【栈的应用实战指南】:10个真实案例,掌握栈的应用精髓
发布时间: 2024-08-23 20:09:42 阅读量: 281 订阅数: 21 

当下实战派指南:玩转Docker配置与应用实践-markdown.zip
# 1. 栈的基本概念和数据结构
栈是一种先进后出的数据结构,它允许在数据项的末尾添加或删除元素。栈通常使用数组或链表实现,其中数组实现更为常见。
栈的数组实现中,元素存储在连续的内存位置中。栈顶指针指向栈中最后一个元素的位置。当向栈中添加元素时,栈顶指针递增,指向新元素的位置。当从栈中删除元素时,栈顶指针递减,指向栈中最后一个元素的位置。
栈的链表实现中,元素存储在链表节点中。栈顶指针指向链表中的第一个元素。当向栈中添加元素时,创建一个新的节点并将其添加到链表的开头。当从栈中删除元素时,删除链表中的第一个元素。
# 2. 栈的应用理论基础
### 2.1 栈在计算机科学中的作用
栈是一种抽象数据类型,在计算机科学中扮演着至关重要的角色。它是一种后进先出(LIFO)的数据结构,这意味着最后进入栈中的元素将首先被取出。
栈在计算机科学中的主要作用包括:
- **函数调用:**栈用于存储函数调用期间的局部变量和返回地址。当函数被调用时,它的局部变量和返回地址被压入栈中。当函数返回时,这些值被弹出栈中。
- **递归:**栈用于存储递归函数的局部变量和返回地址。当递归函数调用自身时,它的局部变量和返回地址被压入栈中。当递归函数返回时,这些值被弹出栈中。
- **回溯:**栈用于存储回溯算法的局部变量和返回地址。当回溯算法尝试不同的解决方案时,它的局部变量和返回地址被压入栈中。当回溯算法回溯到上一个解决方案时,这些值被弹出栈中。
- **语法分析:**栈用于存储语法分析器在解析输入字符串时使用的符号。当语法分析器遇到一个符号时,它将该符号压入栈中。当语法分析器完成解析时,它将栈中的符号弹出并检查它们是否与语法规则匹配。
### 2.2 栈的抽象数据类型和操作
栈可以被抽象为一个数据类型,具有以下操作:
- **push(x):**将元素 x 压入栈顶。
- **pop():**从栈顶弹出并返回元素。
- **peek():**返回栈顶元素,但不弹出它。
- **isEmpty():**检查栈是否为空。
- **size():**返回栈中元素的数量。
以下是一个使用 Java 实现的栈的示例:
```java
class Stack<T> {
private Node<T> top;
private int size;
public void push(T data) {
Node<T> newNode = new Node<>(data);
newNode.setNext(top);
top = newNode;
size++;
}
public T pop() {
if (isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
T data = top.getData();
top = top.getNext();
size--;
return data;
}
public T peek() {
if (isEmpty()) {
throw new IllegalStateException("Stack is empty");
}
return top.getData();
}
public boolean isEmpty() {
return top == null;
}
public int size() {
return size;
}
private static class Node<T> {
private T data;
private Node<T> next;
public Node(T data) {
this.data = data;
}
public T getData() {
return data;
}
public Node<T> getNext() {
return next;
}
public void setNext(Node<T> next) {
this.next = next;
}
}
}
```
# 3. 栈的实践应用
栈在计算机科学中有着广泛的应用,从算法到数据结构再到系统,它都扮演着至关重要的角色。本章节将深入探讨栈在这些领域的具体应用,帮助读者理解栈的实际价值。
### 3.1 栈在算法中的应用
栈在算法中主要用于实现递归和回溯算法。
#### 3.1.1 递归算法的实现
递归算法是一种通过自身调用自身来解决问题的算法。栈在递归算法中发挥着至关重要的作用,它存储了函数调用时的局部变量和返回地址,从而保证了函数的正确执行。
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
```
在这个阶乘计算的递归算法中,每次递归调用都会将当前的局部变量(即 `n`)和返回地址压入栈中。当递归调用结束时,栈中的信息将被依次弹出,从而恢复函数的执行环境。
#### 3.1.2 回溯算法的实现
回溯算法是一种通过试错法解决问题的算法。栈在回溯算法中用于存储当前探索的路径,当遇到死路时,栈中的信息将被弹出,从而回溯到上一个探索点。
```python
def find_path(maze):
stack = []
stack.append((0, 0)) # 起始位置
while stack:
x, y = stack.pop() # 弹出当前位置
if x == len(maze) - 1 and y == len(maze[0]) - 1:
return True # 找到出口
if maze[x][y] == 0: # 可通行
# 探索四个方向
stack.append((x + 1, y))
stack.append((x - 1, y))
stack.append((x, y + 1))
stack.append((x, y - 1))
return False # 未找到出口
```
在这个迷宫寻路回溯算法中,栈存储了当前探索的路径。当探索到死路时,栈中的信息将被弹出,从而回溯到上一个探索点。
### 3.2 栈在数据结构中的应用
栈在数据结构中主要用于括号匹配检查和表达式求值。
#### 3.2.1 括号匹配检查
括号匹配检查是确定一串括号是否正确配对的问题。栈可以有效地解决这个问题,通过将左括号压入栈中,遇到右括号时弹出栈顶元素进行匹配。
```python
def is_balanced(brackets):
stack = []
for bracket in brackets:
if bracket in "([{":
stack.append(bracket)
elif bracket in ")]}":
if not stack or stack.pop() != bracket:
return False
return not stack
```
在这个括号匹配检查算法中,栈存储了左括号的信息。遇到右括号时,栈顶元素与右括号进行匹配,如果匹配失败或栈为空,则返回 `False`。
#### 3.2.2 表达式求值
表达式求值是计算数学表达式的值的问题。栈可以有效地解决这个问题,通过将操作数压入栈中,遇到操作符时弹出栈顶两个操作数进行运算。
```python
def evaluate_postfix(expression):
stack = []
for token in expression.split():
if token.isdigit():
stack.append(int(token))
else:
op2 = stack.pop()
op1 = stack.pop()
result = eval(f"{op1} {token} {op2}")
stack.append(result)
return stack[0]
```
在这个后缀表达式求值算法中,栈存储了操作数和中间结果。遇到操作符时,栈顶两个操作数被弹出进行运算,结果压入栈中。
### 3.3 栈在系统中的应用
栈在系统中主要用于函数调用栈和虚拟机栈。
#### 3.3.1 函数调用栈
函数调用栈是一种数据结构,它存储了当前正在执行的函数及其局部变量。当一个函数被调用时,它的局部变量和返回地址将被压入栈中。当函数执行完毕时,栈顶元素将被弹出,从而恢复上一个函数的执行环境。
```mermaid
graph LR
subgraph 函数调用栈
A[函数 A] --> B[函数 B] --> C[函数 C]
end
```
#### 3.3.2 虚拟机栈
虚拟机栈是一种数据结构,它存储了虚拟机执行字节码时的局部变量和操作数。当虚拟机执行一条字节码指令时,它的操作数将被压入栈中。当指令执行完毕时,栈顶元素将被弹出,从而恢复虚拟机的执行环境。
```mermaid
graph LR
subgraph 虚拟机栈
A[操作数 A] --> B[操作数 B] --> C[局部变量 C]
end
```
# 4. 栈的进阶应用
### 4.1 栈在编译器中的应用
#### 4.1.1 词法分析和语法分析
栈在编译器的词法分析和语法分析阶段扮演着至关重要的角色。
**词法分析**
词法分析器将源代码分解为一系列标记(token)。它使用栈来跟踪当前正在处理的字符序列。当遇到一个完整的标记时,它会将其压入栈中。当栈顶的标记与预定义的语法规则匹配时,它会被弹出并替换为该规则的非终结符。
```python
# 词法分析器示例
stack = []
while input_stream:
current_char = input_stream.pop()
if current_char is whitespace:
continue
elif current_char is alpha:
stack.append(current_char)
elif current_char is digit:
stack.append(current_char)
else:
# 处理特殊字符或操作符
...
if stack[-1] is valid_token:
# 弹出标记并替换为非终结符
...
```
**语法分析**
语法分析器检查标记序列是否符合预定义的语法规则。它使用栈来跟踪当前正在处理的语法规则。当一个规则被匹配时,它会被弹出并替换为它的父规则。
```python
# 语法分析器示例
stack = []
while input_stream:
current_token = input_stream.pop()
if current_token is terminal:
stack.append(current_token)
elif current_token is non_terminal:
# 匹配语法规则
...
if rule_matches:
# 弹出标记并替换为父规则
...
```
#### 4.1.2 中间代码生成
栈在编译器的中间代码生成阶段也发挥着作用。中间代码是源代码的抽象表示,它可以被优化和转换为目标机器代码。栈用于跟踪生成中间代码所需的临时变量和表达式。
```python
# 中间代码生成器示例
stack = []
while abstract_syntax_tree:
current_node = abstract_syntax_tree.pop()
if current_node is expression:
# 生成中间代码并将其压入栈中
...
elif current_node is statement:
# 生成中间代码并将其压入栈中
...
else:
# 处理其他类型的节点
...
```
### 4.2 栈在操作系统中的应用
#### 4.2.1 进程调度
栈在进程调度中用于管理进程的执行顺序。每个进程都有自己的栈,用于存储其局部变量、参数和返回地址。当一个进程被调度执行时,它的栈会被压入栈中。当它完成执行时,它的栈会被弹出。
```python
# 进程调度器示例
stack = []
while processes:
current_process = processes.pop()
stack.append(current_process)
# 执行当前进程
...
stack.pop()
```
#### 4.2.2 内存管理
栈在内存管理中用于管理动态分配的内存。当一个进程需要分配内存时,它会从栈中分配一个块。当它不再需要该内存时,它会将其释放回栈中。
```python
# 内存管理器示例
stack = []
while memory_requests:
current_request = memory_requests.pop()
if current_request is allocate:
# 从栈中分配内存
...
elif current_request is deallocate:
# 将内存释放回栈中
...
```
# 5.1 栈空间的管理和优化
栈空间的管理和优化对于保证栈的稳定性和性能至关重要。以下介绍了两种常见的栈空间管理和优化技术:
### 5.1.1 栈帧大小的调整
栈帧是栈中存储函数调用信息的数据结构。栈帧的大小决定了栈中为每个函数调用分配的空间量。过大的栈帧会浪费栈空间,而过小的栈帧则可能导致栈溢出。
为了优化栈帧大小,可以采用以下策略:
- **分析函数调用模式:**确定函数调用中使用的局部变量和参数的数量,并根据实际需要调整栈帧大小。
- **使用可变大小栈帧:**对于调用模式不固定的函数,可以使用可变大小栈帧,根据函数调用的实际需要动态分配栈空间。
- **使用寄存器优化:**将频繁使用的局部变量存储在寄存器中,减少对栈空间的访问。
### 5.1.2 栈溢出和栈下溢的处理
栈溢出和栈下溢是栈空间管理中常见的错误。栈溢出是指栈空间不足,导致程序崩溃。栈下溢是指栈指针指向栈的低地址,导致程序访问无效内存。
为了处理栈溢出和栈下溢,可以采用以下策略:
- **设置栈大小限制:**为栈设置一个最大大小限制,防止栈溢出。
- **使用栈保护机制:**在栈的底部和顶部设置保护区域,当栈指针接近这些区域时触发异常。
- **使用栈增长策略:**当栈空间不足时,动态增加栈空间,防止栈溢出。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了栈的数据结构,涵盖了从概念到实践的全面内容。它提供了 10 个真实案例,展示了栈在实际应用中的强大功能。专栏还揭秘了栈的本质和操作,并比较了数组栈和链表栈的底层实现。此外,它深入解析了栈在函数调用、表达式求值、递归算法、浏览器历史记录管理和编译器语法分析等场景中的应用。专栏还提供了栈的常见问题和解决方案,深入探讨了栈的内存管理和并行化原理。最后,它总结了栈开发和应用中的最佳实践,为读者提供了全面的栈知识和实用指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
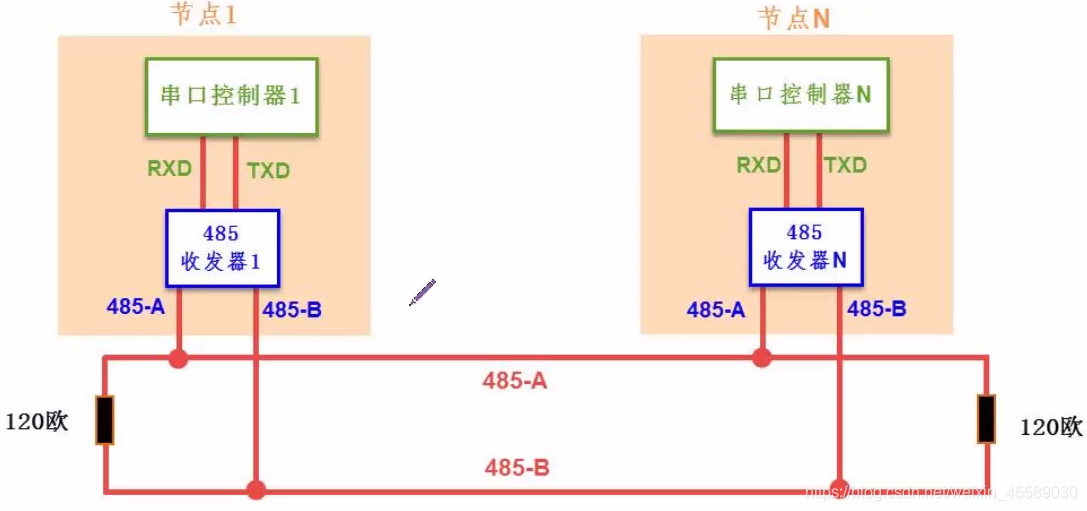
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )