化(PSO)算法进行SVM参数调优之前,正确地选择和初始化PSO参数是至关重要的。这一过程不仅涉及到确定粒子群的规模和迭代次数,还包括采用何种策略来初始化粒子的位置和速度。
### 3.1.1 粒子群大小和迭代次数的确定
粒子群的大小和迭代次数是影响PSO算法性能的关键参数。粒子群大小决定了搜索空间内粒子的密度,而迭代次数决定了算法运行的总时间。选择太小的粒子群可能会导致搜索不充分,而太大的粒子群则会增加计算负担。通常,粒子群的大小可以从20到40不等,取决于问题的复杂度。迭代次数的选择需要平衡收敛速度和求解精度,通常在50到1000次之间。
### 3.1.2 参数初始化的策略
参数初始化需要确保粒子在搜索空间中具有良好的分布。通常,参数的初始值是随机选取的。而粒子的位置则代表了一个潜在的SVM参数组合。粒子的速度初始化则需要确保粒子能够有

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《PSO-SVM回归预测》专栏深入探讨了粒子群优化 (PSO) 在支持向量回归 (SVM) 预测中的应用。它提供了全面的指南,涵盖了 PSO-SVM 算法的各个方面,包括:
* 优化技巧:掌握 7 大技巧,提升 PSO-SVM 预测精度。
* 参数调优:专家秘诀,快速找到最佳参数组合。
* 交叉验证:确保模型泛化能力,避免过拟合。
* 可视化技巧:通过简单步骤,直观展示预测结果。
* 算法调优:提升算法效率和稳定性的专家分享。
该专栏旨在为读者提供全面的 PSO-SVM 知识,帮助他们构建高效、准确的预测模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
操作系统实验九深度解析:9个关键步骤助你实现理论到实践的飞跃

# 摘要
本文旨在对操作系统的基础理论与核心机制进行深入分析,并提供了实验操作与环境搭建的具体指南。首先,概述了操作系统的基本理论,并进一步探讨了进程管理、内存分配与回收、文件系统以及I/O管理等核心机制。接着,文章详细阐述了实验环境的配置,包括虚拟化技术的应用、开发工具的准备及网络安全设置。最后,通过操作系统实验九的具体操作,回顾理论知识,并针对
一步到位配置银河麒麟V10:新手必看环境搭建教程

# 摘要
本文全面介绍了银河麒麟V10操作系统的功能特点,重点探讨了基础环境配置、开发环境搭建、网络配置与安全、系统优化与定制以及高级操作指南。从系统安装与启动的基本步骤到软件源和包管理,再到开发工具、虚拟化环境及性能分析工具的配置,文章详细阐述了如何为开发和维护工作搭建一个高效的银河麒麟V10平台。此外,还讲解了网络配置、高级网络功能以及系统安全加固,提供了用户权限
微机原理与接口技术深度剖析:掌握楼顺天版课后题的系统理解(10个必须掌握的关键点)
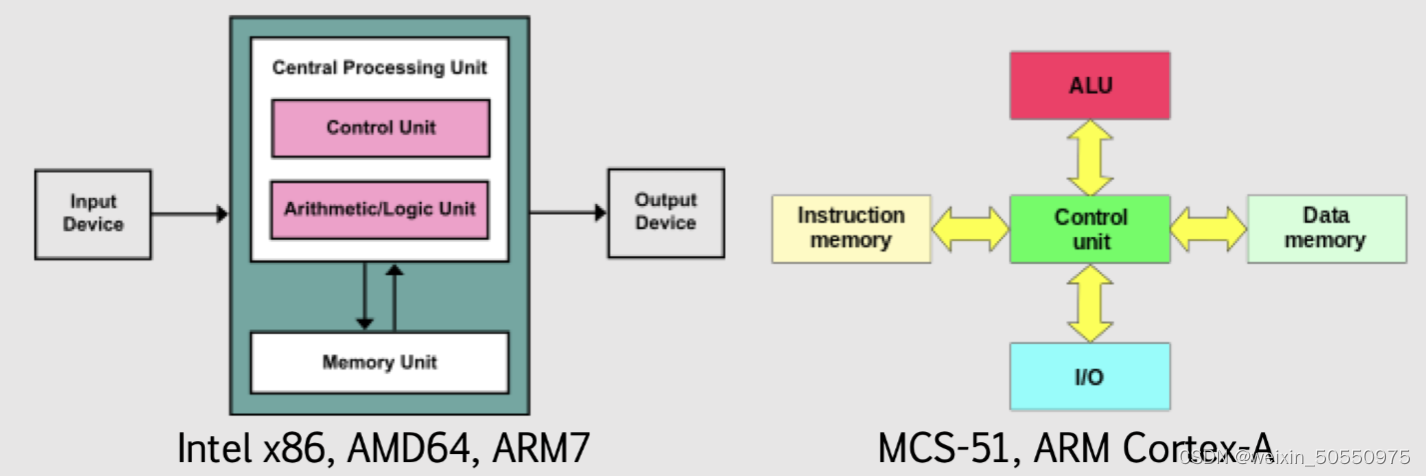
# 摘要
本文详细探讨了微机原理与接口技术,涵盖了微处理器架构、指令集解析、存储系统、输入输出设备和系统总线等关键技术领域。文章首先对微处理器的基本组成和工作原理进行了介绍,并对指令集的分类、功能以及寻址模式进行了深入分析。随后,本文探讨了存储器系统的层次结构、接口技术和I/O接口设计实践。在此基础上,文章分析了输入输出设备的分类与接口技术,以及系统总线的工作原理和I/O接
【SIL9013芯片全面解读】:解锁SIL9013芯片的20个核心秘密与应用技巧
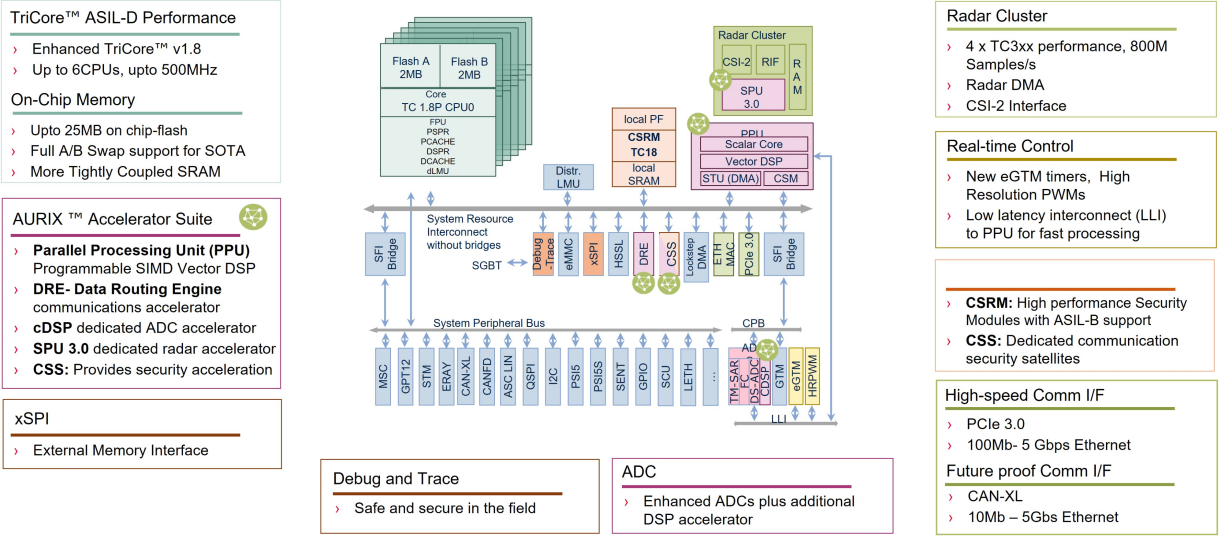
# 摘要
SIL9013芯片作为一款先进的半导体产品,在嵌入式系统、物联网设备和多媒体处理领域中具有广泛的应用。本文首先概述了SIL9013芯片的基本架构设计,包括其硬件组成、功能模块、数据传输机制和编程接口。随后,文章深入分析了SIL9013的电源管理策略
一步到位:掌握Citrix联机插件的终极安装与配置指南(附故障排查秘籍)

# 摘要
本文全面探讨了Citrix联机插件的安装、配置、故障排查以及企业级应用。首先介绍了Citrix插件的基本概念及安装前的系统要求。接着,详细阐述了安装过程、高级配置技巧和多用户管理方法。此外,本文还讨论了故障排查和性能优化的实践,包括利用日志文件进行故障诊断和系统资源监控。最后,本文探索了Citrix插件在不同行业中的应用案例,特别是大规模部署和管理策略,并展望了与
【深入解析】:揭秘CODESYS中BufferMode优化多段速运行的3大设置
# 摘要
CODESYS作为工业自动化领域的重要软件平台,其BufferMode功能对多段速运行和性能优化起到了关键作用。本文首先介绍了CODESYS基础和多段速运行的概念,随后深入探讨了BufferMode的理论基础、配置方法、性能优化以及在实践中的应用案例。通过分析实际应用中的性能对比和优化实践,本文总结了BufferMode参数调整的技巧,并探讨了其在复杂系
华为B610-4e路由器升级实战指南:R22 V500R022C10SPC200操作步骤

# 摘要
本文为华为B610-4e路由器的升级实战操作提供了一份全面的指南。从升级前的准备工作开始,涵盖了硬件检查、软件准备和升级计划的制定。接着,详细介绍了升级操作步骤,包括系统登录、固件升级前的准备、执行升级以及升级后的验证和调试。此外,本文还讨论了升级后的维护工作,如配置恢复与优化、性能监控与问题排除,并通过成功与失败案例分析,提炼了升级经验。最后,对华为B610-4e路由器升级的未来展望进行了探讨,包括技术发展、市场趋势和用
【内存管理黄金法则】:libucrt内存泄漏预防与性能优化秘籍
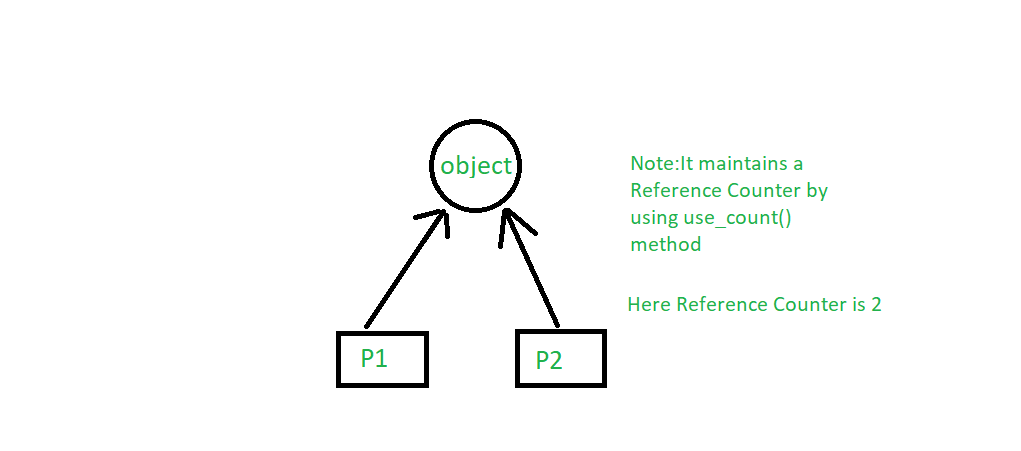
# 摘要
本文针对内存管理黄金法则进行概述,并深入探讨内存泄漏的识别与预防策略。通过分析内存泄漏的概念、危害、检测技术以及预防措施,本文旨在为开发者提供有效的内存管理工具和实践方法。文章还详细解析了libucrt内存管理机制,并通过实例和监控工具展示如何排查和解决内存泄漏问题。此外,本文探讨了性能优化的原则和方法,特别是针对libucrt内存管理的优化技巧,并分
【提升效率:Cadence CIS数据库性能优化】:实战秘籍,让你的数据库飞速响应
# 摘要
Cadence CIS数据库在高性能计算领域具有广泛应用,但其性能优化面临诸多挑战。本文从理论基础到实践技巧,系统性地介绍了性能优化的方法与策略。首先概述了数据库的架构特点及其性能挑战,随后分析了数据库性能优化的基本概念和相关理论,包括系统资源瓶颈和事务处理。实践章节详细讨论了索引、查询和存储的优化技巧,以及硬件升级对性能的提升。高级章节进一步探讨了复合索引、并发控制和内
【流程优化之王】:BABOK业务流程分析与设计技巧
# 摘要
随着企业对业务流程管理重视程度的提升,业务流程分析成为确保业务效率和优化流程的关键环节。本文从BABOK(Business Analysis Body of Knowledge)的角度,对业务流程分析的重要性和核心方法进行了全面探讨。首先,文章概括了业务流程的基础知识及其在商业成功中的作用。接着,深入分析了业务流程分析的核心技术,包括流程图和模型的制作、分析技术从数据流到价值流的应用,以及如何准确识别和定义业务需求。在设计阶段,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )