YARN日志管理:日志收集与故障分析的最佳实践
发布时间: 2024-10-27 09:41:08 阅读量: 4 订阅数: 7 
# 1. YARN日志管理概述
在大数据处理框架中,Hadoop YARN作为资源管理和作业调度的核心,对日志的管理起着至关重要的作用。YARN日志管理不仅关系到系统的稳定运行,还涉及到故障诊断、性能调优、安全审计等多个方面。一个良好的日志管理策略可以加快问题定位,提高系统维护效率,降低运营成本。本章我们将从YARN日志管理的基础概念出发,概述其重要性,并为后续章节对具体收集、分析、存储和优化等技术的讨论奠定基础。通过理解YARN日志管理的全貌,IT从业者可以更好地构建和维护大规模分布式系统。
# 2. YARN日志的收集技术
### 2.1 YARN日志收集机制基础
#### 2.1.1 YARN架构与日志流
Apache YARN(Yet Another Resource Negotiator)是Hadoop 2.x及以上版本中的资源管理器,负责集群资源分配和任务调度。YARN架构中,日志流是一个核心组成部分,它能够提供关于任务执行情况和集群运行状况的关键信息。
在YARN中,每个应用运行在由ApplicationMaster(AM)管理的容器(Container)中,这些容器可能会分布在集群的不同节点上。当应用执行时,相关的日志信息会生成在这些容器中。YARN的日志收集机制需要能够从分布式的容器中收集日志信息,然后将这些信息汇总到中心化的日志管理系统中,以便于后续的分析和故障排查。
#### 2.1.2 集群日志收集的必要性
在大型集群环境中,日志信息的收集尤为重要。如果无法有效地收集和管理日志,就会出现以下几个问题:
- **故障排查困难**:没有日志的辅助,故障的定位和修复将变得非常困难。
- **性能监控不足**:无法监控应用的性能状况,进而无法进行性能优化。
- **数据安全风险**:敏感信息可能因为日志未被妥善处理而泄露。
- **合规性问题**:很多行业规定要求记录和保留操作日志,以满足合规性要求。
因此,实现一个高效、可靠的日志收集机制对于运维和开发团队来说是至关重要的。
### 2.2 高效的日志收集工具
#### 2.2.1 日志收集工具的选择标准
选择合适的日志收集工具是实现有效日志管理的第一步。选择标准通常包括:
- **稳定性**:日志收集工具应该足够稳定,不能因为自身的问题影响到服务的正常运行。
- **性能**:高吞吐量和低延迟,能够高效处理大量日志数据。
- **扩展性**:能够轻松地扩展以适应不断增长的日志量和日志源数量。
- **灵活性**:支持多种日志格式和不同的日志源,以便于集成不同的系统和服务。
- **可管理性**:具有良好的监控、报警和管理功能,便于操作人员管理。
- **安全性**:保证日志数据传输和存储过程中的安全性。
#### 2.2.2 实战:配置和使用Flume
Flume是Apache软件基金会提供的一个分布式、可靠且可用的日志收集系统。Flume的核心是它有一个流式数据流模型,它允许用户构建灵活的数据流管道,其中源(Source)负责接收数据,通道(Channel)负责临时存储数据,汇(Sink)负责将数据移动到目标存储系统。
- **基本配置**:Flume配置通常定义在一个名为`flume.conf`的配置文件中。一个基本的配置示例如下:
```conf
# 定义一个agent,agent是source、sink和channel的容器
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 指定source类型,并配置相关的属性
a1.sources.r1.type = ***
***mand = tail -F /var/log/example.log
# 指定sink类型,并配置相关的属性
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /path/to/destination/directory
# 指定channel类型,并配置相关的属性
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source、sink和channel连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
```
- **详细解释**:
- **source**:`exec`类型表示该source将从指定的命令(这里是`tail -F /var/log/example.log`)中读取日志数据。
- **sink**:`file_roll`类型表示sink将收集到的日志数据写入文件系统。`sink.directory`定义了存储位置。
- **channel**:`memory`类型表示channel将使用内存来暂存事件数据,适用于低延迟的场景。
- **连接**:`a1.sources.r1.channels = c1`和`a1.sinks.k1.channel = c1`这两行将source和sink通过channel连接起来,确保数据可以从source流向sink。
#### 2.2.3 实战:配置和使用Logstash
Logstash是一个开源的服务器端数据处理管道,可以动态地将数据从各种来源收集整理,并将其发送到指定的目的地。
- **基本配置**:Logstash的配置文件通常是JSON格式的,也可以是YAML格式。以下是一个JSON格式的基本配置示例:
```json
input {
file {
path => "/var/log/example.log"
type => "syslog"
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGBASE}" }
}
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
```
- **详细解释**:
- **input**:`file`类型的input用于读取`/var/log/example.log`文件。`type`是一个事件字段,可以用于后续过滤和处理。
- **filter**:`grok`过滤器用于解析非结构化的文本数据并将

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Hadoop 作业在 YARN 中的提交和执行全流程,从客户端提交到 YARN 调度的各个环节。专栏涵盖了 YARN 的作业调度机制、队列管理策略、资源请求和分配原则,以及容量调度器和公平调度器的运作方式。此外,还提供了 YARN 作业优先级设置、监控工具、安全策略、内存管理优化、磁盘 I/O 管理、日志管理和容错机制的详细指南。最后,专栏还探讨了 YARN 集群的扩展性分析和作业性能调优技巧,帮助读者全面掌握 YARN 的工作原理和优化技术,从而提升大数据处理的效率和可靠性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Combiner使用全攻略】:数据处理流程与作业效率提升指南

# 1. Combiner概念解析
## 1.1 Combiner简介
Combiner是一种优化技术,用于在MapReduce
Bzip2压缩技术进阶:Hadoop大数据处理中的高级应用
# 1. Bzip2压缩技术概述
## 1.1 Bzip2的起源与功能
Bzip2是一种广泛应用于数据压缩的开源软件工具,最初由Julian Seward开发,其独特的压缩算法基于Burrows-Wheeler变换(BWT)和霍夫曼编码。该技术能够将文件和数据流压缩到较小的体积,便于存储和传输。
## 1.2 Bzip2的特点解析
Bzip2最显著的特点是其压缩率较高,通常能够比传统的ZIP和GZIP格式提供更好的压缩效果。尽管压缩和解压缩速度较慢,但在存储空间宝贵和网络传输成本较高的场合,Bzip2显示了其不可替代的优势。
## 1.3 Bzip2的应用场景
在多种场景中,Bzip2都
【最新技术探索】:MapReduce数据压缩新趋势分析

# 1. MapReduce框架概述
MapReduce 是一种用于大规模数据处理的编程模型。其核心思想是将计算任务分解为两个阶段:Map(映射)和Reduce(归约)。Map阶段将输入数据转化为一系列中间的键值对,而Reduce阶段则将这些中间键值对合并,以得到最终结果。
MapReduce模型特别适用于大数据处理领域,尤其是那些可以并行
【Hadoop集群集成】:LZO压缩技术的集成与最佳实践

# 1. Hadoop集群集成LZO压缩技术概述
随着大数据量的不断增长,对存储和计算资源的需求日益增加,压缩技术在数据处理流程中扮演着越来越重要的角色。LZO(Lempel-Ziv-Oberhumer)压缩技术以其高压缩比、快速压缩与解压的特性,在Hadoop集群中得到广泛应用。本章将概述Hadoop集群集成LZO压缩技术的背景、意义以及
Hadoop压缩技术在大数据分析中的角色:作用解析与影响评估
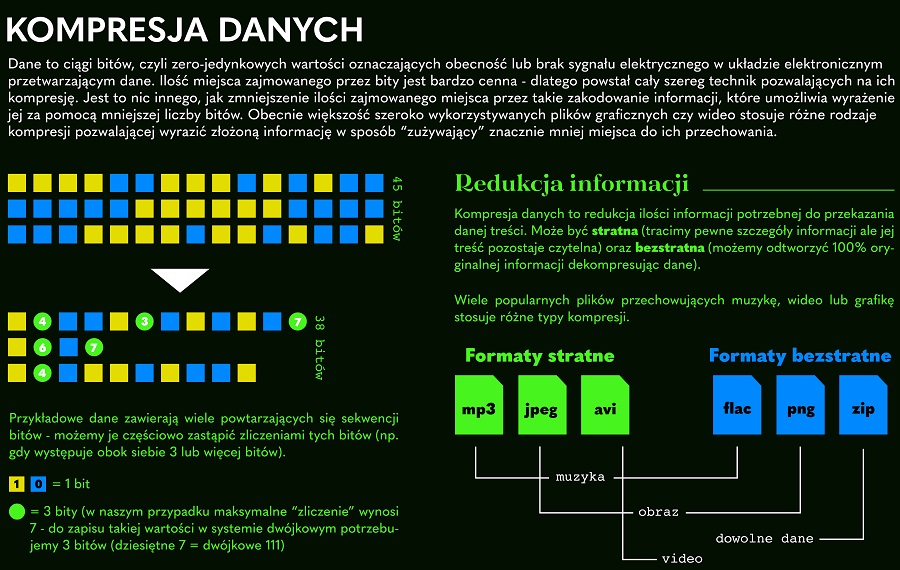
# 1. Hadoop压缩技术概述
在大数据的处理与存储中,压缩技术扮演着至关重要的角色。Hadoop作为一个分布式存储和处理的框架,它能够高效地处理大量数据,而这背后离不开压缩技术的支持。在本章中,我们将简要介绍Hadoop中的压缩技术,并探讨它如何通过减少数据的存储体积和网络
YARN作业性能调优:深入了解参数配置的艺术

# 1. YARN作业性能调优概述
## 简介
随着大数据处理需求的爆炸性增长,YARN(Yet Another Resource Negotiator)作为Hadoop生态中的资源管理层,已经成为处理大规模分布式计算的基础设施。在实际应用中,如何优化YARN以提升作业性能成为了大数据工程师必须面对的课题。
## YARN性能调优的重要
【Hadoop数据压缩】:Gzip算法的局限性与改进方向
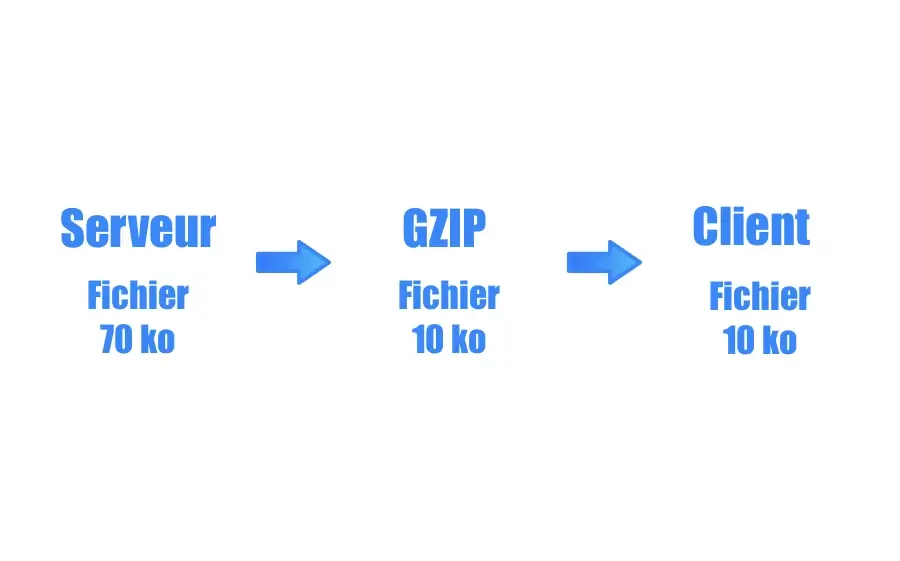
# 1. Hadoop数据压缩概述
随着大数据量的不断增长,数据压缩已成为提升存储效率和传输速度的关键技术之一。Hadoop作为一个分布式系统,其数据压缩功能尤为重要。本章我们将对Hadoop数据压缩进行概述,深入探讨压缩技术在Hadoop中的应用,并简要分析其重要性与影响。
## 1.1 Hadoop数据压缩的必要性
Hadoop集群处理的数据量巨大,有效的数据压缩可以减少存储成本,加快网络传输速度,
Hadoop中Snappy压缩的深度剖析:提升实时数据处理的算法优化

# 1. Hadoop中的数据压缩技术概述
在大数据环境下,数据压缩技术是优化存储和提升数据处理效率的关键环节。Hadoop,作为一个广泛使用的分布式存储和处理框架,为数据压缩提供了多种支持。在本章中,我们将探讨Hadoop中的数据压缩技术,解释它们如何提高存储效率、降低带宽使用、加快数据传输速度,并减少I/O操作。此外,我们将概述Hadoop内建的压缩编码器以及它们的优缺点,为后续章节深入探讨特定压缩算法
【Hadoop高可用性配置】:在完全分布式模式中打造HA的终极指南
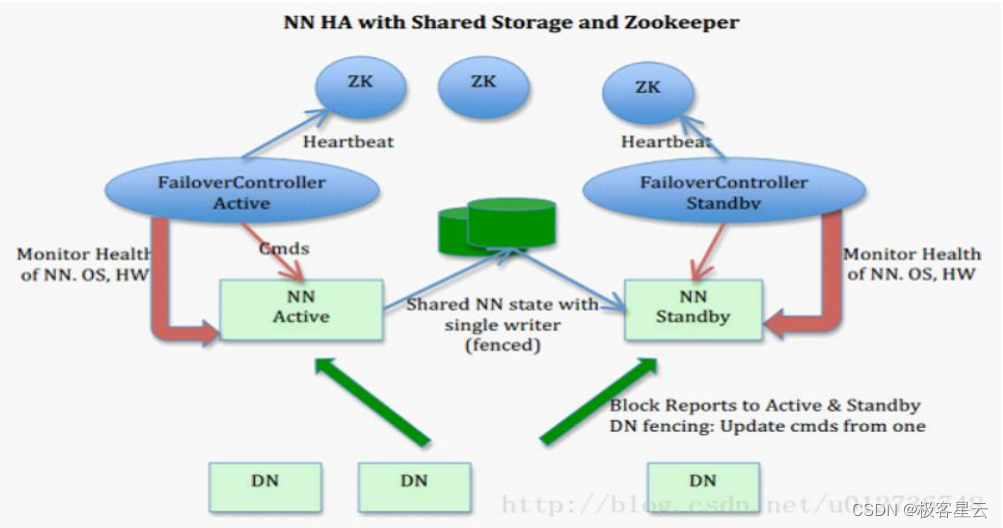
# 1. Hadoop高可用性架构概述
在分布式计算领域,Hadoop作为大数据处理的基石,其高可用性架构确保了大规模数据存储和处理的连续性和稳定性。Hadoop高可用性架构不仅仅是一个技术实现,它更是一种设计理念,旨在通过冗余和故障转移机制来防止单点故障,从而实现系统不间断运行的目标。
## 1.1 Hadoop高可用性的必要性
随着企业对数据分析的依赖日益增加,数据丢失或服务不可用
【Hadoop序列化性能分析】:数据压缩与传输优化策略
# 1. Hadoop序列化的基础概念
在分布式计算框架Hadoop中,序列化扮演着至关重要的角色。它涉及到数据在网络中的传输,以及在不同存储介质中的持久化。在这一章节中,我们将首先了解序列化的基础概念,并探讨它如何在Hadoop系统中实现数据的有效存储和传输。
序列化是指将对象状态信息转换为可以存储或传输的形式的过程。在Java等面向对象的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )