tm包数据转换工具的使用与原理:R语言文本分析的进阶理解


使用R语言的数据分析代码.zip
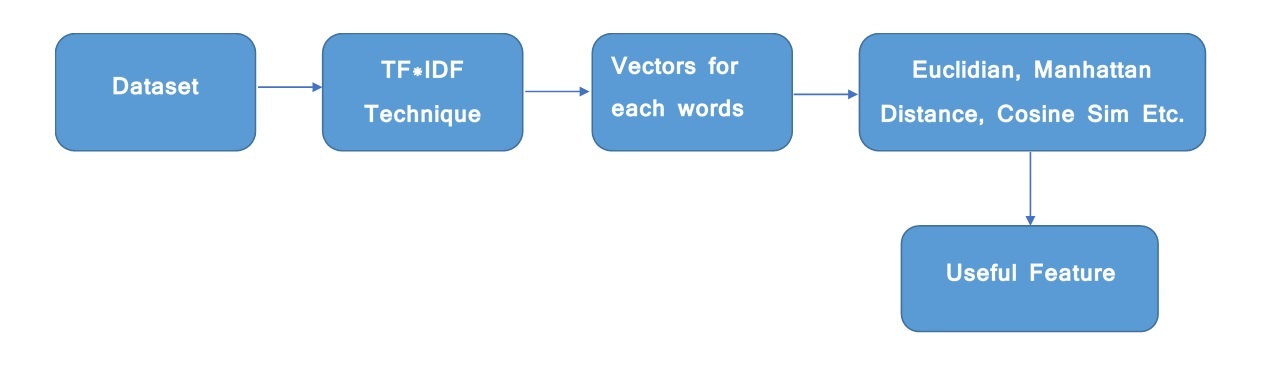
1. R语言文本分析概述
R语言作为统计分析和数据科学领域的重要工具,其在文本分析方面亦表现卓越。文本分析指的是将文本数据通过统计和机器学习算法转化为可理解的结构化信息,这对于理解大量非结构化数据至关重要。本章将简要介绍文本分析的基础知识和应用,为后续章节中使用tm包进行深入分析打下基础。
文本分析的重要性和应用场景
文本分析广泛应用于市场调查、社交媒体监控、客户服务、舆情分析等领域。它能够帮助研究人员和数据分析师从大量的文本数据中提取有用信息、洞察趋势,并做出数据驱动的决策。
文本分析的基本流程
文本分析通常包括几个主要步骤:数据收集、预处理、特征提取、模型构建和结果解释。每个步骤都需要不同的技术和方法,例如预处理可能包括去除噪声、分词和词干提取等操作。
通过本章的内容,读者将对R语言在文本分析中的作用有一个基本了解,并为接下来章节中tm包的具体应用和案例分析奠定基础。
2. tm包的基本操作
在本章节中,我们将深入探讨R语言中tm包的基础操作,tm包是一个功能强大的文本挖掘工具包,通过使用tm包,我们可以方便地执行文本数据的导入、预处理、转换等一系列操作。本章节的内容将引导读者从零开始,逐步掌握tm包进行文本分析的基本技能。
2.1 安装与加载tm包
在开始使用tm包之前,首先需要确保已成功安装tm包。tm包不是一个基础包,需要单独安装。可以通过以下R指令来安装tm包:
- install.packages("tm")
安装完成后,加载tm包以供后续操作使用:
- library(tm)
安装和加载tm包是进行文本分析的第一步。在这里,我们使用了R的基础包安装函数install.packages(),然后使用library()函数来加载安装好的tm包。
2.2 文本数据的导入与预处理
2.2.1 导入外部文本数据集
文本数据通常是存储在文件系统中的,如.txt或.csv格式的文件。tm包提供了一个函数Corpus()用于创建语料库对象,并能够从多种外部数据源导入文本数据,如:
- docs <- Corpus(VectorSource(readLines("path/to/your/textfile.txt")))
这里,VectorSource()函数将文本文件的每一行转换成一个向量,然后传递给Corpus()函数来创建一个语料库对象。
2.2.2 文本清洗与格式化
文本导入之后,下一步通常是清洗和格式化文本数据。tm包提供了许多函数来帮助我们执行这一任务,例如:
- docs <- tm_map(docs, content_transformer(tolower))
- docs <- tm_map(docs, removeNumbers)
- docs <- tm_map(docs, removePunctuation)
- docs <- tm_map(docs, removeWords, stopwords("english"))
上述代码使用tm_map()函数配合自定义函数content_transformer()来逐个转换语料库中文本数据的格式。转换包括将文本统一转为小写、去除数字、标点符号以及英文停用词。
2.3 文本数据的转换基础
2.3.1 文本向量化
文本向量化是将文本数据转换为数值数据的过程,这样便于进行统计分析和机器学习。tm包中的DocumentTermMatrix()函数可以实现这一转换:
- dtm <- DocumentTermMatrix(docs)
2.3.2 词频矩阵和文档-词条矩阵
创建词频矩阵和文档-词条矩阵是文本挖掘中的常见任务,它们可以展示文档中词条的频率分布情况。在tm包中,这可以通过inspect()函数来查看:
- inspect(dtm[1:3, 1:4])
上述代码展示了词频矩阵的前3行4列的数据。通过inspect()函数,我们可以直观地查看矩阵的具体内容。
在本章节中,我们介绍了tm包的基本安装和加载过程,说明了如何导入外部文本数据集,以及对文本数据进行基础的预处理和转换。通过上述步骤,我们可以有效地准备数据,为接下来的文本分析奠定基础。
接下来,我们将探讨tm包中更高级的文本转换技术,以及如何在实践中应用这些技术进行社交媒体文本分析和新闻内容分析。
3. tm包的高级文本转换技术
文本分析中一个重要的环节是将原始文本转换成机器学习模型能够理解和处理的形式。本章将深入探讨tm包中用于高级文本转换的技术,包括文本去噪、文本归一化、词项权重的计算、特征选择和降维。通过这些高级技术,文本数据可以被转换为数值矩阵,为后续的分析提供坚实的基础。
3.1 文本去噪与文本归一化
在文本分析的过程中,去噪和归一化是提高文本质量和可读性的关键步骤。去噪涉及去除文本中无用或冗余的部分,如停用词、标点符号等。归一化则涉及将不同形式的词语转换成一个统一的标准形式,以便于分析。
3.1.1 去除停用词与标点
去除停用词是文本处理中常用的一个步骤,停用词是那些频繁出现在文本中但通常不承载有效信息的词,如英语中的"the", “is”, "in"等。tm包提供了removeWords函数来移除指定的停用词。
- library(tm)
- # 创建一个corpus对象
- text_corpus <- Corpus(VectorSource(c("This is the first document.", "This document is the second document.")))
- # 查看原始数据
- inspect(text_corpus)
- # 停用词表
- stopwords_en <- stopwords("en")
- # 移除停用词
- text_corpus_clean <- tm_map(text_corpus, removeWords, stopwords_en)
- # 查看去除停用词后的数据
- inspect(text_corpus_clean)
removeWords函数接受一个corpus对象和一个停用词列表作为参数。它会遍历corpus中的每个文档,并移除文档中的停用词。
除了停用词,标点符号也应被去除,因为它们会干扰后续的文本分析,removePunctuation函数可以用来完成这项工作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SQL查询优化技巧:专家解读减少资源消耗的7个实用策略
【预防与故障排除】:MapGIS点属性编辑问题的全面应对方案
【技术革新】:三维元胞自动机在林火蔓延模拟中的新应用
【流程审计攻略】:APQC框架下的高效流程管理关键
【数字取证高手】:CTF中的Forensics案例 - 线索追踪与分析实践
【MT8880芯片数据手册:硬件规格解读全攻略】
零极点分析进阶指南:提升IDL编程效率的黄金法则
【iOS & Android应用下载新策略】:优化H5唤起与安装流程的秘诀
【设计模式的终极指南】:心算大师游戏架构的秘密武器
【屏幕亮度调整】:正确护眼的打开方式


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










