【深入HashSet应用】:Java中散列集合使用与性能调优的终极指南
发布时间: 2024-09-11 02:18:05 阅读量: 20 订阅数: 38 

# 1. HashSet的基本概念与原理
## HashSet简介
HashSet是Java集合框架的一个重要部分,它实现了Set接口。这一章节首先将引导我们了解HashSet的基本概念。本质上,HashSet是一个基于HashMap来存储元素的集合。理解这一点是理解HashSet工作原理的基础。
## HashSet的工作原理
HashSet的元素实际上是存储在内部的HashMap对象中,每个元素都是HashMap的key,而value则是一个固定的虚拟对象。这种设计允许HashSet在进行元素查找、添加和删除操作时,利用HashMap的O(1)时间复杂度优势。
## HashSet的优势
为什么使用HashSet?最大的优势在于它的高性能。当我们需要一个能够快速插入、删除和查找元素的集合时,HashSet无疑是很好的选择。其内部的HashMap保证了这一切操作的高效执行。然而,理解其背后的工作原理,可以帮助我们更好地使用和优化它。
# 2. 深入理解HashSet的工作机制
### 2.1 HashSet的内部数据结构
#### 2.1.1 Java中HashMap的实现原理
`HashSet` 在Java中是基于 `HashMap` 来实现的。了解 `HashMap` 的实现原理是掌握 `HashSet` 工作机制的关键。`HashMap` 是基于哈希表的 Map 接口实现,它允许使用 null 值和 null 键。它通过计算对象的哈希码,将键值对存储在哈希表数组中。
`HashMap` 主要由数组(Node<K,V>[] table)和链表组成,它使用一个哈希函数将键转换为数组中的索引位置,索引位置上的链表存储着具有相同哈希值的键值对。当多个元素的哈希值冲突时,新元素将被添加到链表的头部。
在 Java 8 中,当链表长度超过阈值(默认为 8)时,链表会转换为红黑树,这样能够提高插入、删除和查找操作的效率。
#### 2.1.2 HashSet与HashMap的关系
`HashSet` 内部实际上持有一个 `HashMap` 的实例来存储集合元素。当你向 `HashSet` 中添加元素时,实际上是对 `HashMap` 的 `put` 方法的调用。`HashSet` 的元素存储在 `HashMap` 的键中,而值则统一使用一个静态的虚拟对象。
换句话说,`HashSet` 的所有方法基本上都是通过调用 `HashMap` 的相应方法来实现的。例如,`contains` 方法实际调用的是 `HashMap` 的 `containsKey` 方法,而删除元素时调用的是 `HashMap` 的 `remove` 方法。
### 2.2 HashSet的元素添加与删除机制
#### 2.2.1 添加元素的步骤分析
当我们向 `HashSet` 添加元素时,首先会对该元素调用 `hashCode` 方法,根据返回的哈希值计算出其在 `HashMap` 中的位置索引。
```java
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
```
这里的 `map` 是 `HashSet` 内部的 `HashMap` 实例,`PRESENT` 是一个被用作占位符的静态对象。如果在计算出的索引位置上不存在其他元素(即没有发生哈希冲突),则元素直接被添加到 `HashMap` 的数组中。如果存在哈希冲突,则需要将新元素插入到链表或红黑树的相应位置。
#### 2.2.2 删除元素的流程探索
删除元素时,`HashSet` 也是通过调用内部 `HashMap` 的 `remove` 方法来实现的。`remove` 方法会返回被删除元素的值(如果存在),如果没有找到该元素,则返回 `null`。
```java
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
```
在删除过程中,如果元素位于链表中,需要遍历链表查找并删除对应元素。如果元素位于红黑树中,则会利用树的特性快速定位和删除元素。
### 2.3 HashSet的性能特点
#### 2.3.1 时间复杂度分析
`HashSet` 的时间复杂度主要取决于 `HashMap` 的实现。理想情况下,如果没有发生哈希冲突,`HashSet` 的操作(添加、删除、查找)的时间复杂度为 O(1)。在最坏的情况下,所有元素都发生哈希冲突,退化为链表,时间复杂度则为 O(n)。
#### 2.3.2 空间利用率探讨
`HashSet` 的空间利用率受到 `HashMap` 内部数组大小的限制。数组的大小是基于其负载因子和当前元素数量动态计算的。如果空间利用率过高,会增加哈希冲突的概率,影响性能;如果利用率过低,则会浪费内存资源。
一般情况下,负载因子默认为 0.75,这个值是一个空间利用率和时间效率的折中。开发者可以根据实际情况调整这个负载因子以优化性能。
# 3. HashSet在实际开发中的应用
在第三章中,我们将深入探讨HashSet在实际开发中的应用。我们会详细地了解HashSet的典型应用场景,包括唯一性数据存储和快速检索与匹配。此外,我们将对HashSet与TreeSet和LinkedHashSet这两个集合进行比较,以分析它们的优缺点。最后,我们会探讨HashSet在Java集合框架中的地位,以及它在处理数据时起到的作用。
## 3.1 HashSet的典型应用场景
### 3.1.1 唯一性数据存储
HashSet由于其独特的数据结构,非常适合用于存储唯一性的数据集合。在处理大量数据时,它允许用户快速判断某个元素是否已经存在于集合中,而无需进行线性搜索,大大提升了性能。
在实际开发中,我们经常会遇到需要存储不重复数据的场景。比如用户信息管理,我们不希望用户表中有重复的用户存在,使用HashSet可以很好地保证这一点。
#### 示例代码:
```java
Set<String> userSet = new HashSet<>();
userSet.add("Alice");
userSet.add("Bob");
userSet.add("Charlie");
// 尝试添加重复项
boolean isAdded = userSet.add("Alice");
// 输出结果为false,因为Alice已经在集合中
System.out.println("Is Alice added: " + isAdded);
```
在上述代码中,尝试添加重复的项"Alice"时,会发现结果为`false`,表示Alice并未被添加,因为HashSet保证了其存储的数据唯一性。
#### 性能分析:
当使用HashSet存储数据时,其时间复杂度为O(1),这是因为HashSet底层依赖于HashMap,而HashMap的`put`操作平均情况下时间复杂度为O(1)。这种方式可以保证在大量数据添加和查找时,性能的稳定与高效。
### 3.1.2 快速检索与匹配
快速检索是HashSet的另一个重要特性。它允许开发者快速地判断集合中是否包含某个元素,这对于需要频繁查询的应用场景尤其有用。
例如,当我们在构建一个字典系统时,我们可能会存储大量的单词以及它们的定义,用户需要能够快速地查询到单词的定义。此时,使用HashSet来存储单词,可以实现快速检索的需求。
#### 示例代码:
```java
Set<String> dictionary = new HashSet<>();
dictionary.add("algorithm");
dictionary.add("data structure");
dictionary.add("computer science");
// 快速检索"algorithm"
boolean isFound = dictionary.contains("algorithm");
// 输出结果为true
System.out.println("Is 'algorithm' found: " + isFound);
```
在这个示例中,我们仅需一行`contains`方法调用,即可实现快速检索。如果使用传统数组或者链表,就需要遍历整个数据结构才能得到结果,其时间复杂度为O(n)。
#### 性能分析:
检索操作的时间复杂度同样为O(1),这是因为HashSet内部通过哈希码直接定位元素所在桶位,然后进行比较。因此,它在快速检索的场景中具有巨大的优势。
## 3.2 HashSet与其他集合的对比
在本节中,我们将对HashSet进行更深入的分析,通过对比HashSet、TreeSet和LinkedHashSet这三个集合,来讨论它们在不同场景下的适用性。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Java 中的数据结构散列,从原理到应用,提供全面而实用的指南。它涵盖了散列算法、冲突处理、散列函数设计、HashMap 和 HashSet 的内部机制、LinkedHashMap 的特性、TreeMap 与 HashMap 的对比、线程安全的散列集合、HashMap 的新特性、equals 和 hashCode 协议、ConcurrentHashMap 的并发性、散列数据结构在缓存优化和数据库索引中的应用、自定义散列函数、WeakHashMap 的内存管理、散列数据结构的性能测试、内存泄漏预防和 IdentityHashMap 的妙用。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者掌握散列数据结构的精髓,构建高效的检索系统,优化数据存储和检索效率,并提升并发环境下的数据结构使用能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
索引与数据结构选择:如何根据需求选择最佳的Python数据结构

# 1. Python数据结构概述
Python是一种广泛使用的高级编程语言,以其简洁的语法和强大的数据处理能力著称。在进行数据处理、算法设计和软件开发之前,了解Python的核心数据结构是非常必要的。本章将对Python中的数据结构进行一个概览式的介绍,包括基本数据类型、集合类型以及一些高级数据结构。读者通过本章的学习,能够掌握Python数据结构的基本概念,并为进一步深入学习奠
【Python项目管理工具大全】:使用Pipenv和Poetry优化依赖管理

# 1. Python依赖管理的挑战与需求
Python作为一门广泛使用的编程语言,其包管理的便捷性一直是吸引开发者的亮点之一。然而,在依赖管理方面,开发者们面临着各种挑战:从包版本冲突到环境配置复杂性,再到生产环境的精确复现问题。随着项目的增长,这些挑战更是凸显。为了解决这些问题,需求便应运而生——需要一种能够解决版本
【递归与迭代决策指南】:如何在Python中选择正确的循环类型
# 1. 递归与迭代概念解析
## 1.1 基本定义与区别
递归和迭代是算法设计中常见的两种方法,用于解决可以分解为更小、更相似问题的计算任务。**递归**是一种自引用的方法,通过函数调用自身来解决问题,它将问题简化为规模更小的子问题。而**迭代**则是通过重复应用一系列操作来达到解决问题的目的,通常使用循环结构实现。
## 1.2 应用场景
递归算法在需要进行多级逻辑处理时特别有用,例如树的遍历和分治算法。迭代则在数据集合的处理中更为常见,如排序算法和简单的计数任务。理解这两种方法的区别对于选择最合适的算法至关重要,尤其是在关注性能和资源消耗时。
## 1.3 逻辑结构对比
递归
【Python字典的并发控制】:确保数据一致性的锁机制,专家级别的并发解决方案

# 1. Python字典并发控制基础
在本章节中,我们将探索Python字典并发控制的基础知识,这是在多线程环境中处理共享数据时必须掌握的重要概念。我们将从了解为什么需要并发控制开始,然后逐步深入到Python字典操作的线程安全问题,最后介绍一些基本的并发控制机制。
## 1.1 并发控制的重要性
在多线程程序设计中
Python列表与数据库:列表在数据库操作中的10大应用场景

# 1. Python列表与数据库的交互基础
在当今的数据驱动的应用程序开发中,Python语言凭借其简洁性和强大的库支持,成为处理数据的首选工具之一。数据库作为数据存储的核心,其与Python列表的交互是构建高效数据处理流程的关键。本章我们将从基础开始,深入探讨Python列表与数据库如何协同工作,以及它们交互的基本原理。
## 1.1
Python函数性能优化:时间与空间复杂度权衡,专家级代码调优
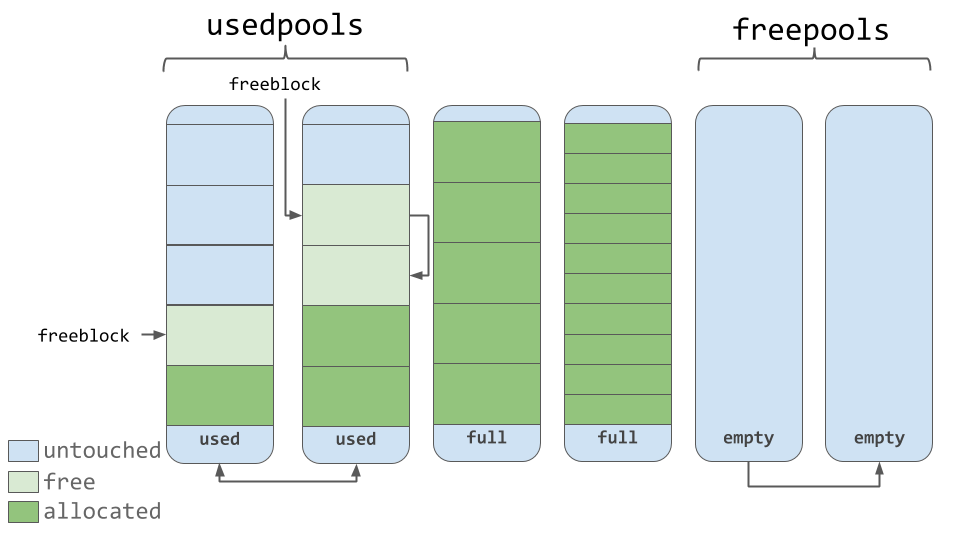
# 1. Python函数性能优化概述
Python是一种解释型的高级编程语言,以其简洁的语法和强大的标准库而闻名。然而,随着应用场景的复杂度增加,性能优化成为了软件开发中的一个重要环节。函数是Python程序的基本执行单元,因此,函数性能优化是提高整体代码运行效率的关键。
## 1.1 为什么要优化Python函数
在大多数情况下,Python的直观和易用性足以满足日常开发
Python索引的局限性:当索引不再提高效率时的应对策略

# 1. Python索引的基础知识
在编程世界中,索引是一个至关重要的概念,特别是在处理数组、列表或任何可索引数据结构时。Python中的索引也不例外,它允许我们访问序列中的单个元素、切片、子序列以及其他数据项。理解索引的基础知识,对于编写高效的Python代码至关重要。
## 理解索引的概念
Python中的索引从0开始计数。这意味着列表中的第一个元素
Python装饰模式实现:类设计中的可插拔功能扩展指南
# 1. Python装饰模式概述
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许动态地添加或修改对象的行为。在Python中,由于其灵活性和动态语言特性,装饰模式得到了广泛的应用。装饰模式通过使用“装饰者”(Decorator)来包裹真实的对象,以此来为原始对象添加新的功能或改变其行为,而不需要修改原始对象的代码。本章将简要介绍Python中装饰模式的概念及其重要性,为理解后
Python递归与迭代:查找场景对比及最佳选择指南

# 1. 递归与迭代的基本概念
在编程领域,"递归"和"迭代"是两个基本的程序执行方法,它们在解决问题时各自拥有独特的特点和应用场景。递归是通过函数自我调用,即函数内部调用自身,来解决问题的一种编程技术。而迭代则是在循环控制结构(如for和while循环)中重复执行一系列操作
Python list remove与列表推导式的内存管理:避免内存泄漏的有效策略
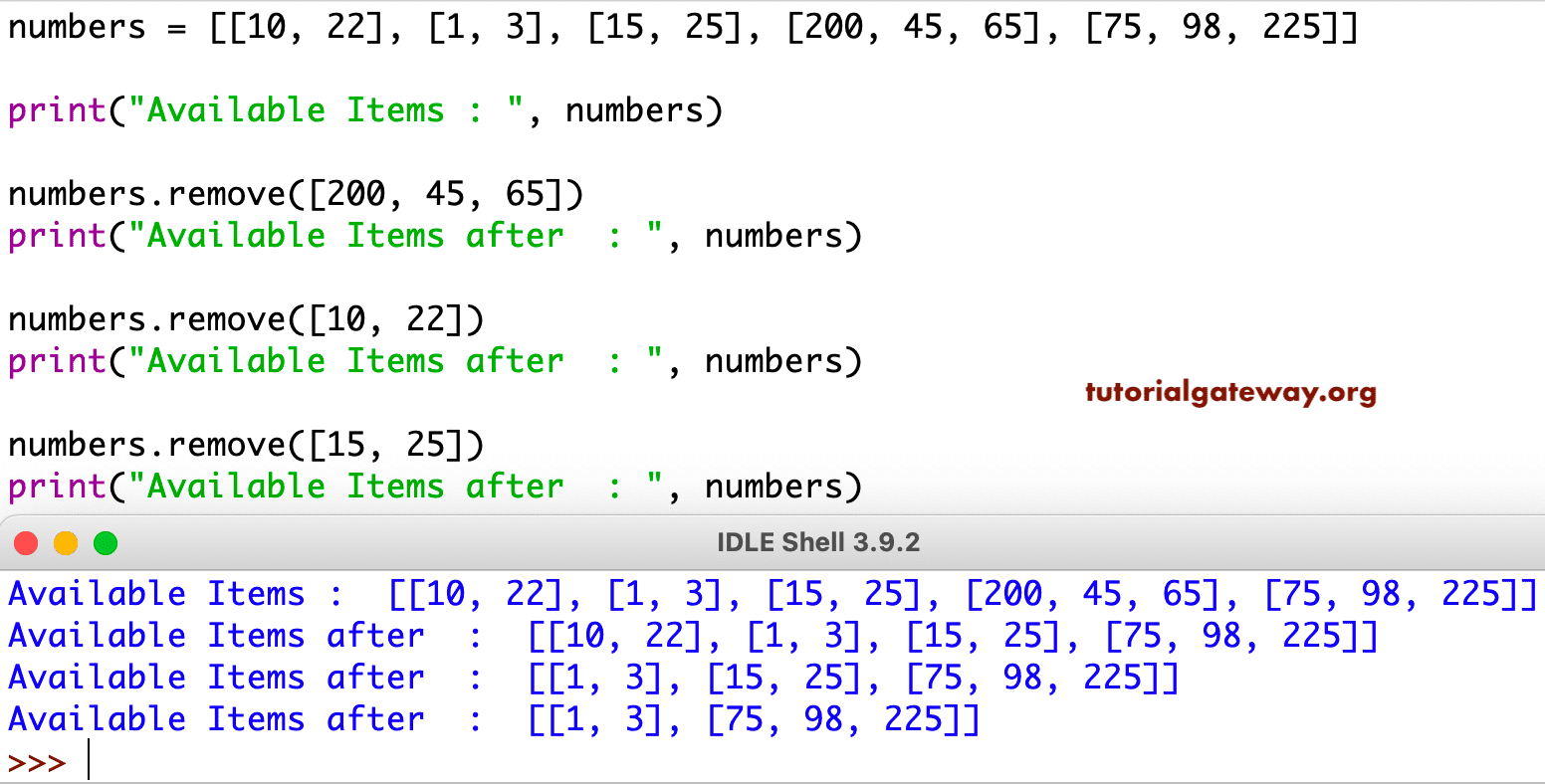
# 1. Python列表基础与内存管理概述
Python作为一门高级编程语言,在内存管理方面提供了众多便捷特性,尤其在处理列表数据结构时,它允许我们以极其简洁的方式进行内存分配与操作。列表是Python中一种基础的数据类型,它是一个可变的、有序的元素集。Python使用动态内存分配来管理列表,这意味着列表的大小可以在运行时根据需要进
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )