【数据库操作效率的飞跃】:Sakila存储过程编写与优化全攻略
发布时间: 2024-12-17 18:37:35 阅读量: 5 订阅数: 6 

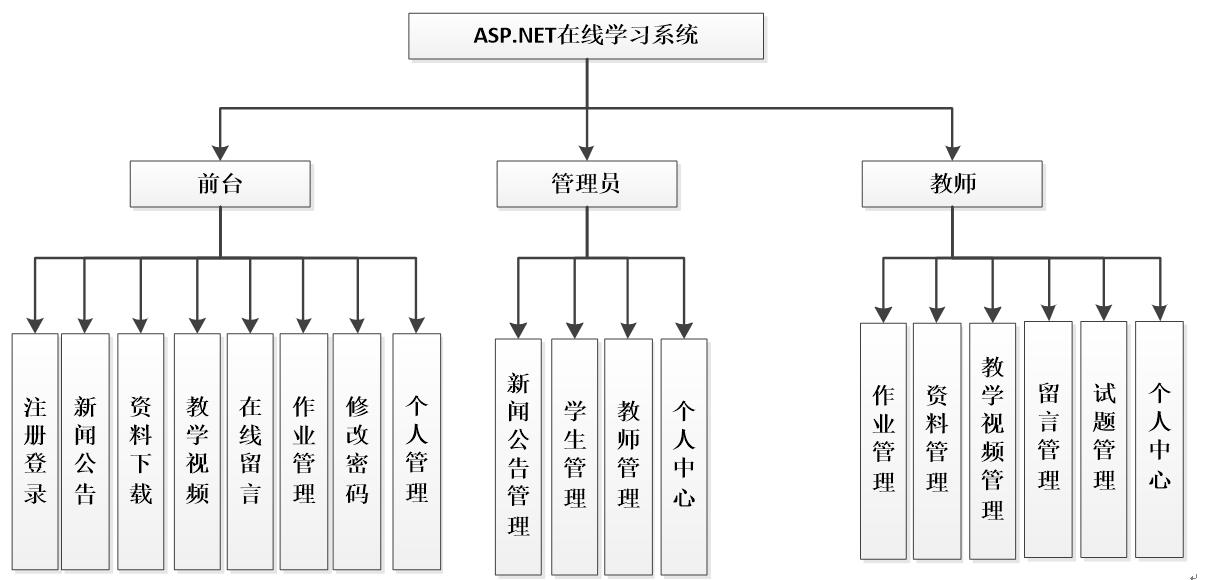
数据库实验一 基于Sakila的数据库操作

参考资源链接:[Sakila数据库实验:操作与查询解析](https://wenku.csdn.net/doc/757wzzzd7x?spm=1055.2635.3001.10343)
# 1. Sakila数据库存储过程概述
Sakila数据库是一个开源的电影租赁演示数据库,通常用于学习和测试SQL语句。存储过程作为数据库管理中的重要组件,在该数据库的维护和优化中发挥着关键作用。本文将深入探讨存储过程的概念、开发技巧以及如何在Sakila数据库中实现存储过程以提高数据操作的效率和安全性。
在开始之前,让我们先定义存储过程。存储过程是存储在数据库中的一组预编译的SQL语句,它们可以根据输入的参数执行一系列操作,并可以返回结果集。在Sakila数据库中,存储过程可以用来自动化常见的业务逻辑,如电影的租赁、归还,以及定期的报表生成等。
接下来的章节将从存储过程的基础知识和开发技巧开始,深入到性能优化和实际应用案例,帮助读者构建高效、可靠的存储过程。通过本文的学习,即使是经验丰富的IT专业人员也能发现提升自身技能的新方法。
# 2. 存储过程的基础与开发技巧
## 2.1 存储过程的定义和作用
### 2.1.1 什么是存储过程
存储过程是一组为了完成特定功能的SQL语句集,它预编译后存储在数据库中,用户通过指定存储过程的名字并传入参数来调用执行。存储过程可以包含复杂的逻辑,包括控制流语句如循环、条件分支等,也可以调用其他数据库对象如视图、触发器和函数。它们通常用于实现业务规则、数据访问和维护等操作。
在多个方面,存储过程提供了不同于单个SQL语句的优势:
- **执行效率**: 由于存储过程是预编译的,它们通常比相同功能的普通SQL语句执行得更快。
- **模块化**: 存储过程有助于将复杂的业务逻辑封装起来,使得数据库结构和应用逻辑更加清晰。
- **安全性**: 存储过程可以通过权限控制来管理对数据的访问,提高系统的安全性。
- **网络通信**: 减少客户端与服务器之间的通信次数,通过一次调用完成多个任务,减轻网络负担。
### 2.1.2 存储过程与普通SQL语句的区别
存储过程与普通的SQL语句最主要的区别在于它们的使用方式、复用性以及性能优势。下面列出了两者的关键差异点:
- **执行方式**: 存储过程可以在服务器端执行,而普通的SQL语句通常是客户端直接发送给服务器执行。
- **复用性**: 存储过程在数据库中预编译并存储,可以被多次调用,而普通的SQL语句通常是用完即弃。
- **性能**: 存储过程能够减少网络传输量,因为它们执行较少的SQL语句调用,同时减少了编译和解析的需要。
- **安全性**: 存储过程可以封装数据逻辑,隐藏表结构细节,避免直接的SQL注入风险。
- **维护性**: 存储过程的维护可以在服务器端集中进行,而普通的SQL语句散布在客户端代码中,更难以管理。
## 2.2 存储过程的创建与编辑
### 2.2.1 编写存储过程的语法基础
在数据库中创建存储过程的基本语法结构通常如下(以MySQL为例):
```sql
DELIMITER //
CREATE PROCEDURE procedure_name([IN parameter_list, OUT parameter_list])
BEGIN
-- 存储过程主体代码
-- 包括逻辑控制、SQL语句、数据操作等
END //
DELIMITER ;
```
以下是一个简单的存储过程示例,用于获取Sakila数据库中给定film_id的影片信息:
```sql
DELIMITER //
CREATE PROCEDURE GetFilmInfo(IN film_id_param INT)
BEGIN
SELECT * FROM film
WHERE film_id = film_id_param;
END //
DELIMITER ;
```
这个存储过程接受一个整数类型的参数`film_id_param`,并从`film`表中选择对应的记录返回。
### 2.2.2 参数的传递与处理
存储过程可以拥有输入参数(IN)、输出参数(OUT)以及输入/输出参数(INOUT)。这允许在调用过程中向存储过程传递数据,并且在完成操作后返回数据。
- **输入参数(IN)**: 允许调用者向存储过程传递数据,但存储过程内部不能修改参数本身的值。
- **输出参数(OUT)**: 允许存储过程内部对参数进行修改,并将修改后的值返回给调用者。
- **输入/输出参数(INOUT)**: 结合了输入和输出参数的功能,既可以从外部接收数据,也可以修改并返回数据。
下面是一个使用输入、输出参数的存储过程示例:
```sql
DELIMITER //
CREATE PROCEDURE UpdateFilmRating(IN film_id_param INT, OUT new_rating VARCHAR(10))
BEGIN
UPDATE film
SET rating = 'PG-13' -- 假设我们更新所有影片的等级
WHERE film_id = film_id_param;
SELECT rating INTO new_rating FROM film WHERE film_id = film_id_param;
END //
DELIMITER ;
```
在这个例子中,我们提供了一个电影ID和一个输出参数来接收新的影片评级。
### 2.2.3 返回结果集与输出参数
除了返回结果集以外,存储过程还可以使用输出参数来返回特定的数据。输出参数允许存储过程在完成操作后,将特定的数据传递回调用者。
在调用存储过程时,可以使用`CALL`语句,并通过`OUT`关键字声明的变量来接收输出参数的值:
```sql
CALL UpdateFilmRating(1, @new_rating);
SELECT @new_rating;
```
在上面的例子中,`UpdateFilmRating`存储过程更新了电影的评级,并将新的评级值存储在`@new_rating`变量中,然后我们可以查询这个变量来获取结果。
## 2.3 存储过程中的逻辑控制
### 2.3.1 分支控制结构
在存储过程中,分支控制结构允许基于条件执行不同的代码块。最常用的分支控制语句是`IF`...`THEN`...`ELSE`...`END IF`结构,它可以按照条件分支执行不同的逻辑。
以下是使用`IF`语句的存储过程示例:
```sql
DELIMITER //
CREATE PROCEDURE CheckFilmLength(IN film_length INT, OUT status VARCHAR(10))
BEGIN
IF film_length > 120 THEN
SET status = 'Long';
ELSE
SET status = 'Short';
END IF;
END //
DELIMITER ;
```
这个存储过程根据传入的影片长度,通过`IF`语句判断影片长度是否超过120分钟,并将结果存储在输出参数`status`中。
### 2.3.2 循环控制结构
循环控制结构在存储过程中用于重复执行代码块直到满足特定条件。在MySQL中,常用的循环控制语句包括`WHILE`循环、`REPEAT`循环和`LOOP`。
- **WHILE循环**: 检查条件,如果条件为真则执行循环体。
- **REPEAT循环**: 先执行一次循环体,然后检查条件。
- **LOOP循环**: 无限循环直到被外部的`LEAVE`语句终止。
下面是一个使用`WHILE`循环的示例:
```sql
DELIMITER //
CREATE PROCEDURE IncrementValue(IN max_value INT)
BEGIN
DECLARE current_value INT DEFAULT 0;
WHILE current_value < max_value DO
-- 假设这里是某种更新逻辑
UPDATE table_name SET column_name = column_name + 1;
SET current_value = current_value + 1;
END WHILE;
END //
DELIMITER ;
```
在这个例子中,`IncrementValue`存储过程使用`WHILE`循环来更新表中的列值。
### 2.3.3 事务与错误处理
事务控制和错误处理是存储过程中不可或缺的部分,以确保数据的一致性和健壮性。
- **事务控制**: 允许将多个SQL语句打包,将它们作为单个单元执行。事务

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据库实验一:基于 Sakila 的操作》专栏深入探讨了 Sakila 数据库的各个方面,提供了一系列实用指南,帮助数据库管理员和开发人员优化数据库性能、增强数据一致性、提高操作效率和安全性。专栏内容涵盖了从数据库设计和事务处理到存储过程、触发器和视图的广泛主题。此外,专栏还介绍了自动化数据分析、架构升级、负载均衡、定时任务和性能维护策略,以及资源使用效率提升和数据访问速度优化等技术细节。通过对 Sakila 数据库的深入分析,该专栏为读者提供了宝贵的见解,帮助他们构建健壮、高效且安全的数据库系统。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
1stOpt 5.0模块化编程指南:中文手册的模块扩展实战
参考资源链接:[1stOpt 5.0中文使用手册:全面解析与功能指南](https://wenku.csdn.net/doc/n57wf9bj9d?spm=1055.2635.3001.10343)
# 1. 1stOpt 5.0模块化编程概览
## 简介
1stOpt 5.0作为一个先进的优化软件工具,其核心设计理念之一就是模块化编程。它允许开发者通过构建、管理和扩展模块来简化复杂
Thermo-calc中文版高级功能全面解读

参考资源链接:[Thermo-Calc中文用户指南:入门与精通](https://wenku.csdn.net/doc/5hpcx03vej?spm=1055.2635.3001.10343)
# 1. Thermo-calc中文版概览
Thermo-calc是一个强大的材料热力学计算软件,为材料科学家、工程师和研究人员提供
DATALOGIC M120扫描枪固件更新指南:确保设备安全与性能的秘诀
参考资源链接:[DATALOGIC得利捷M120扫描枪配置说明V0.2版本20201105.doc](https://wenku.csdn.net/doc/6401acf0cce7214c316edb26?spm=1055.2635.3001.10343)
# 1. DATALOGIC M120扫描枪概述
DATALOGIC M120扫描枪是市场上广泛认可的一款高效、可靠的扫描设备,专为需要高精度数据捕获的应用场景设计。它采用了先进的扫描技术,能够快速识别各种类型的条码,包括1D、2D条码和直接部件标记(DPM)。DATALOGIC M120不仅具备出色的扫描能力,还因其坚固耐用的设计而在各
DW1000移动应用管理指南:远程控制与管理的利器
参考资源链接:[DW1000用户手册中文版:配置、编程详解](https://wenku.csdn.net/doc/6412b745be7fbd1778d49b3b?spm=1055.2635.3001.10343)
# 1. DW1000移动应用管理概述
## 1.1 DW1000移动应用管理的重要性
在现代企业环境中,移动应用已成为连接用户、服务和数据的
【代码变更识别术】:深入Source Insight代码比对功能,高效管理代码版本
参考资源链接:[Source Insight 4护眼模式:黑色主题配置](https://wenku.csdn.net/doc/zhzh1hoepv?spm=1055.2635.3001.10343)
# 1. 版本管理与代码比对概述
在现代软件开发中,版本控制与代码比对是确保
呼叫记录分析:FreePBX通讯流程优化指南

参考资源链接:[FreePBX中文安装与设置指南](https://wenku.csdn.net/doc/uos8ozn9rh?spm=1055.2635.3001.10343)
# 1. FreePBX呼叫记录分析基础
## 1.1 呼叫记录分析的重要性
呼叫记录分析对于维护和优化企业通信系统是至关重要的。通过细致
KUKA系统软件变量表的数据校验与清洗:确保数据准确性与完整性
参考资源链接:[KUKA机器人系统变量表(8.1-8.4版本):官方详细指南](https://wenku.csdn.net/doc/6412b488be7fbd1778d3fe83?spm=1055.2635.3001.10343)
# 1. KUKA系统
【故障排除】:IntelliJ IDEA中配置Tomcat服务器的常见坑,避免这些坑,让你的开发更加顺滑
参考资源链接:[IntelliJ IDEA中Tomcat配置未找到问题详解与解决步骤](https://wenku.csdn.net/doc/3y6cdcjogy?spm=1055.2635.3001.10343)
# 1. IntelliJ IDEA与
【ANSYS AUTODYN案例研究】:复杂结构动态响应的剖析

参考资源链接:[ANSYS AUTODYN二次开发实战指南](https://wenku.csdn.net/doc/6412b713be7fbd1778d49019?spm=1055
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )